
一款正经的SSD要经过严格的Endurance测试,也就是耐久性测试,简单说来就是SSD有多经用。JEDEC有两份SSD Endurance测试的协议,分别是:
- JESD 218A:测试方法
- JESD 219: workload
首先需要了解的概念:
- TBW:总写入数据量
- FFR (Function Failure Requirement):整个写入过程中产生的累计功能性错误
- Data Retention:长时间不使用(上电)情况下保持数据的能力
-
UBER(Uncorrectable Bit Error Rate):
UBER= number of data errors/number of bits read
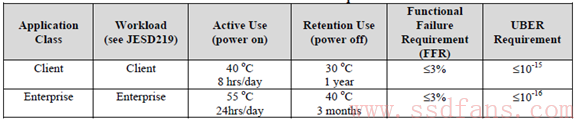
企业级和消费级SSD在Endurance的要求上是不同的,体现在:
- 工作时间
- 工作温度
- UBER
- Retention温度以及时间
具体数据见下面表格
虽然叫Endurance测试,但是218其实是包括了Endurance和Retention两部分测试的,官方给的方法有两种:
- Direct method — 直接上法
- Extrapolation method – 拐弯抹角法
本文重点解释Direct method,理解了这个以后,另一个方法理解起来就很容易了。
Direct method,简单来说,就是使劲写,可劲读,用站在食物链顶端的男人的话说就是”Push the SSD to limit”,在这个过程中,要注意:
- 要求有高低温
- 必须用指定的workload
- Endurance test以后马上Retention test
这些个后面详细介绍,首先要搞明白一个问题,应该拿多少块SSD跑Endurance测试?
要求一:如果该系列SSD首次进行测试,选取的SSD要来自至少三个不连续的生产批次,如果不是首次,选一个批次的就行。
要求二:制定标准的老外们直接给了两个公式
- UCL( functional _ failures) ≤ FFR ⋅ SS (for Functional Failure)
- UCL(data _ errors) ≤ min(TBW,TBR)⋅8 ⋅1012
⋅UBER ⋅ SS (for Data Failure)
如果只看公式,你可能会跟我一样,一脸懵。
Functional failures:可以接受的出现功能故障的SSD的数量
Data errors:可以接受的数据出错的数量
TBW,TBR:总写入/读取量
SS: Sample Size,就是我们要求的X (用多少块盘测试)
UCL(): Upper confidence Limit函数,看不懂是不是,不用你看懂,直接查表就行。
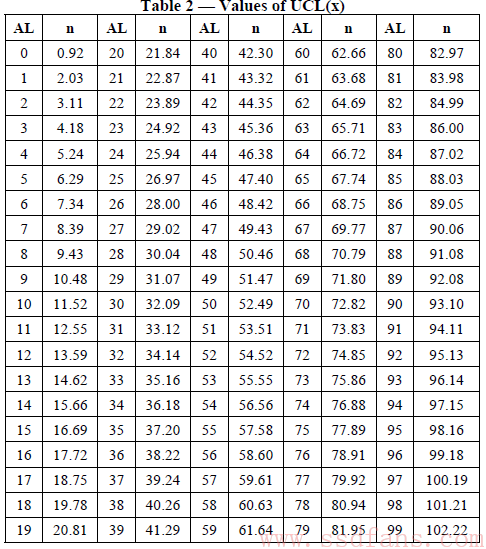
通常我们直接用AL=0(AL=0代表没有functional failure),这样的话对应的UCL就是0.92。
结合一个实际的例子, FFR=3%, UBER=10-16, TBW=100代入公式,得到:
两个SS分别能够满足Functional Failure和Data Failure的要求,取两者之间的大值30.1,所以需要的跑测试的SSD数量是31块。
再把SS=31代入公式:UCL(data_errors) ≤100⋅1⋅8⋅1012⋅10-16⋅31 = 2.48
在用2.48这个值去刚才的表里反查,得到允许的最大data errors数量为1
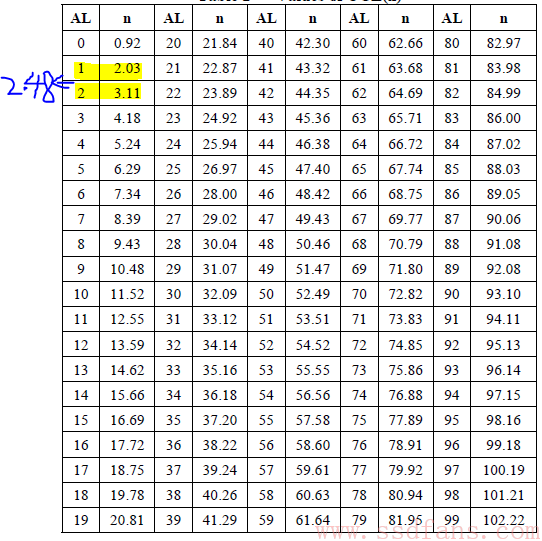
总结一下:选31块盘,跑完Endurance测试,不能有funtional failure,可以最多有1个data error,测试通过。
Endurance测试使用的workload, 这东西网上可以下载,整个workload大概有4亿条Write,trim,flush命令, 每次写完之后需要read回来确保数据是正确的,具体实现的工具没有要求。
Enduance和Retention过程中另一个重要的因素就是高低温。
具体的温度要求见下表,可以看到企业级SSD要求比消费级的高出不少。
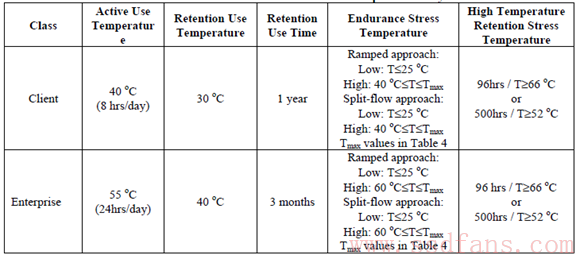
控制温度变化有两种策略:
- Ramped-Temperature approach: 所有SSD放在一起,在高低温间来回切换
- Split Flow approach:所有SSD分两半,一半进行低温测试,一半进行高温测试
低温没有问题,都是≤25℃。
高温的要求是一个区间,比如Client SSD是40℃≤T≤Tmax,高温下限是40度,上限没有给出具体数值。
在JESD-218A的附录里介绍了通过温度对Endurance和Retention测试的时间加速作用,因为篇幅问题(其实是懒得看),就不具体介绍了。论证的结论就是温度越高,就能用越短的时间模拟出对SSD进行1年读写的效果,对应关系如下:
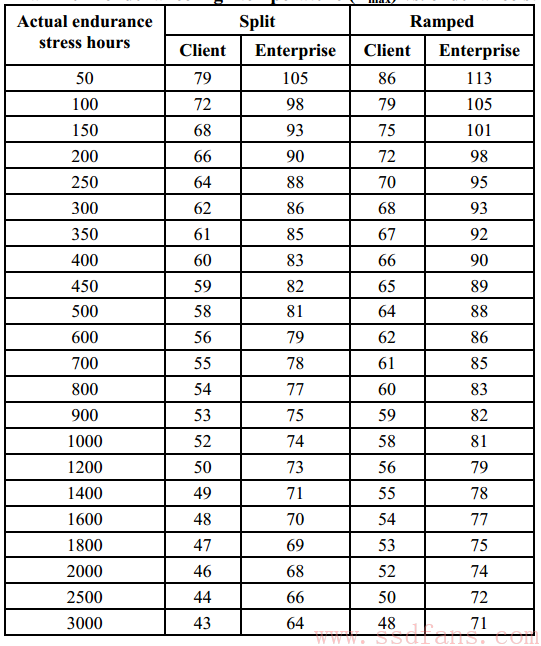
以第一行为例,采用Ramped temperature方式,当高温达到86摄氏度时,对一块盘进行50小时的读写(必须用官方的workload)能够达到常温下一年的效果。
