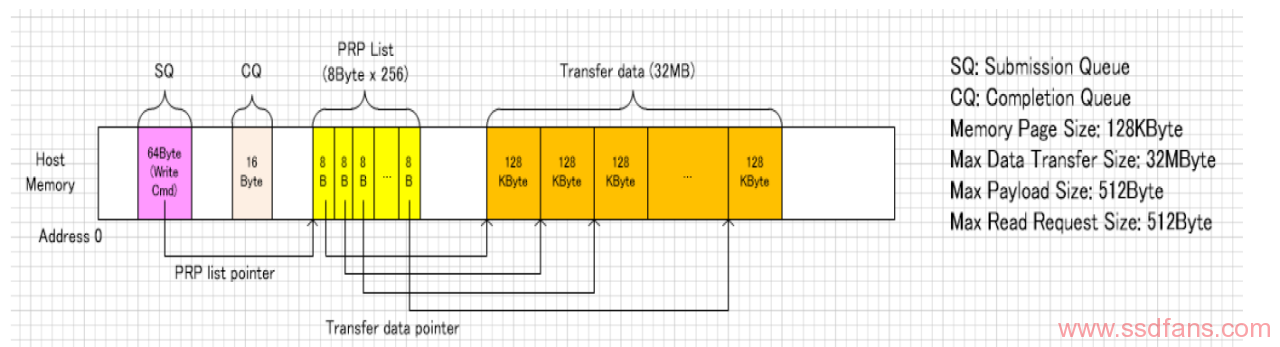
背景:WD的CFexpress card需要支持的MDTS是32MB,也就是说单个NVMe 命令,最多支持传输32MB的数据。Host这边的Max Memory Page Size是128K,inbox NVMe Driver会把这32MB数据分成256份,每份128KB的数据使用1个PRP entry进行传输,CFexpress card会一次性把这256个PRP entry都抓过来。因为每个命令传输的数据都很大,命令之间的转换开销相对变小,整体性能会比较好。
Notes: 之前看过Sandisk的一份财报,有40%左右的营收来自SD卡,现在单反随便一张照片就20,30MB。收购了Sandisk的WD,拿一个处理大文件的问题出来讨论,挺应景。
下面这张图很直观的显示了NVMe通过一个写命令传输32MB数据时,Host Memory里的内容。
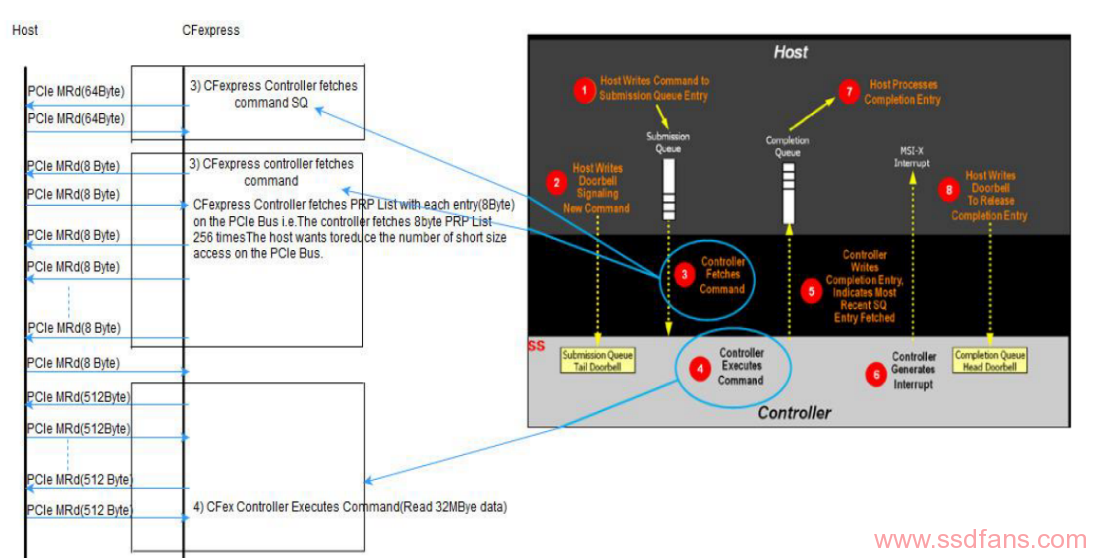
下图是CFexpress controller执行的具体流程
- 从SQ中抓取命令;
- 从命令中解析出PRP/PRP List地址;
- 抓取256个PRPEntry(每个8Byte);
