提要
上次ssdfans群里有人说三星有一款SSD,貌似是850主控使用了去重技术,阿呆难以置信,因为去重不仅有复杂的计算,还要维护一个LBA到哈希值的映射表,占用内存,增加延迟。不过,最近看到一篇韩国学者写的论文,讲的是SSD去重,所以简单介绍给大家看看。
我们先来看看传统的去重是怎么实现的,就以我们曾经介绍过的EMC XtremIO全闪存阵列
为例。XIO专门为去重维护了两张表,A2H(数据块逻辑地址——Hash值)和H2P(Hash值——SSD存放地址)。每个4KB数据块都会计算出一个SHA-1值作为指纹,以此来判断数据是不是重复,而不是直接比对数据。加上SSD内部的FTL映射表,需要占用很大的内存,SHA-1计算也消耗CPU资源。显然,SSD内部不可能做到这么强大,所以我们来看看聪明的韩国工程师想出了什么办法。
背景介绍
以前阿呆读研究生的时候,学术大牛告诉我看论文最重要的就是introduction,这个东东看完,基本就知道了研究的来龙去脉和背景,如果introduction写得好,论文质量基本没问题。所以我们来看看这篇论文《Deduplication in SSDs: Model and Quantitative Analysis》的摘要和简介。
SSD去重有三大好处:
-
延长寿命,因为数据量少了;
-
提升写性能,也是写的数据量少了;
-
垃圾回收快:搬的数据少了。
也有一些天然的便利条件:
-
SSD内部有个映射表FTL,所以去重可以直接用这个映射表,而不会增加新的映射表成本
-
省下来的空间就是Over Provisioning了,空余空间越大,垃圾回收要搬移的数据就越少,速度越快
-
写的数据少了,垃圾回收的写也少了,SSD的擦除次数就少了,寿命延长了。和生物一个道理啊,鳄鱼,乌龟,蟾蜍这些不怎么动的动物就是活得久。
好处说了这么多,再来说说不利的形势:
-
嵌入式环境太寒酸:一般是ARM嵌入式CPU,配一点点内存
-
运气背,写下来的全是不可去重数据就惨了,或者重复率很低也得不偿失
这篇论文使用了两种技术:采样过滤(软件实现,挺神秘的,往下看看就知道内容了)和指纹管理(其实就是硬件算Hash),实验结果是去重率在4%-51%,平均17%,写速度平均提升了15%,SSD寿命平均延长了2.4倍!(这是真的吗?)听起来牛逼烘烘的,让我们来一探究竟。
去重架构
经过对SSD数据的初步分析,作者得出一个惊人的结论:SSD内的重复数据往往写入时间也是相近的,所以维护一个小的Hash查找表就可以。同时把传统1:1的映射表改成了N:1,其中N就是重复的那些数据咯。最后在ARM7的OpenSSD开发板上实现了框架,同时Xilinx Virtex6 FPGA实现硬件去重计算,ARM9 EZ-X开发板实现软件去重。
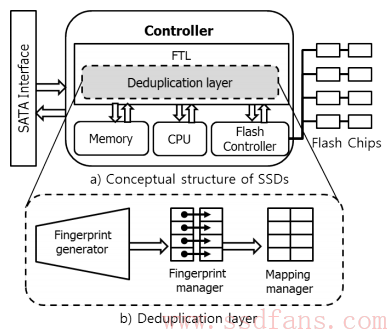
如上图的b为去重模块,分为三部分:
指纹生成器:计算Hash值
首先是指纹计算的数据块是多大?考虑到SSD写入的数据大部分都是4KB为单位,所以采用4KB作为数据块大小。
