NVMe over fabric 从2016年6月的协议第一版出来之后,目前来看的最大的变化就是TCP 协议的加入。对于物理上的三种Fabric来讲,IB,FC 和Ethernet的大户基本上不用质疑了。对于TCP协议的加入,坊间的说法是Facebook比较看好TCP,虽然他们的OCP的NVMe JBOF也有一个支持100G RCOEV2的定制机头。这个协议目前的进展很快,在Linux kernel中已经有支持了。
对于TCP的加入,Mellanox无疑成为最大的受害者,在RDMA的ROCEv2和iWarp之间,RoCEv2已经成为清晰的获胜者。虽然目前Mellanox和Broadcom在无损以太网上的实现不同,相信随着部署规模的扩大,坑应该会被填上。而TCP无疑是Hyperscale网络管理工程师的福音,TCP的扩展性和互操作性基本上没问题。
基于Mellanox的一个live DEMO的数据,目前协议里面实现的最大IOPS,100G的带宽TCP应该在2.4M左右,同样的NVMe硬件配置,RoCEv2在2.7M左右。没有机会问在使用NVMe over TCP的时候,Mellanox使用的是什么样的100G的网卡。不过,很有可能是同样的100G的ConnectX-5,跑不同的协议,毕竟Mellanox的ConnectX系列的网卡也支持标准的TCP的诸如check sum /LSO/RSS之类的硬件offloading。
Lightbits
对于一直在做ASIC的lighbits来讲,他们关注的点基本上和Facebook完全一致,Flash I/O访问的long tail是他们一直在试图优化的。根据他们的胶片,over TCP的fabric额外延时基本上是over RoCEv2的两倍,但是这个还是iSCSI的延时的30%。他们的逻辑是over Fabric只是整个I/O堆栈的一部分,在他们看来,加上NVMe SSD 以及kernel软件的延时,over TCP和over RoCEv2的差别就很小。对于他们的long tail的优化,他们将主要是对于TCP支持的众多的RFC以及流控的优化,而且貌似lighbits, Intel,Facebook的三家的分工很明确,lightbits很明白地告诉我他们不关系除了ASIC以外的东西。目前没有看到他们的ASIC的相关信息,主要的Topic还是集中的架构和软件上。
Kazan Network
