Physical Page Address I/O Interface
为OpenSSD提供的一个接口叫做物理页面地址Physical Page Address I/O接口,它是基于分层的地址空间。它定义了administration commands 来暴露了设备的几何结构,并允许host控制SSD的管理,还定义了data commands以有效地存储和检索数据。接口与嵌入在Open-channel SSD上的非易失性介质芯片的类型无关。
这个接口的实现是作为NVM Express 1.2.1规范的供应商特定的扩展,该标准定义了PCIe连接的SSD的优化接口。
这个接口主要特征如下:
通过这个接口暴露SSD的几何结构
- 逻辑/物理几何结构(取决于供应商)
- 性能
- 特定介质的元数据(需要的情况下)
- 控制器功能
展示分层的地址空间
- 编码几何结构(PUs)到物理空间
向量I/Os
- 读/写/擦除(有效访问给定的新的地址空间)
Address Space地址空间
依靠两个不变量来定义PPA的地址空间
- SSD架构
Open-channel SSD 公开给host的是一组channels, 每个channel 包含的一组Parallel Units(PUs)也叫做LUNs。定义PU是在设备上的并行单位。一个PU可以覆盖一个或多个物理die,并且一个die只能是一个PU的成员。每个PU一次处理一个I / O请求。
- 介质架构
无论使用哪种介质,每个PU上的存储空间都是量化的。NAND 闪存芯片分解为blocks,pages(转换的最小单元)sectors(ECC的最小单元)。字节可寻址存储器可以组织为sectors的平坦空间。
控制器可以选择PU的物理表示形式,这样,控制器可以在PU级别公开性能模型,该模型反映基础存储介质的性能。
如果控制器为PU选择逻辑定义(例如,通过RAID访问多个Nand dies),那么PU的性能模型必须基于存储介质的特性和控制器功能来构建(例如,XOR引擎加速)。逻辑表示对于按字节寻址存储器可能是有益的,在该存储器中,多个die组合在一起形成一个sector。在这里,假设一个PU对应单个物理NAND die。通过这样的物理PU定义,控制器将公开一个简单的,易于理解的介质性能模型。
PPA为一个分解的层次结构,可反映SSD和介质架构。例如,NAND闪存的层次结构为plane,block,page和sector,而字节可寻址存储器(例如PCM)是sector的集合。尽管SSD架构中的组件,channel和PU都存在在PPA地址中,但是介质架构的组件可以被抽象化。如图所示:
