作者 王齐
2016年7月初,ITRS (International Technology Roadmap for Semiconductors)发布了也许是最后一份有关半导体工艺的报告。硅半导体工业在历经五十余年的辉煌后,逐步走向尽头,基于硅的晶体管尺寸(Physical Gate Length)可能在五年后于10nm处终结[1]。我们继续从理论上探讨晶体管能否到达5nm愈显苍白,芯片在大规模量产时使用5nm日趋渺茫。
在实验室早已取得成功的7nm技术,前景并不乐观。基于性价比的考虑,使得在没有足够商业利益驱动的7nm技术,面临着无法大规模产品化的现实。南美蝴蝶翅膀几次微不足道的扇落,足以使得继续在刀尖上行走的5nm与7nm技术,跌下神坛,粉身碎骨。
摩尔定律已正式结束,但永存于世间。
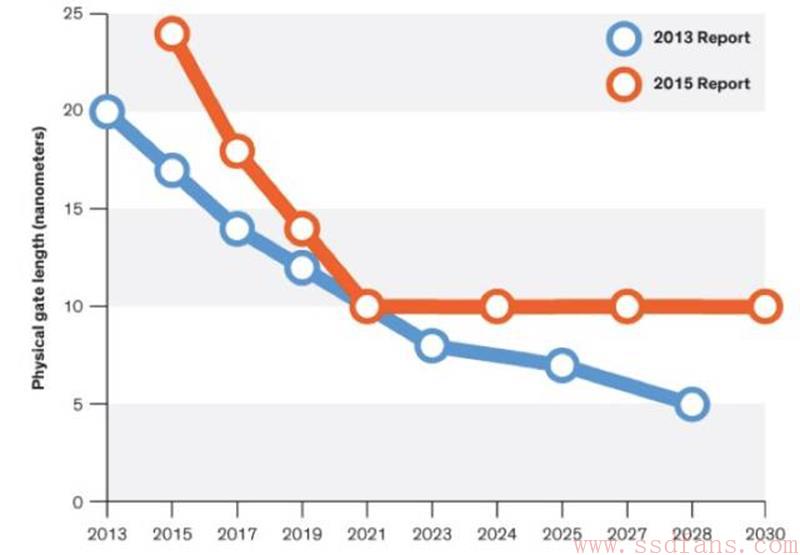
图11摩尔定律的终结[2]
在世界范围内,对硅半导体的材料科学,制作工艺,有能力也有意愿继续的厂商可能只留下了Intel,Samsung,TSMC与Global Foundries。在近期或者在不久的将来,或许中国为了完成世界工厂的巨大转型,将接过半导体生产制造的旗帜,使其更加廉价,使其更加缺乏必要的盈利以支撑整个产业链的持续发展,维系也在终结这个行业。我继续悲观地维持在几年前的判断[3],基于硅的半导体工业不可或缺,也不再重要。
谈计算
缘起于上世纪四十年代的冯诺依曼体系正在等待着最后一根稻草。至今处理器的设计者再也无法按照自身的理念决定自己的设计方向,当这些处理器的设计者不知道做什么合适,而转身专注于Cache、内存与I/O通路时,基于冯诺依曼体系的传统处理器事实上已经结束。掌握用户场景与应用的厂商目前是处理器真正的设计主导者。定制化时代不再是多年之前的预判[4],而是已然来临,并主宰着处理器设计的方向。
硅半导体与传统处理器的停滞不前,不会结束人类对于硅的依赖,在短期内尚无任何材料能够完全替代硅。应用对于硅的需求依然明确。在一分钟内,Youtube将至少接收长达100个小时的视频文件[5];在Facebook上,每天有40亿次视频点击播放[6]。这些应用需求将通过网络,到达各类服务器,并从存储器中获取或者写入数据,进行着各类数据的处理。在计算、网络与存储这些基础架构中,硅半导体依然占据主导地位。
神奇的半导体硅改变了人类历史的发展轨迹,也几乎走到了尽头。近半个世纪以来,硅一直有互补品,如砷化镓GaAs与氮化镓GaN,这些在大功率与高频领域已有着重大应用的半导体材料无法取代硅,基于二硫化钼MoS2和碳纳米管CNT (Carbon Nanotube)的晶体管甚至可以将Gate Length做到1nm[7],但是依然处于实验室阶段,用其替代硅仅仅停留在论文的纸面之上。至今硅工业的天花板制约了整个IT基础设施行业前进的脚步。