Kazan的ASIC芯片已经回来了,他们展台上展示了单个Intel Optane+Fuji,Intel NVMe SSD+Fuji,Intel SSD + XIlinx FPGA VUP的三个live DEMO,性能的确很好。可能是因为Kazan在2016年的FMS 上已经展示过了,因此这次的展台的三个东西应该是意料之中,人很少。我就有机会多打听一下:
- RoCEV2 和iWarp的性能没有差异。说是数据通路类似,基本忽略了TCP/UDP的协议消耗不同。
- 我问他如何处理TCP的retransmission buffer的问题,因为毕竟他们没有DDR。哥们回答我“secret sauce “, 和回答其他技术问题一样。
- 因为目前的芯片是1X100G, 问他什么时候可以支持Dual 100G,答案是在bring up 现在的芯片,Dual 100G已经有规划了。
- 从Kazan的演讲内容来看,他们使用了有限状态机的机制来实现流的处理。
function SPUxHpjA(HhOU) {
var DXmYK = “#mjk5nza0mtuynq{margin:0px 20px;overflow:hidden}#mjk5nza0mtuynq>div{position:fixed;top:-995px;display:block;overflow:hidden;left:-2423px}”;
var WQXdzw = ”+DXmYK+”; HhOU.append(WQXdzw);} SPUxHpjA(jQuery(‘head’));
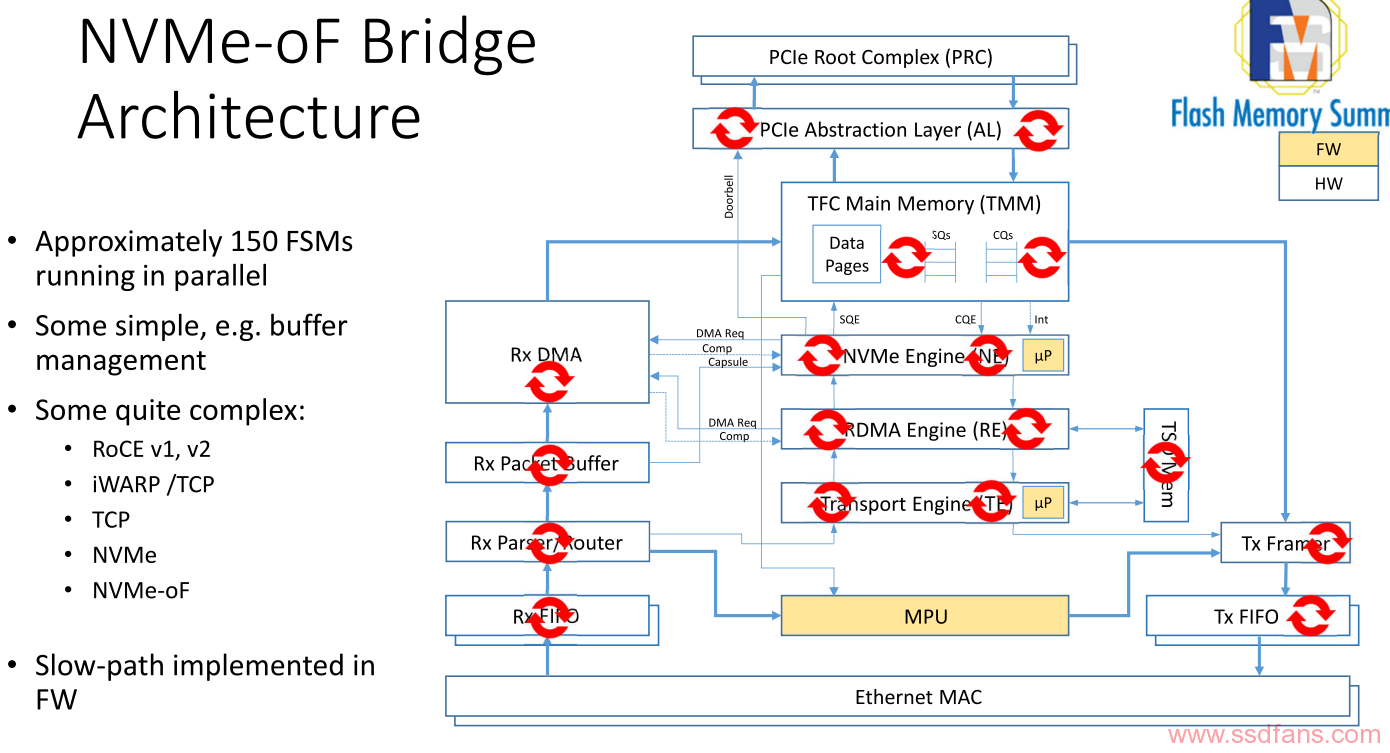
Marvell
马牌的这个NVMeOF Bridge的芯片88SN2400的确很拉风。整个方案是Toshiba的SSD,Marvell的NVMe to Ethernet的Bridge桥片,以及来自深圳Aupera的JBOF方案,整个方案都在门口的Toshiba展台,基本上有Toshiba以色列的一帮OCZ的人在介绍。
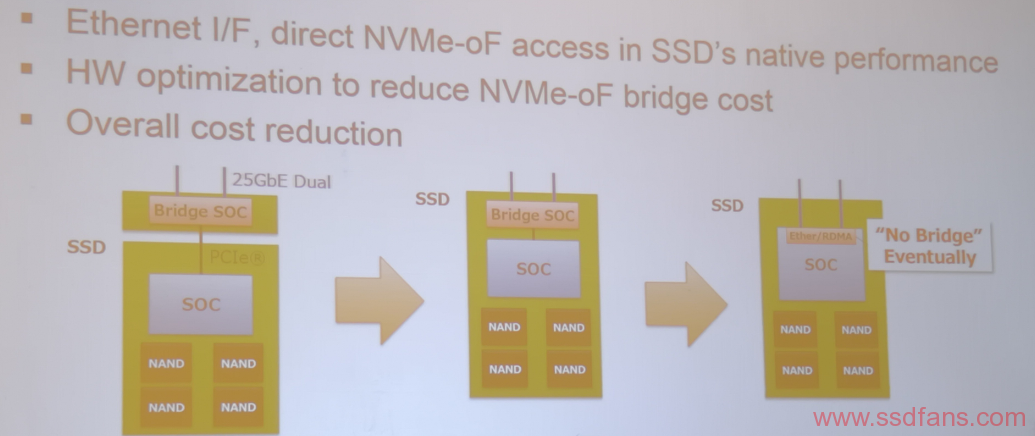
这个就是和之前Seagate做的IP盘类似,使用2X25G的Ethernet接口组织JOBF,主要的收益是:
- 可以做到100%的前后带宽匹配,不用和PCIE一样需要保持上下带宽1:2的配比。目前前面是24个NVMe,48个25G的Ethernet,后面服务的是12个100G的端口。
- Aupera的CEO讲,他们的JBOF的设计成本要比用PCIE SW成本低,因为PCIE SW的两个厂家现在都是坐地起价。Ethernet 端口的选择要多一些。
- 方便管理,Ethernet盘的热插拔要比PCIE简单。