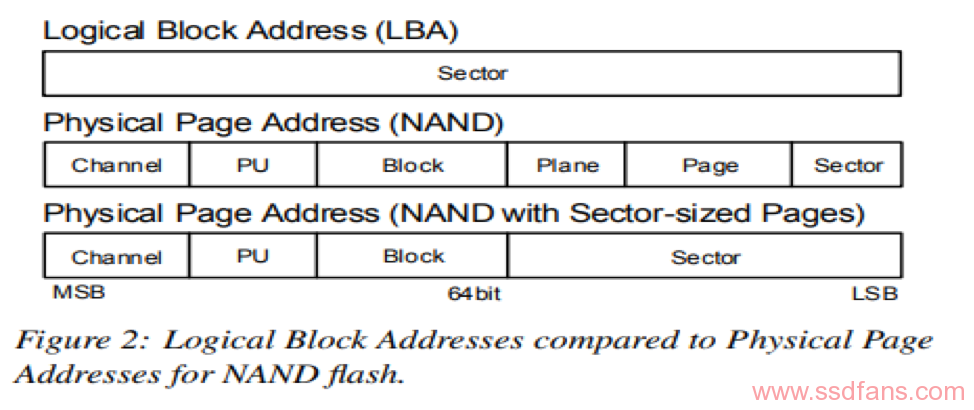
每个设备都为PPA定义其位阵列命名法,地址在64位地址范围内。换句话说,PPA格式不对每个设备上的最大channel数或每个PU上的最大块数约束。由每个设备来定义这些限制,并可能忽略某些特定介质的组件。这种灵活性是PPA格式与为早期硬盘驱动器引入的分层CHS(Cylinder-Head-Sector)格式之间的主要区别。
将SSD和介质架构编码为物理地址可以定义硬件单元,嵌入在开放通道SSD上,可映射传入输入/输出到适当的物理位置。
在地址空间中编码SSD和介质架构为物理地址(Encode Geometry in Address Space)
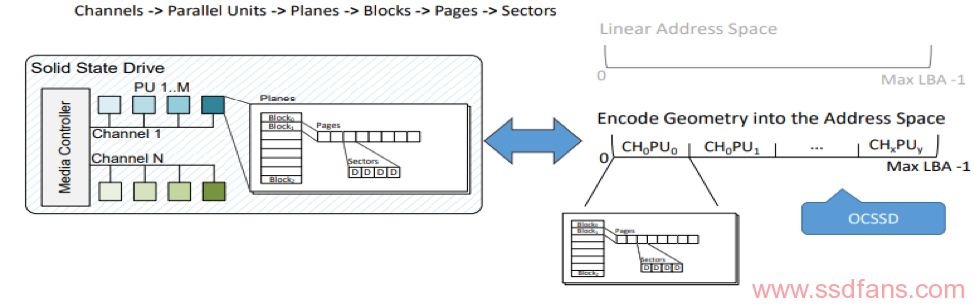
PPA地址空间可以按逻辑组织为充当传统的逻辑块地址(LBA),比如Nand阵列使用:“block, page,plane,sector”。这使PPA地址空间可以通过传统的读/写/修剪命令暴漏出来。与传统的块I/O相比,I/O必须遵循某些规则:在一个块内,写入必须按顺序进行;可以针对整个块发出Trim,以便设备将命令视为擦除命令。单个读取是否可以跨越单个I/O中的多个块是特定实现的。
把SSD和介质架构编码成物理地址,使定义嵌入在open-channel SSD中的硬件单元成为可能,这些硬件单元将传入的I / O映射到其适当的物理位置。PPA格式也非常适合表示,标识符是2的幂自变量。这样,这样,通过移位可以有效地实现对name-space(例如,在下一个channel上获取下一个page,或者在不同的PU上获取下一个page)的操作。
PPA地址空间可以进行逻辑组织以充当传统逻辑块地址(LBA)比如,排列NAND闪存通过使用“block, page, plane, sector”。这使PPA地址空间可以通过传统的读/写/修剪命令被公开。与传统的块I/O相比,I/O必须遵循某些规则。
- 必须在一个块内按顺序发出写操作。
- 可以针对整个块发出Trim,以便设备将命令解释为擦除。
- 单个读取是否可以跨越单个I/O中的多个块是特定实现的。
与传统的线性LBA空间相比,PPA地址空间可能包含无效的地址,不接受I/O。考虑例如每个PU有1067个可用块,那么它将由11 bits表示。 块 0-1066将是有效的,而块1067-2047将是无效的。在这种情况下,由控制器决定是否返回错误。 如果层次结构中每个级别的介质配置都不是2的幂,则在地址空间中将存在此类漏洞。