在计算领域,被软银收购的ARM已经难以对x86处理器带来持续的压力。在手机处理器上取得了长足进步的苹果、高通、三星与华为,在近期难以在服务器市场上对Intel带来实质性的挑战。许多ARM服务器在SPECInt的测试中宣称已逐渐接近了x86处理器,却在有意无意的忽略着一个显而易见的事实,这一代的服务器,甚至是手机处理器,都不应该继续关注SPECInt与SPECfp这类单纯比拼计算性能的基准测试。
目前处理器的设计中心已经转向I/O与Memory Hierarchy通路的建设。在Intel的Broadwell-E处理器的Die Map[8]中,10个处理器微架构(Core)合在一起所占的比例已经不算太大,Memory Hierarchy与I/O占据了大多数的Die资源。
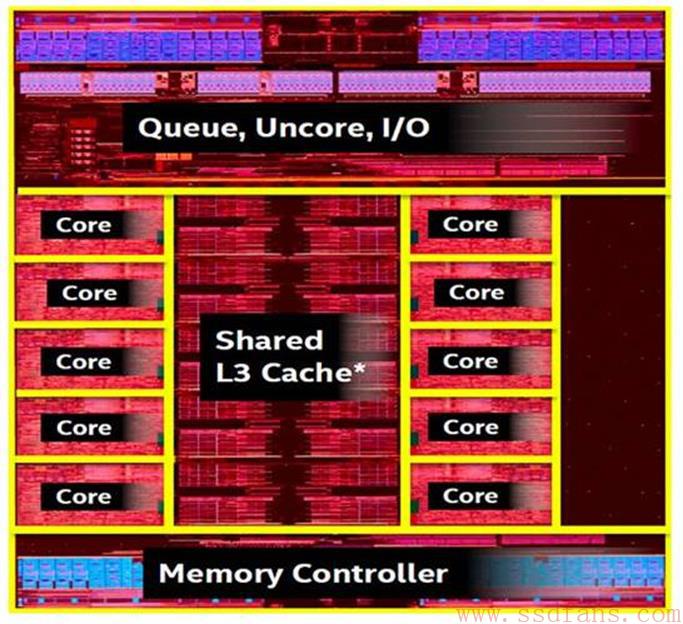
图12 Intel的Broadwell-E处理器的Die Map[8]
在一个处理器微架构中,运算单元所占的比例几乎可以忽略不计,在处理器微架构中,依然是种类繁多,各类数据缓冲占据着主导位置。事实上,除了模拟器件以及与模拟器件强相关的芯片外,在多数芯片Die Map中,缓冲都占据着关键位置。迄今为止,计算领域的多数应用对处理器的使用都是访存密集型。
处理器的设计初衷本是为计算服务,但是在今天的许多应用场景中,处理器所承担更多的任务是通过各类I/O设备获取数据;这些数据在穿越MemoryHierarchy后抵达CPU的核心部件;CPU核心部件在精确计算着心跳的过程中,尽可能地快速处理这些数据,而后将其再次转发至远方。和密集计算相关的任务,已经通过各类硬件加速引擎,GPU或者专用ASIC实现。
我们无法直面一个简单而令人沮丧的事实,在处理器运行着的各类协议栈的代码组成中,用于实现快速路径的代码可能不超过1%;99%以上的用于异常处理的代码,可以在超过99.9%以上的时间段内安然入睡,其存在只为等待着可能的异常出现。
不是因为这些多如牛毛的异常需要处理,也许我们这个世界已经不再需要通用处理器了。从纯计算的角度上分析,各类硬件加速引擎,GPU、FPGA或者专用ASIC,远胜今日的处理器,但是这些加速引擎在面对成千上万种异常时无能为力。在移动互联网厂商的数据中心中,处理器存在的最主要目的是对各类数据流进行分析、组装、打包后发往下一站。
在这些应用场景中,处理器存在的首要原因依然不是其高效的报文转发能力,而是能够应对在报文处理过程中出现的各类异常。在数据中心中,处理器存在的主要作用是能够相对高效地处理数据报文,同时还能对各类异常进行查漏补缺。不仅在计算领域,在IT基础设施的网络与存储领域,通用处理器的使用方式依然如此。
能够对通用处理器带来挑战的GPU,前景没有想象中乐观。从设计策略上看,GPU与通用处理器的最大区别在于对异常的处理。GPU专注极致计算,尽最大的可能提升TLP (Thread-Level Parallelism),而忽略异常处理;通用处理器需要考虑异常状态的处理,以追求更大的适用性。
在不同设计策略的引导下,GPU走出了一条与通用处理器迥异的道路。Nvidia的Pascal GP100由最多可达6个的一组GPC (Graphics Processing Clusters)构建;这些GPC共享同一个4096 KB的L2 Cache;通过8个512位的Memory Controller对外交换数据;使用高速的NVLink接口与其他GP100互联;最后通过PCIe 3.0总线与通用处理器进行连接[9]。
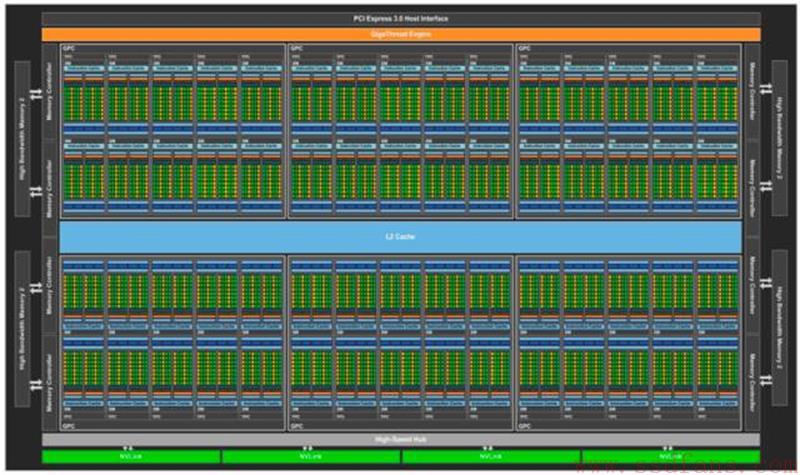
图13 Nvidia Pascal GP100 GPU组成结构[9]
在每一个GPC中,最多可以容纳5个TPC (Texture Processing Clusters);每个TPC中集成两个SM (Streaming Multiprocessors);每一个SM包含64个CUDA和4个TU (TextureUnit)。其中最基本的CUDA核心和TU数目分别可达3840与个240个。GPU的Die Size可达610mm2,所能容纳的晶体管数目可达153亿个[9]。
GPU与通用处理器,是设计者在面对有限的Die Size资源,做出的不同选择,以适用于不同的应用场景。由数目繁多的运算单元所组成的GPU,其组成结构不比通用处理器复杂,反而更为简单。但是这无法解释,Intel可以做出更为复杂的通用处理器,却在高端GPU领域上反复折戟沉沙;也无法解释,服务器级处理器的设计难度超过手机处理器,Intel依然屡战屡败。
通用处理器需要处理各类已知与未知的异常,在进行计算的同时,不断地处理各类分支跳转语句;随时准备应对各类中断事件;与此同时需要具备大规模的数据吞吐能力;也因此通用处理器需要一个规模庞大的通用操作系统。至今,计算已是通用处理器中的一个微小组成模块,通用处理器中最大的模块,是各类Cache和与其紧密联系在一起的Memory Hierarchy。
GPU聚焦的计算世界相对单纯;所处理的数据规整;数据间几乎没有太多的依赖;不需要管理外部设备,不需要处理各类中断与异常,也不需要一个操作系统。从GPU的发展历史上,可以发现,GPU所处理的图像数据并不具备非常强的Locality特性。在GPU中,Cache存在的主要作用不是为了保存需要反复使用的数据,而是为了弥补GPU内部运算部件与外部DRAM之间的访问延迟,从而没有如通用处理器那样的,复杂程度令人叹为观止的CacheHierarchy结构。
在GPU中,存在与通用处理器类似的流水线,Nvidia的GP100中的基本组成模块SM,本身就是也是一个流水线,这个流水线也被称为Graphics Pipeline,在不考虑光栅化处理的场景下,Graphics Pipeline也被称为Rendering Pipeline。
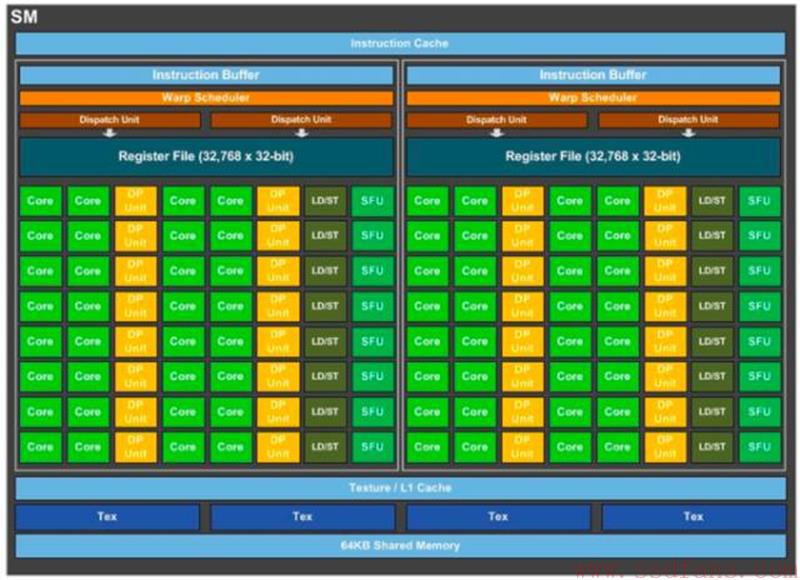
图14 Pascal GP100中SM的组成结构[9]
在Graphics Pipeline中,依然包含与指令流水线中类似的概念,如指令Cache, DispatchUnit, Scheduler, 与Register File等。也与指令流水线有很多不同之处,Graphics Pipeline不包含通用处理器用于数据相关性检查与乱序处理的Reservation Station与ROB (ReorderBuffer)。在Graphics Pipeline中的ALU充斥着大量的CUDA Core,并设置了专门的TMU (Texture Mapping Unit),以便于对图像数据做进一步处理,如旋转、缩放、扭曲等改变尺寸的操作。
这些表面差异并非GPU的Graphics Pipeline与通用处理器指令流水线的最大区别。GPU与通用处理器的差异依然是设计策略上的区别,在于异常与中断的处理策略上。从处理的数据源上看,GPU与通用处理器的最大区别在于所处理的数据是两维或者多维;从解决具体问题的层面上看,通用处理器侧重于对问题的精确求解,而GPU侧重于获得一个相对模糊的答案。从计算的顶层结构向下俯视,GPU与通用处理器依然遵循冯诺依曼的设计哲学。
存储器瓶颈制约着通用处理器的发展,也同样制约着GPU的进一步发展。主要用于计算的GPU,继续提高TLP (Thread-Level Parallelism)不是提高GPU整体效率的有效方法。与许多人的预估并非一致,GPU继续提升TLP,非但不能因为其高并发隐藏了存储器延迟,而且对存储器系统带来了更大的压力[10]。GPU没有脱离冯诺伊曼体系,只是一种不同的处理器实现策略。
以冯诺依曼体系的提出作为一个重要的分水岭,计算大致分为三个阶段。第一个阶段,科学家们用当时较为复杂,目前看来简单的电路逻辑,搭建各类定点与浮点算法,尝试精确获得某类问题的答案;冯诺依曼体系提出至今这个阶段,所解决的问题是从模糊到逐步精确,直到今天的举步维艰;在今天,我们将基于一维的定点与浮点算法推向前人无法企及的高度之后,开始漫长的等待,从逐步精确到模糊而不可预知。
人类的努力可歌可泣,他们在不知道如何选择是正确之时,做出从精确再次重归模糊的选择,重拾在上个世纪末被暂时搁置的人工智能,引入了一个新的词汇深度学习,开始了从一维空间的接近精确到多维空间模糊决策的探索之旅。目前深度学习的理论基础还显薄弱,这一代的计算平台,无论是通用处理器或者GPU还可能都不是一个合理的计算平台。
这些事实并没有阻挡,深度学习领域对GPU的严重依赖。如果仅从今天人类掌握的技术中做选择,GPU比通用处理器更加适合模糊计算这个领域。GPU从诞生之日起,就没有追求精准的计算结果,设计目标是其处理结果能够满足人眼模糊的分辨率。
Alpha Go战胜李世石,在弈城网与野狐网上横扫天下,没有保证每一步棋都是绝对最优,只需保证每一步棋比人类所能构想的最优稍胜一筹。至今利用深度学习的所有已知成果,甚至无法帮助我们精确地确定,某一个指纹或是某一个面孔一定归属于某一个人。
似乎在深度学习领域,我们很难得到一个精确结果。这些没有实现,且有机会实现的目标,为人类的发展提供了新的希望。在很多情况下,人类所追逐的是希望,而不是最终的结果。在内心深处,我并不情愿这一次的探索之旅成功。因为每当出现一个领域,其模糊决策能够比人类更加接近精确时,在这个领域,机器都将战胜人类。
经作者同意,转载自微信公众号南郭比特http://mp.weixin.qq.com/s/9Op2Wt8UEs60A3GUCuDcNw