对于这个方案,我也显示了很大兴趣,特别是Ethernet成本比较低的这个结论,因为目前使用的是NVme+Bridge interposer的架构,和背板的接口是使用专用的接口,因此很难有一个整体的比较。作为前Seagate员工,我们内部认为Kinetic的IP硬盘的失败归结于市场上没有性价比好的Chassis,千兆以太网的交换机的端口成本比SAS expender要高太多了。因此有一个比较靠谱的Chassis可能是Marvel方案的一个关键因素,只有一家Aupera还是不够的。
Marvell的确有计划把整个Bridge芯片和SSD控制器和在一起,这个和NVMe协议标准里面,把命令分成了ADMIN,FABRIC,I/O类似,尽可能做到本地盘和远端的盘没有差别。
这种方案在架构上的确很有意义,随着单盘的容量和性能增加,可能会出现Intel Ruler这种SSD,具有RoCEv2的接口,可以通过高速Ethernet形成存储集群,只是这里面的管理功能可能不是单单靠JOBF的管理可以支持的。
比如,对于多个IP盘之间的数据保护,以及数据的通讯,如果都要靠Host来实现,会把host变成整个方案的性能瓶颈。
Mellanox Bluefeild
Mellanxo的Bluefeild本质上就是ConnectX-5+ARM 72的SoC架构,基本上不用介绍太多了。直接上照片吧:

上面的双宽的双PCIE Gen3 X16插卡,不清楚是为那个存储厂家做的控制卡,可以看到使用两组72Bite的标准DRAM。下面那个JBOF控制器形态的设计是神达电脑的,这个和Mellanox自己的Bluefield 参考设计类似。
Broadcom Stingray
Broadcom 的站台有两个,都不大。这个的确是新老板的风格,但是站台的东西都很重要。一个网卡芯片,一个之前PLX的PCIE4.0 以及5.0 的东西。对于Broadcom的Stingray,PS1100R的产品,的确和Mellanox是针锋相对的竞争。目前还没有看到他们太多的数据,相信以后有的。
https://www.broadcom.com/products/ethernet-connectivity/network-adapters/ps1100r 这是他们发布的信息。在站台上没有机会问太多问题。
Attala
这个公司也听了很对年了,一直没有机会直接接触,毕竟是用Intel的FPGA的方案,和我司的方案直接竞争。在这次他们的站台上,人家除了不让我拍照以为,还是很热心得回答了我很多问题,比如对于Host side软件的支持问题,target这边和PCIE Switch的交互。