Geometry and Management 几何与管理
让host 控制对SSD的管理,一个open-channel SSD 必须暴露四种特性:
- 几何结构
例如,PPA地址空间的尺寸。有多少channels? 在1个channel上有多少PUs? 在一个plane上有多少blocks? 在一个block上有多少pages? 在一个page上有多少sectors? 每一个page上out-of-bound区域有多大? 将一组物理LUN公开为一个逻辑或单独公开。
我们假设对于给定的地址空间PPA尺寸是统一的。 如果SSD包含不同类型的存储芯片,则SSD必须将存储作为单独的地址空间公开,每个地址空间均基于相似的芯片。
- 性能
介质访问时间(读/写/擦除)
例如,捕获数据命令性能,channel容量和控制器开销的统计信息。规范的当前版本捕获了页面读取,页面写入和擦除命令的典型延迟和最大延迟,以及擦除命令以及寻址到channel内单独的PU的运行中命令的最大数量。
- Media-specific metadata
例如,特定于NAND闪存的元数据包括设备上的NAND闪存的类型,是否支持multi-plane操作,用户可访问的out-of-bound区域的大小或MLC和TLC芯片的页面配对信息。随着介质的发展以及变得越来越复杂,让SSD处理这种复杂性可能会比较有利。
- Controller functionalities
设备端介质缓冲还是主机端介质缓冲
控制器可能支持写缓冲,故障处理或配置。所有这些功能都可以配置(例如,跨PU的RAID)。 如果控制器支持写缓冲,则刷新命令使host能够强制控制器将其缓冲区的内容写入存储介质。
Read/Write/Erase
数据命令直接反映NAND闪存单元读,写和擦除的接口。 对于不支持该命令的介质,将忽略该命令。
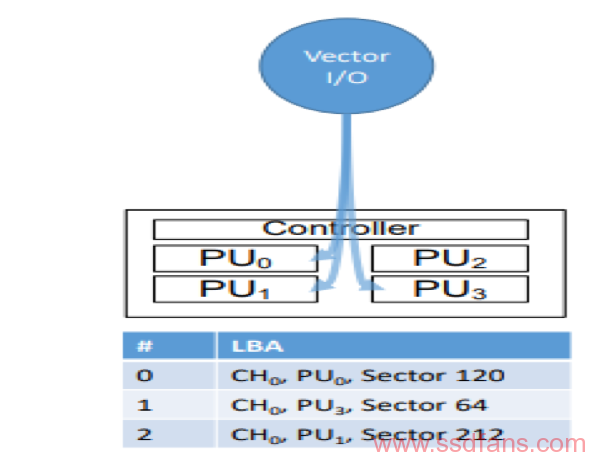
Vectored I/Os
数据命令扩展了传统的LBA访问, 读或写命令不再由LBA的起始,一些要访问的扇区和一个数据缓冲区定义。取而代之的是,将读取或写入应用于地址向量,以利用SSD的固有并行性。例如,让我们考虑64KB的应用程序数据。 假设页面大小为4KB,可以使用同时应用于16个扇区的写命令对数据进行条带化,从而有效地支持分散访问。
具体而言,每个I/O均表示为NVMe I/O读/写命令。用单个PPA地址或指向地址列表的指针,表示为PPA列表,替换起始LBA(SLBA)字段。PPA列表包含了一个要被访问的sector的LBA。同样,利用NVMe I/O元数据字段来执行带外元数据。 元数据字段通常用于端到端数据一致性。
数据命令完成后,PPA接口将为每个地址返回单独的完成状态,这样,主机可以区分并从不同地址的故障中恢复。对于规范的第一次迭代,NVMe I/O命令完成入口的前64位用于表示完成状态,这会将PPA列表中的地址数限制为64。
考虑PPA列表的替代方法。 实际上,评估了三种方法:
- NVME I/O commands
一个NVME I/O command以串行方式发出命令。 页缓冲区满时,会将其刷新到介质。 每个命令都会敲响控制器的门铃以通知新的提交。
- Grouped I/O commands
对于Grouped I/O commands,几页构成一个提交,门铃只响一次,但是由控制器来维护每个提交的状态。
- Vectored I/Os
对于Vectored I/Os需要一个额外的DMA来传达PPA列表。 我们选择第三个选项,因为额外的DMA映射的成本通过简化的控制器设计得以补偿。
- 通过PUs获得更高的吞吐量
- 如果单独发出I/Os,则开销很大
- 引入Vectored I/Os接口,使主机可以使用一个命令将I/O提交给多个PU
使用分散/聚集进行vector 地址列表读/写/擦除
介质标准
每个I/O命令都提供特定于介质的提示,包括plane操作模式(单,双或四平面),擦除/编程挂起以及有限的重试。plane操作模式定义一次应编程多少个平面。 由于默认情况下控制器顺序访问PU,因此控制器可以使用plane操作模式提示来高效地并行编程平面。同样,擦除挂起允许读取挂起活动的写或程序,从而以更长的写和擦除时间为代价来改善其访问延迟。有限的重试允许主机让控制器知道它不应该穷尽所有选项来读取或写入数据,而是如果其他地方已经有数据可用,则会快速失败以提供更好的服务质量。
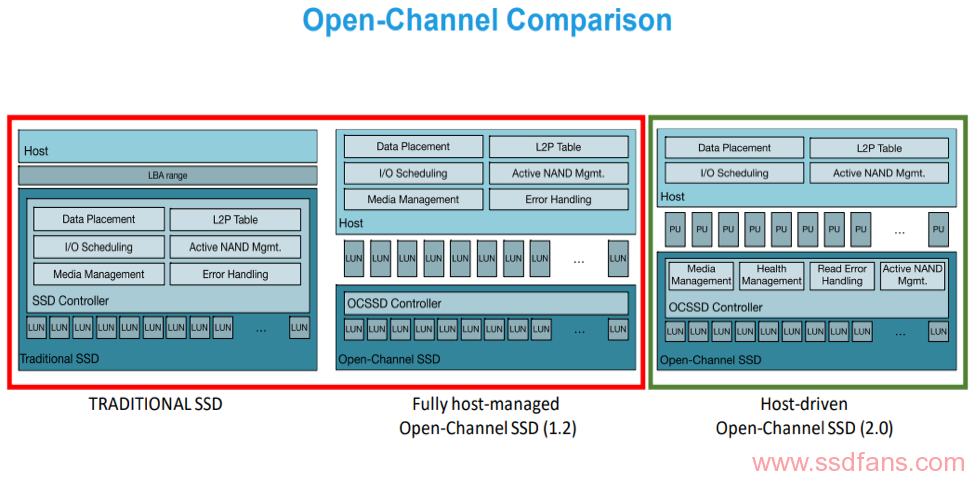
可用的两种规格的open-channel SSD
- Open-Channel SSD 1.2 (Support in Linux Kernel 4.4 through LightNVM)
- Open-Channel SSD 2.0 (Support in Linux Kernel 4.17 through LightNVM)
- Alibaba’s Dual-Mode SSD
现在,4.19版本更加好
关于Open-channel SSD 2.0
几何结构:
- Logical Block: 读取的最小可寻址单元