其次是HASH算法用什么?SHA-1和MD5都比较常用,能保持非常好的唯一性,最终选择了SHA-1,每个4KB数据产生160位HASH值。
指纹管理器:读写指纹
需要考虑的主要问题是指纹查找表得多大?一般去重设计会维护一个完整的查找表,但SSD内部资源有限,OpenSSD只有64MB内存,还放了映射表和其他元数据。那怎么办?经过分析数据,发现重复数据在时间上很接近,所以只在内存中维护最近数据的指纹查找表。
指纹映射表:指纹到物理地址的映射
SSD攻城狮在《戏说FTL》中讲过,FTL中的映射表分为page映射,block映射和混合映射。因为去重使用了4KB数据块,所以这里采用page级映射。流程图下图,进来的数据[10, A]表示LBA 10的内容为A,计算出HASH值,A’,保存到物理地址100.看起来这里有两张表了:
-
指纹映射表:A’— 物理地址100
-
FTL映射表内容就是LBA 10 — 物理地址100
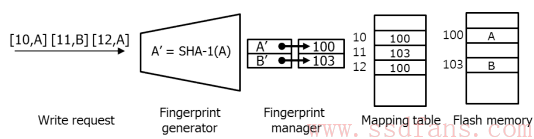
最后一笔写[12, A]发现指纹有重复,就不写了,只更新了一下FTL映射表。不过在垃圾回收的时候这样做会有大麻烦,后面详述。
去重理论模型
如果你对理论没什么兴趣,可以直接跳到下一段。不过,还是建议你看看,因为所谓的理论其实就是四则运算而已。对于一般的SSD,写延迟包括映射表查询时间+Flash Program时间,计算如下

但是对于加了去重的SSD,写延迟就变成了有重复和没重复两种情况的平均值:

为了让去重能起到效果,就得要求公式2比公式1大,这样化简一下,得到公式3:
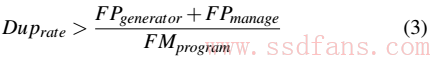
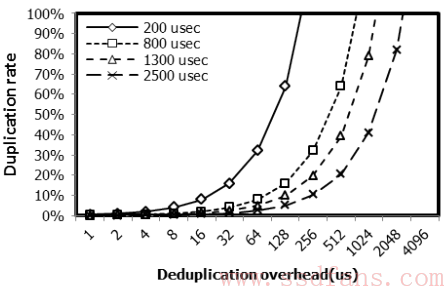
这就是数据重复率的要求。这里面没有考虑垃圾回收,为什么?因为去重后要搬移的数据更少,垃圾回收带来的延迟肯定比以前更短,所以不予考虑。从公式3可以得出指纹生成和查询的时间与数据重复率的关系曲线,如下图。分别是四种Flash Program时间的曲线,明显,数据重复率和去重计算时间呈指数关系,这就要求我们要尽可能缩短去重带来的延迟。
去重计算
硬件方案
为什么要用硬件来算SHA?可以看看下面这张图,在不同CPU上计算SHA需要的时间,可以看出最行的Microblaze需要6ms,最短的ARM9需要813us,都不可能商用。而硬件只需要80us。
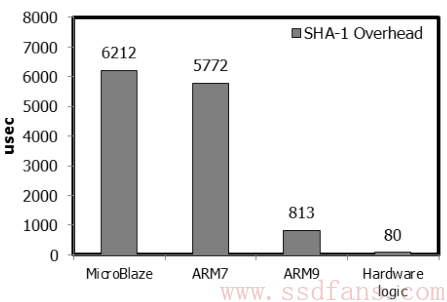
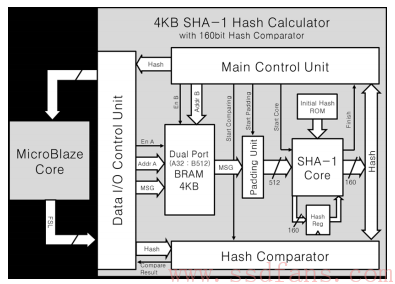
如下是FPGA里的硬件计算架构。4KB放数据,SHA-1 Core做计算,下面的Hash Comparator是做HASH值比较的。硬件计算时间80us,假如Flash Program时间1300us,那么数据重复率至少要有5%。如果能流水线处理HASH计算和Flash Program,映射表管理等,还可以更高效。
软件方案
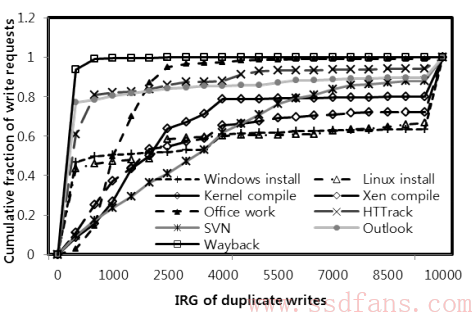