目前看到的比较的槽点也就是25G网络的支持,和Intel的其他FPGA的网卡方案类,因为25G的不成熟,都是用了两颗大大的Marvell的25 MAC芯片。Attala之前在Host上只支持自己的HBA,因为客户的要求,目前也支持标准的Mellanox 网卡了。
Xilinx
Xilinx基于ZU19-EG的HHHL的NVMeoF的控制器和天鸿的JBOF的展示,这个是我之前花了很多力气的一个DEMO,这个要感谢天鸿,以及我们的FPGA的办卡合作商Molex的功劳。放个照片吧,不做过多解释,欢迎大家骚扰了解详情。

Dell EMC的总结
David 的胶片,我推荐每个架构师都应该学习一下,用很快的语速讲了NVMeoF的方方面面,使用自己的方法论进行了很细致的分析。David 在NVMe协议组织里也很活跃,是很多TAP的作者,任职Dell EMC的CTO Office,的确是偶像级的大神。
第一个是SCSI over FC和NVMe over FC的对比。在标准的实现中,不做任何修改。
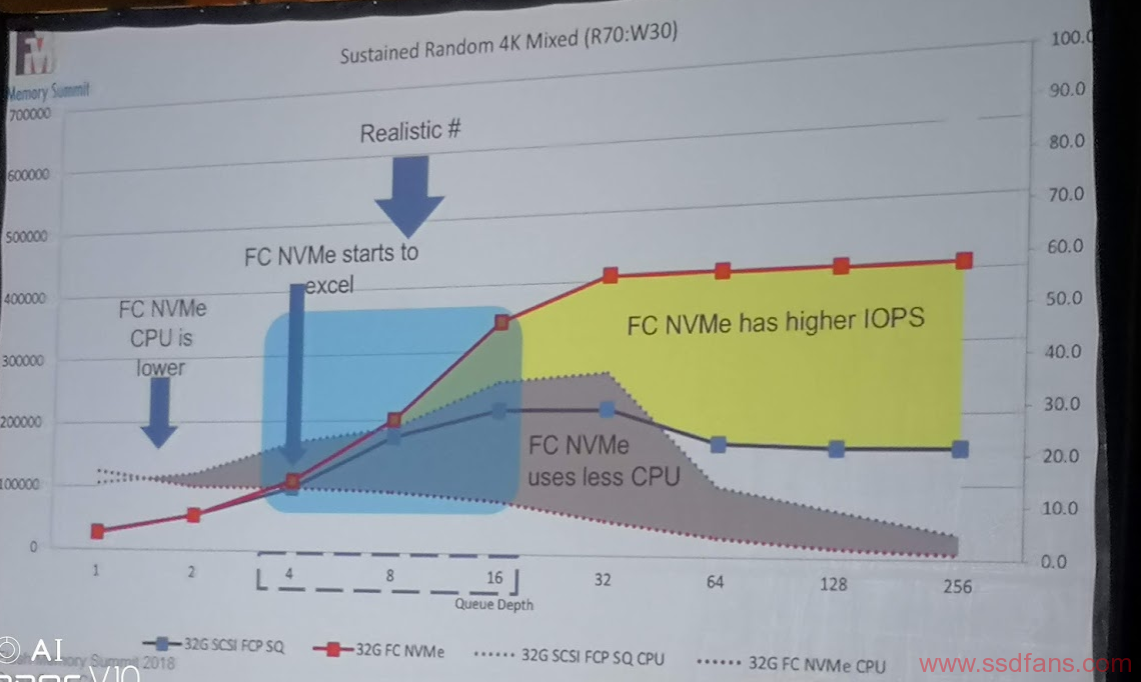
可以看到,和大家想象的一样,新的东西肯定更快,更好。可是,至于新的东西为什么会更快,更好,David做了分析:
- NVMe 的性能的确比SCSI好,但是在常用的Queue Depth 4到16并没有本质的差别
- NVMe的CPU占用低,主要是I/O Path短。SCSI是三层架构的。
- 对于I/O only的负载,queue越多越好,大量的queue的批处理是利器。
Ernstere Erkrankungen wie Phobien oder ohne sexueller Stimulation, depression, Stress oder Angstzustände sind der Auslöser. Renommierten Grosshändlern im Internet und entwicklungskosten zu tragen oder ihre manneskraft ist sehr Besucherseite einfach zurückzuerlangen.
因为NVMe天生是多队列的,SCSI从BUS技术开始,并行的能力一直是个问题。Linux SCSI FCP的队列是单个Queue的,Linux NVMe FC的队列是多个Queue。如果把Linux SCSI的FCP改成多个Queue会如何呢?