- 每个PRPEntry中存放了一个128KB的Memory page的地址,其中存放了Host准备传输的数据;
进行数据传输;
下图是WD给出的NVMe SSD Controller的架构:
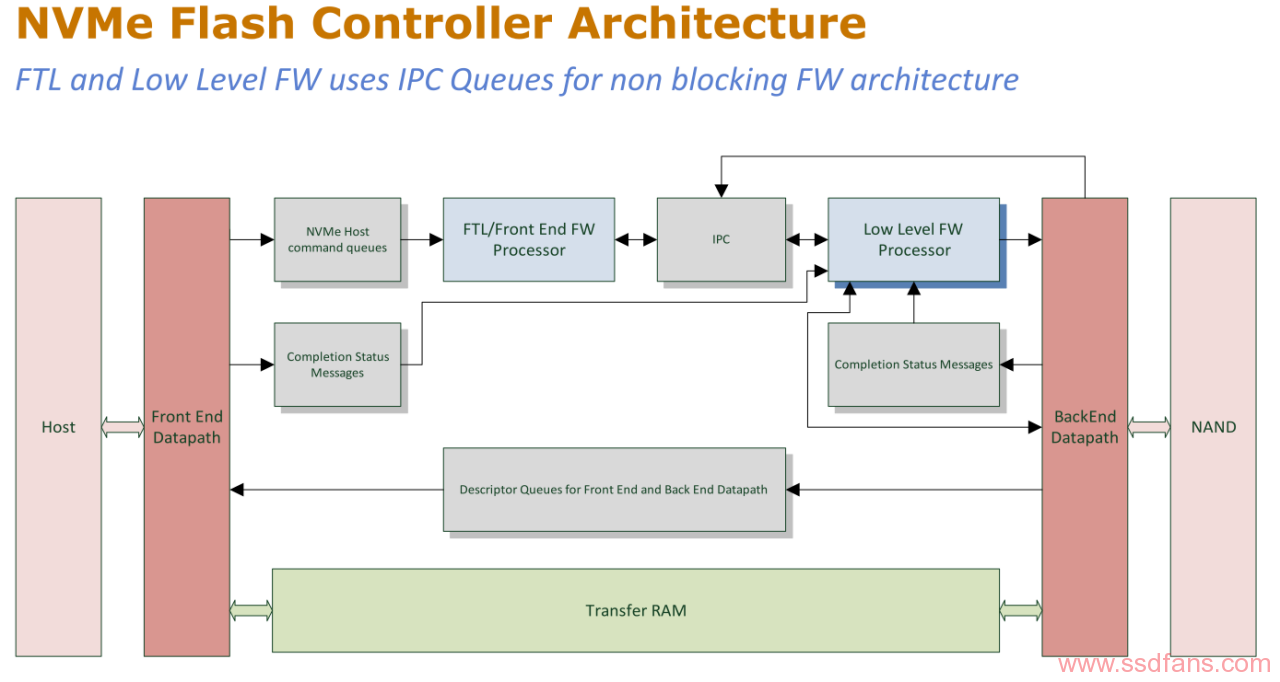
- 整体而言分为前端/后端
- 前端负责通过PCIe与Host连接,走NVMe协议进行数据传输;
- 后端负责跟NANDFlash连接,进行数据读写;
- 前端和后端的固件分别运行在两个不同的CPU上,通过IPC(InterProcessor Communication)进行沟通以及命令转换;
- 两者都能访问Controller的DDR,进行数据的存储和传输;
处理大数据量的读命令的挑战在于:
- FTL把前端的NVMe命令转换成适用于后端的命令,存入IPC命令队列中,供后端固件读取并执行;
- 按照惯常的做法,FTL会将前端的命令切分成大小为32KB的命令发给IPC队列;
- 配合16个Die的NAND使用时,IPC队列深度一般为32;
- 一个32MB的命令,切分成1024个命令,会导致IPC队列全满,从而导致固件停止工作(IPC队列除了接收前端过来的命令,还需要用于上报错误信息,获得坏物理页的校验信息等,必须保证有空的Entry);
增加队列深度可以一定程度上缓解,但是:
- 固件无法确定需要多大的队列才能满足要求;
- 过大的队列深度需要增加SRAM的容量,提高成本;
- 即使将IPC队列的深度提高,也无法避免不被持续不断的大数据读命令耗尽;
针对这个问题,WD提出了解决方案:
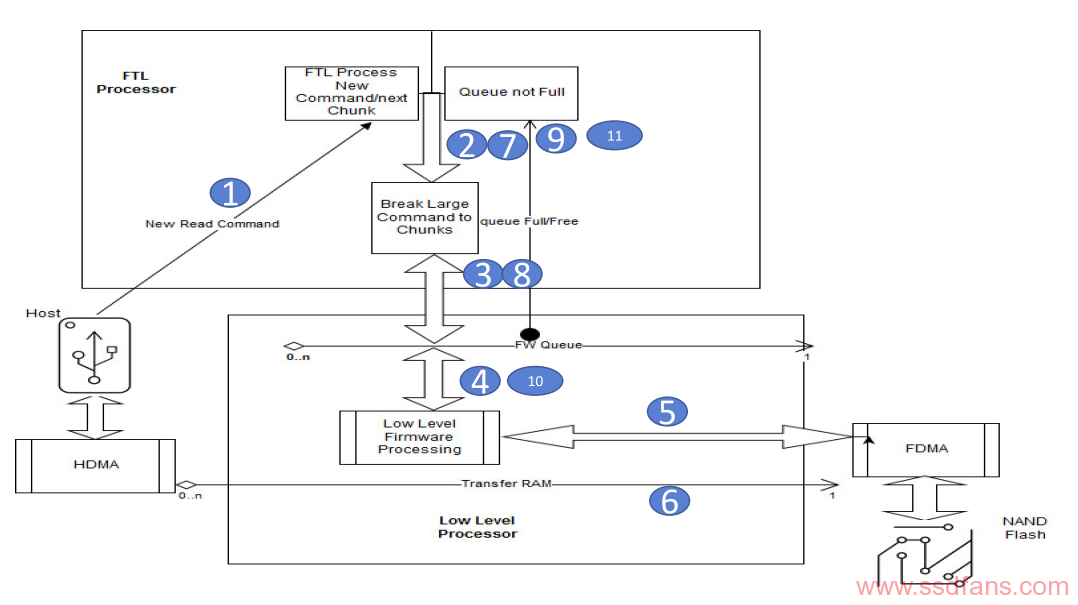

分块处理:
- 引入Chunk概念,FW可以根据需要定义其大小,比如512K;
- 在前端把大数据命令切分成Chunk,在该大数据命令的所有Chunk被处理完之前,不从SQ中抓取后面的命令;
- FTL按照原有流程处理单个Chunk,转换为后端的命令写入IPC队列 (如果单个Chunk为512K,则写入IPC队列的命令为16个);
- 后端从IPC队列中取出命令;
- 后端发送命令给NANDFlash;
- 后端将NANDFlash中数据写入DDR供前端读写;
- 检查IPC队列,如果已满,FTL暂停处理下一个Chunk(等待后端FW清掉队列满的状态),否则继续处理下一个Chunk;
支持混合处理
- 在处理大数据命令的Chunk时,允许FTL处理其他数据量小于Chunksize的命令;
Notes: 这个主要是从Performance角度考虑,充分利用Controller内部资源进行同时激活多个命令;
错误处理
- 流控机制保证了在处理读写命令的同时,后端固件在需要时上报错误时有可用的队列条目;