出方案之前,我们先来看一个统计。这个图是对各种典型应用写重复时间间隔的一个统计,横轴表示写了多少次才出现重复,纵轴表示在这个次数出现的重复案例在所有重复事件中的比例。可以看出来,绝大部分应用中,当你写了一个数据,如果还会再写一篇,那么它的重复写在4000次写内就出现了,之后就极少出现。基于这个现象就可以开发软件去重算法。
这个软件算法设计得非常精妙,占用资源很少,但是效果却不错。如下是它的架构,首先数据从SATA写入后,就放入一个写buffer,这个buffer大小32MB,可以放8000个4KB数据块。每笔4KB数据块,从偏移512处读20个字节来快速计算出一个Hash索引值(512和20是实验证明比较好的参数),这个值是干什么的?就是对数据块做一个粗分类,按照Hash索引值,把数据块放到最下面不同的桶里面。Hash后放桶里分类是一种常见的软件分类方法。这样重复的数据肯定在一个桶里,不同桶里的数据必然不会重复。这些桶里放的其实不是数据本身,而是数据的指针而已,数据还在buffer里面呢。那为什么要分成不同的桶?什么时候去重啊?
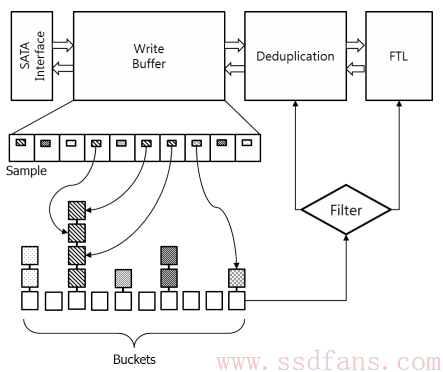
去重的时间很好猜到,那就是buffer满了,数据块要写到Flash了,就算算指纹,这时候桶就发挥作用了。如果数据块所在的桶里只有它一个,那就不用去重了,直接写下去。如果桶里有好几个小伙伴,那需要计算一下指纹,当然,是用软件计算,得花几百个微秒。不过说实话,这种采样之后数据Hash值还相同的话,重复的概率很高了。
指纹管理
指纹计算是结束了,但是怎么保存呢?搞一个大的指纹映射表明显不够现实,因为SSD主控的嵌入式环境伤不起啊!在给出方案之前,我们再来分析一下常见应用的写统计数据,思路自然就有了。LRU(Least Recently Used)是一种Cache常见的算法,就是把最近最少使用的数据从缓存移走。作者建了一个LRU模型,把最近写的4KB页都放在栈里面,顶部的被访问的时间近,底下的时间远。根据这个模型,在不同的栈深度下,新写的数据就有可能和栈里维护的数据重复,做实验得出重复率结果如下图。
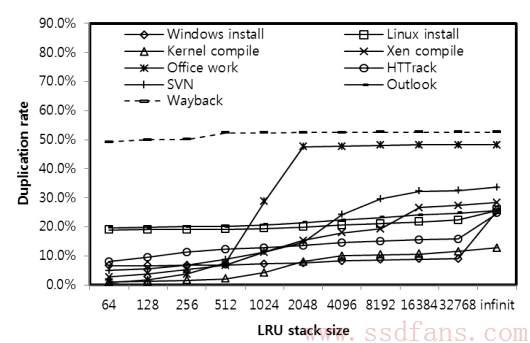
可以看出,栈其实不用太深,就能达到比较高的重复率。所以把栈深度设为2048,至于数据结构比较复杂,包括一个LRU双向链表和两个Hash表(Hash键值分别为指纹和物理地址)。在DRAM中占了2048×40字节=80KB空间:指纹20B(160bit),物理地址4B,LRU双向链表8B(估计两个4B指针),两个Hash表8B(内容估计是两个4B的指针)。这些都一直放在内存,不会保存或者恢复。
阿呆的疑问和思考:
-
为什么是栈?看起来是个队列,新数据写进来,入队列,旧数据到期,出队列。
-
双向链表的作用:得到节点后,删除比较方便。为什么要删除呢?其实就是如果新写的数据和中间某个指纹重复,那就把这个节点删除,并添加到队列头上。
-
Hash表的作用:指纹为Key的Hash表就是新数据写进来,来查是不是有重复的。物理地址为Key的Hash表是起什么作用?垃圾回收的时候用吗?怎么用?
FTL算法
选择FTL算法之前,我们先来做一个实验。看看常用的使用例子重复写的次数有多少,如下图,横轴是重复写次数,纵轴是重复写次数的累积百分比,可以看出,大部分应用重复写次数在3次以内。
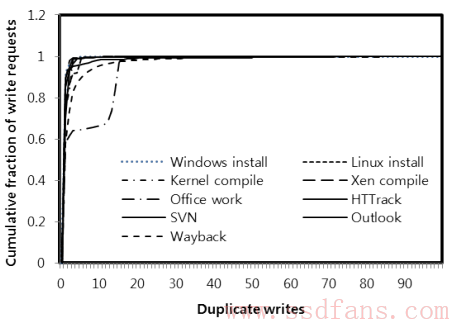
基于这个事实,在正常的LBA->PBA (Logical Block Address -> Physical Block Address)映射表之外,还加了一个反向映射表,就是如果一个PBA对应多个LBA,就有映射PBA->LBA列表。这个方案的优点是读写查询快,没有特殊的查找。缺点是垃圾回收的时候搬一个物理页,需要更新好几个LBA的映射。但是前面的实验告诉我们,主要应用重复率不超过3,所以最多更新3条映射表记录,还可以接受。
映射表太大了,DRAM不够放,所以采用了Cache机制。为了防止异常掉电,加超级电容或者电池保护。
垃圾回收也比较简单,就是可用空间到80%以下(真的吗?太早了吧,20%差不多),就选择一个最合适的block开始数据搬移,把有效数据搬到新的block,更新映射表。最后擦除老的block,释放空间。一般选择最合适Block的方法就是找到无效数据最多的,这样搬的数据量最少。在这里,去重发挥了优势:重复数据只需要搬一次,提高了垃圾回收效率(阿呆认为单次搬的数据量没变,只不过频率降低了)
磨损平衡(Wear Leveling):一般的算法是把擦出最多的Block和擦除最少的Block数据互换,为什么?因为擦除最少的Block数据访问最少,擦最多的Block访问最多,其实就是车多的马路坏的快,所以让车转移到量少的马路上。去重在此大显神威,重复数据大多在访问多的Block上,这样搬的数据量就少了(跟前面一样,单次数据量不变,频率降低了)。
维护两个映射表其实还是挺复杂的,就是要保证数据的一致性,所以更新一个映射表,另一个必须上锁,并同样更新。而且异常掉电后也会有很多特殊情况需要处理。
后面是性能测试,阿呆就不说了,无非是吹自己牛逼。不过这篇论文确实是一篇内容很扎实的文章,作者的算法并不是拍脑袋想出来的,而是都通过做实验来选择最佳方案,值得我们借鉴。
看完后,请完成课后作业:总结采用本去重方案后的SSD读,写流程,包括能去重和不能去重的写。
引用
Jonghwa Kim, Dankook University, Korea
Choonghyun Lee, Massachusetts Institute of Technology, USA
等作者
Deduplication in SSDs: Model and Quantitative Analysis