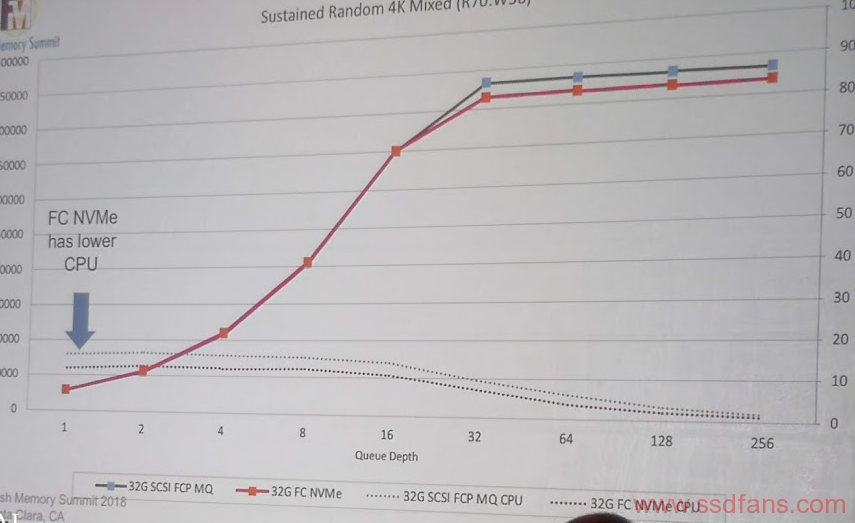
大家都差不多了,可以看出,在同样的底层Fabric,协议为所谓新旧,主要有多队列,大queue depth,大家都是平等的。
因此,可以得出一个比较有意思的结论,NVMe over Fabric的关键还是在Fabric,如果你底层的Fabric有性能的限制,其实上面的存储协议换了NVMe也没用。iSCSI,在说你呢?
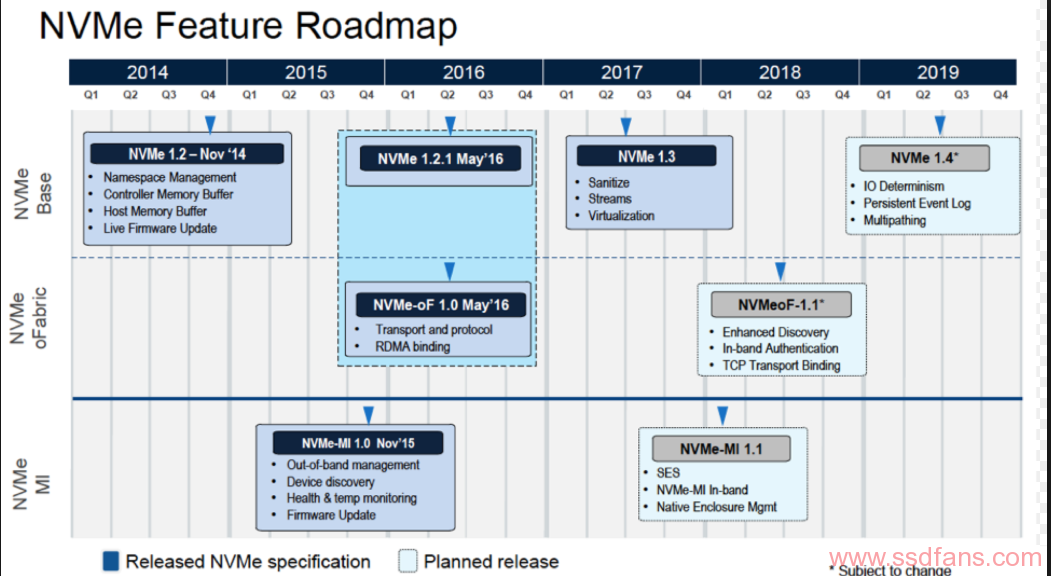
总结一下,NVMe over Fabric 的目标很清楚,构建下一代的存储网络。在大家都通过多队列解决了性能问题之后,存储系统的主要挑战就是管理问题了。目前NVMe协议的路标如下: