作者 琥珀
自从2012年AlexNet赢得了当年ImageNet挑战赛之后,深度学习技术越来越多的被用于人工智能的各个领域。其中卷积神经网络(CNN)也在图片分类问题上大放异彩。不过由于卷积神经网络计算代价较大,现有的卷积神经网络模型大都是利用GPU进行运算加速。随着相关应用的普及,CNN模型在嵌入式系统上部署的需求越来越迫切,因此利用FPGA代替GPU进行CNN模型的加速计算成为了另一种深度学习模型的加速方案。
一个经典的CNN模型——LeNet5如图1所示。从图中可以看到,LeNet5含有2个卷积层、两个池化层和两个全连接层。

图1 LeNet5模型
为了方便分析我们将该结构的细节用表1列出。其中L1~L6表示该模型的第一层到第6层,和分别表示输入和输出feature map的个数,和分别表示该层输入和输出feature map的尺寸。每个卷积层中含有个卷积滤波器,每个滤波器的尺寸为并且卷积的步长为。每个池化层的池化的尺寸为。整个CNN模型的训练过程就是一个利用反向传播(BP)算法不断调整模型参数的过程,显然这是一个迭代的过程。
表1 LeNet5模型配置
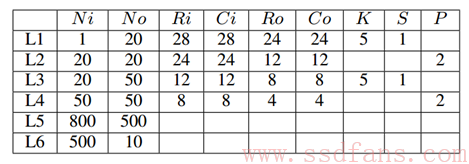
可以看到,CNN的训练过程中的每次迭代中具有相似的计算模式,正是这种计算模式向我们展示了基于FPGA平台进行CNN训练加速的潜力。已有不少研究人员在进行这方面的研究。在这篇文章中我们将介绍其中一种经典方案:F-CNN。
通过分析卷积神经网络的模型结构可以得到,为了更好的设计基于FPGA的CNN的训练架构,首先要考虑以下几个方面:
1)模块化。最先进的FPGA上也无法单独完成整个CNN模型的训练过程,所以为了完成在FPGA上训练CNN,需要对不同的层进行模块化设计。
2)统一的数据路径。为了减少模块间耦合的消耗并提高整个架构的有效性,需要设计统一的数据流路径,便于最好的利用存储带宽。
3)运行时重配置性。为了适应整个CNN模型的训练过程,需要整个架构具有可重配置性。
考虑到上面3点后,一个经典的基于FPGA的CNN训练架构就可以设计成如图2所示。该架构是一个CPU/FPGA混合平台,其中CPU用做控制器,FPGA用来加速计算,同时FPGA卡上的DRAM用于存储每个计算模块的输入输出数据。在该架构中,模块控制器负责根据不同的层配置定制不同的计算模块,并且按照特定顺序将模块重新配置到FPGA上:在一个训练周期中先是从底层到顶层的前向计算模块,然后是从顶层到底层的反向计算模块。数据控制器将训练数据分成不同的minibatch,并将它们加载到DRAM中用于训练。同时对于multi-FPGA平台,数据控制器还要控制FPGA间的数据转换。运行控制器负责调用模块配置完成计算。在该架构中数据的读写地址作为参数传递,使得模块可以访问DRAM中的数据。除了数据之外,模块还需要相应的权重。由于与训练数据比起来权重的数据量要小的多,同时考虑到BP算法中需要相应的权重进行计算,因此在该架构中将权重和偏差存储在CPU中,并通过PCI-E将它和其他参数一起传输到FPGA。这种设计方式可以减少DRAM的I/O负载,充分利用PCI-E带宽,使模块设计独立于权重。最终CPU在从FPGA接收到偏导数后负责更新权重。
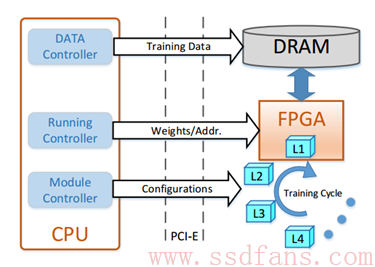
图2 基于FPGA的CNN训练架构
总结来说,对于一个给定的CNN模型,该架构首先将不同层模块化,利用数据控制器将训练数据划分为不同的minibatch。然后进行如下迭代训练过程:
1,将模块重新配置到FPGA中;
2,在DRAM中准备数据,这一步有三种情况:
a)对于第一个模块,将训练数据从CPU加载到DRAM中;
b)对于单个FPGA架构下的剩余模块,中间数据已经在DRAM中,无需数据间传输;
c)对于multi-FPGA架构下的剩余模块,中间数据将从一个FPGA传输到另一个;
3,调用模型进行计算;
4,回读结果并更新权重,然后判断是否结束,如果不结束,跳转到第一步继续执行。
整体架构设计清晰后,如何将CNN模型进行具体的模块化呢?
参数化模块的整体框架如图3所示。其中输入控制器包含一个地址生成器和一个调度器,地址生成器负责产生地址并且读取每个时钟周期的输入数据,调度器负责缓存输入数据并且将该数据送给计算单元。输出控制器包含一个用来将输入数据存储到DRAM中地址生成器,并且负责通过PCI-E将更新过的权重传送回CPU。

图3 参数化模块的整体框架
众所周知,CNN结构中最重要和最典型的结构就是卷积计算和池化计算,为了达到并行加速的目的,该架构中要设计适合在FPGA中计算的卷积核和池化核,因此在该架构中将卷积核和池化核分别设计为如图4和5所示。
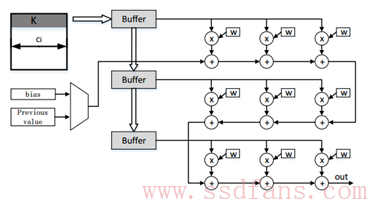
图4 卷积核
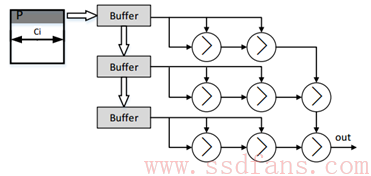
图5 池化核
除了卷积层和池化层,卷积神经网络中还有一个重要的组成——全连接层。从数学角度来看,全连接层的计算就是矩阵相乘运算,算法1描绘了该架构中全连接层的计算方式。

为了验证模型的有效性,研究人员LeNet5部署到基于该架构上进行了实验。
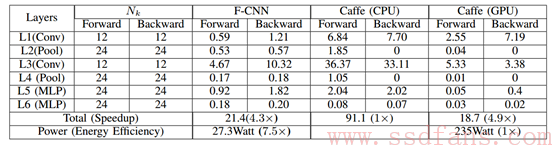
实验结果如表2所示,在LeNet5模型结构上基于FPGA的架构比采用Caffe实现的CPU架构速度快了约4倍,同时稍微弱于使用Caffe的GPU架构的执行速度,但是该架构是使用Caffe的GPU架构的能源效率的7.5倍。从该架构的实验结果来看,FPGA进行CNN加速是一件非常有效的手段。
表2 LeNet5在F-CNN、CPU、GPU上每次迭代平均执行时间(S)
相信在嵌入式系统上部署CNN模型具有迫切需求的今天,利用FPGA等进行CNN模型的加速计算将越来越多地被应用。
参考文献:
Zhao W, Fu H, Luk W, et al. F-CNN: An FPGA-based framework for training Convolutional Neural Networks[C] Application-specific Systems, Architectures and Processors (ASAP), 2016 IEEE 27th International Conference on. IEEE, 2016: 107-114.