而同样的SSD,如果高温只有48摄氏度(最后一行),必须跑3000小时的读写才能达到一样的效果。 (此处应该插入一个Chamber的广告)
那怎么确定这个Tmax呢?我理解得步骤是这个样子:
- 根据SSD容量计算器TBW, 比如160G的TLC SSD,按PE cycle 500计算其TBW应该是80T
- Workload来一遍为1TBW
- 那么总共需要把Workload跑上80遍
- 假设跑一遍Workload需要5个小时
- 那么总时间就是400小时
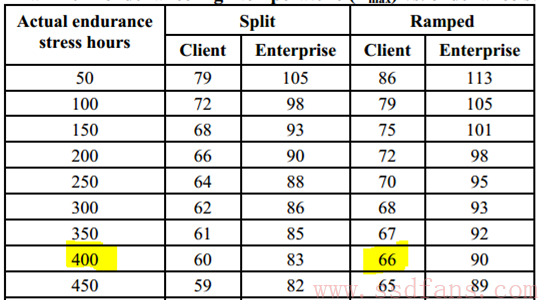
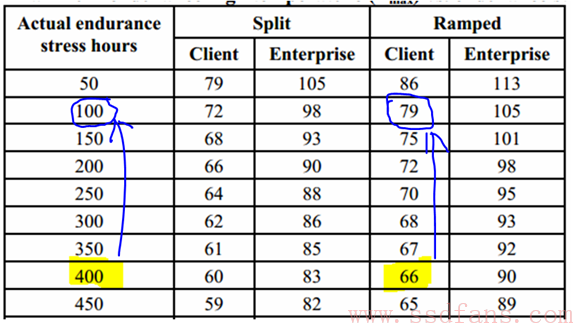
- 400小时在表格找到对应的温度为66度(Client SSD,Ramped),这个就是Tmax值,见下图
有了Workload,知道了温度范围,就可以正式跑Endurance测试了,以下是Direct Method使用Ramped approcah的流程图:
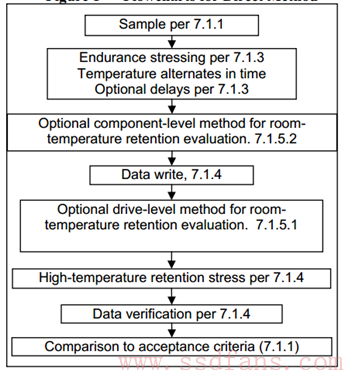
从上到下整个过程分别是:
- Sample – 取样,确定用多少块SSD测试
- Endurance 测试
- (可选)部件级常温Rention测试
- 写入数据 – 为了后面的Rention测试
- (可选)产品级常温Rention测试
- 高温Retention
- 数据比较
- 判断是否通过 (检查FFR和Data error是否满足前面那两个公式)
步骤1,2已经介绍过,步骤3~7都是关于data rention,这个测试要求在Endurance测试结束以后马上进行:
写入数据à 断电à高温à 上电à数据比较
而对于某个系列的首次Endurance测试,还要求进行常温rentention测试,详细情况可以参考JESD218A 7.1.5
最后简单提几句Extrapolation method,说白了就是用各种方法在最短的时间把Endurance测试给完成了,比如:
- 修改Workload,在更短的时间内造成更多的PE cycle (修改随机/顺序访问占比,传输数据大小,引发更多background activity等)
- 限制SSD的大小,比如把前面160G SSD通过固件限制为40G可用,那么所需要的Endurance时间就直接从400小时降低到100小时(相应高温需要从66度调整为79度)
特别要注意的是,固件在限制大小的时候,不仅要限制开放给Host的读写区域,同时内部的OP空间也必须同样做等比例的缩小。

