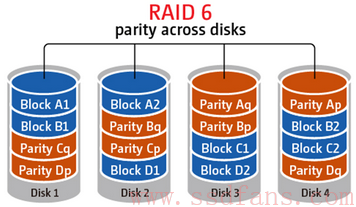
RAID 6的缺陷
如上图,RAID 6比RAID 5更安全,因为有两个盘来保存校验数据,而且还采用不同的奇偶计算表达式,意味着系统可以允许同时有两个盘出现故障而数据不丢失。为什么可以有两个盘出现故障呢?很简单,请想想中学时候学的二元一次方程组,有几个未知数,就需要几个方程来求解。现在有两个盘坏了,就是有两个未知数,所以我们用两个方程就能算出未知数了。
太好了!这样数据就更安全了,那还愁什么呢?我们来看看一次简单的随机写就知道RAID 6有着致命缺陷。就以上图为例,用户要求更新磁盘 1上的一个4K数据块,流程是这样的:
- 3个4K读:读出原来的4K数据和两个4K校验块;
- 根据新的4K数据块,重新算出两个校验块;
- 3个4K写:把新的4K数据块和两个新的校验块写入磁盘。
为了一个用户的写,后台居然要有3个读,3个写,写放大300%!这对SSD的寿命绝对是巨大损伤。顺序写还好,因为不需要读改写,随机写就惨了,几乎每个4K写都是上面的流程,写放大接近300%。
怎么破?
仔细分析这个流程,我们就会发现问题之所在:每一个4K数据块和两个校验块位置是对应死的,改数据必须要改校验块。所以,要想解决这个问题,就得从这里下手。XtremIO的XDP:XtremIO Data Protection就是改写数据后,会把数据块放到新的位置,和其他新写的数据一起放,实时计算校验,这样就避免了前面的问题。为什么SSD可以这样,而HDD不行呢?因为HDD寻址慢,毫秒级的,换到新的地方,磁头要重新转动,速度低。SSD就没这个问题,写到哪里都是一样的时间,所以RAID 6在SSD这里终于找到了好搭档。
XDP RAID流程
原始的状态是这样的:
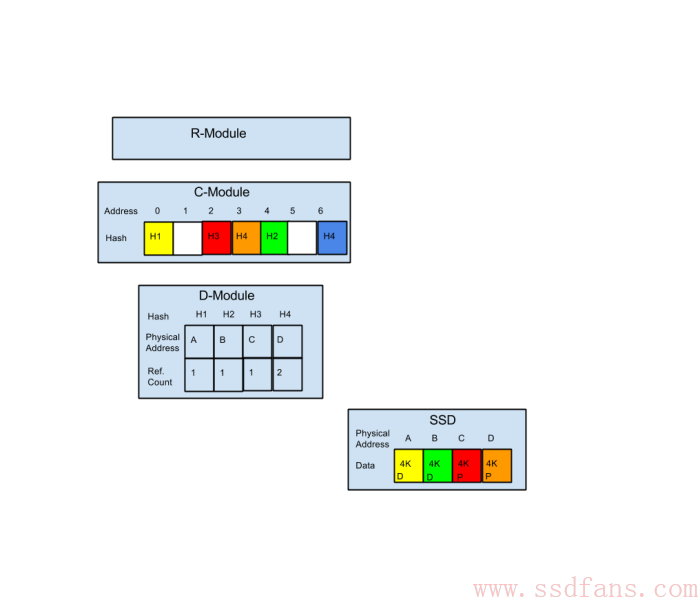
如下图,是一个包含了RAID 6的写操作流程。
- Host把写命令通过FC或iSCSI接口发送给R模块,命令包含数据块逻辑地址和大小。
- R模块把命令拆成4KB大小的数据块,计算出逻辑地址2的Hash值H5,转发给C模块。
- C 模块发现逻辑地址2的原来Hash是H3,所以更新了A2H表,H3替换为H5,转发给D模块。
- D模块把H3对应的物理地址C引用数减一,变成0,意味着数据是垃圾,或者被删除了,以后这个地址C可以释放给别人用了。然后给数据块H5分配SSD中的物理地址E,写下去,计算RAID 6的两个值,这个都是在内存中计算,因为整个RAID条带没写完,RAID值要一直更新,直到最后一个块的数据写完。
-
在下图例子中是2:2,就是一个条带有4个块,两个数据块,两个RAID校验块。等凑够了一个条带的两个数据块, 就把两个RAID校验块的数据也写下去。
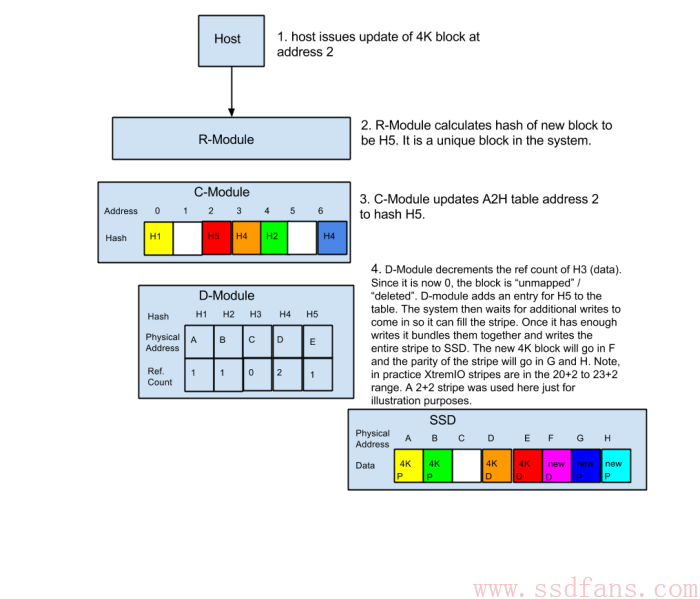
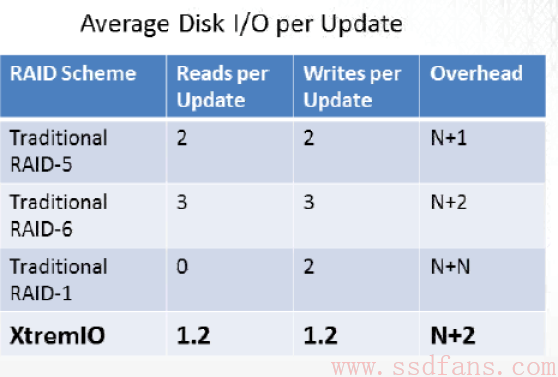
当然,实际中不可能是2:2的关系,那样二分之一的空间都来存储校验数据了,成本太高。XtremIO实际支持的比例是20:2到23:2,会动态调整。差不多9%的空间存放RAID校验数据。如下图,是在一个10:2的比例下计算出的XtremIO的数据改写导致的RAID额外读写,明显比传统RAID方式简单了很多倍。其实不只是全闪存阵列了,SSD里面SSD主控做RAID也是类似的方法。很少有人傻到会真的用RAID 5或者RAID 6那套方法来写数据,简直跟自杀没区别。
引用
http://vjswami.com/2013/11/13/xtremio-hardwaresoftware-overview-architecture-deepdive/