- Chunk: 一组连续的Logical Blocks,复位(擦除)的最小可寻址单元
- PU: 必须序列化访问的Chunks的集合。 通常,设备依靠数十/数百个这些PUs
- Group: 共享设备上相同传输总线的PU的集合
访问open-channel SSD
- 和传统SSD不同的是
- Geometry
- 呈现一组块(chunks/zones)
- Timings
- Reads
- Sector-sized reads
- Bonus : Vector接口定义了额外的错误代码,例如读取未写的页面,并提示页面是否具有较高的ECC
- Geometry
- Writes
- 要求:在chunk内顺序写入
- 会失败:错误并不表示盘损坏,而是存在特定的写入单元是坏的。
- 将数据写入chunk中的下一页(或根据错误代码跳过块)
- Erase
- 会失败:错误并不表示盘损坏。 只是意味着该块已损坏,应该将数据重写到新页面。
在Open-Channel SSD 2.0中:
主机端软件与介质无关
- 通过通用几何抽象的介质
- 磨损水平指标和阈值
通过反馈回路的介质特定动作
- 刷新数据
新一代NAND只需要在每一代SSD上集成特定于介质的更改
与主机的接口保持不变
Open-Channel SSD 2.0功能:
- 识别:暴露SSD的几何形状
- 并行性:块中的通道数,LUN数,Chunks数,和Chunk中 LBA的数量
- 介质计时–读取,写入和擦除。
- 写要求–最小化写大小和最佳写大小
- I / O提交:更丰富的I / O接口
- 使用分散/聚集地址列表支持Vector I / O(R / W / E)
- 支持NVMe读写语义(分区的设备)
- 连续访问-没有维护窗扣
- Host/SSD 通信 :丰富的管理接口
- 通过“Report Chunk ”命令获取状态(获取日志页面)
- LBA起始地址
- 写指针(主机保证在块内顺序写)
- 块状态(Free, Open, Full, Bad)
- 磨损指数
- 使用” NVMe AER” 灵活NAND管理反馈回路
- 驱动器告诉主机在必要时重写块
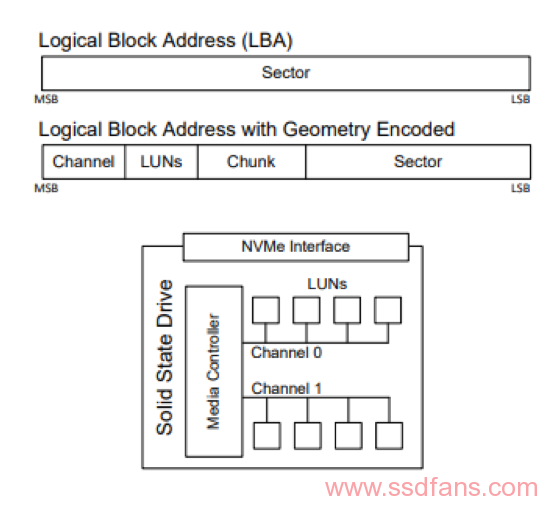
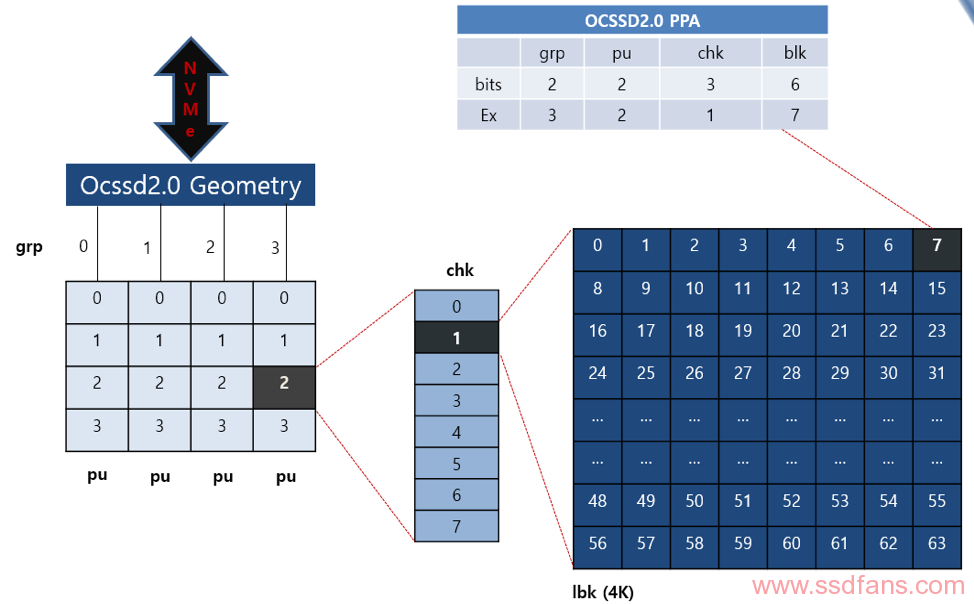
Open channel SSD2.0 PPA接口暴漏出存储介质可以用下图来理解:

在PPA,可以由相应的bit数解码出关于Groups数,PU数,Chunk数,Logical Block 数。
参照下图: