
继续学习兵哥捡垃圾。
CAT的全称是Cost Age Times,在Benefit-Cost算法的基础上,增加了对数据寿命和擦除次数的考虑。
CAT算法提出了数据分类的概念:把Valid data分成了Read-only, Cold和Hot三类。

Read-only data:顾名思义,就是写入之后不会被修改的数据,例如一些系统文件;
Cold data和Hot data都是可以被修改的数据,不同在于Hot data会被频繁的修改。
准备回收的Block上的数据,有这么几种情况:
-
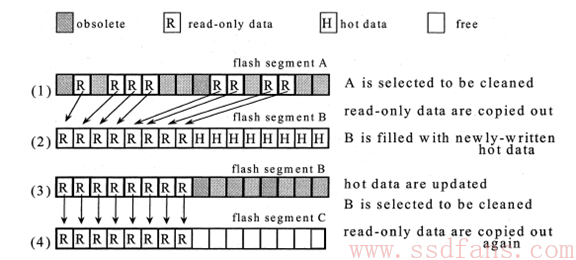
Read-only和Writable data混合:
在回收过程中,把所有的Read-only数据集中迁移到到新的Block里,如果这个新的Block再被回收,再将所有的Read-only数据集中放置。这个过程不断的迭代最终的结果是有的Block上全部都是Read-only 数据,这样的Block后面将不会再被GC程序选中进行垃圾回收。整个过程如下图所示。
-
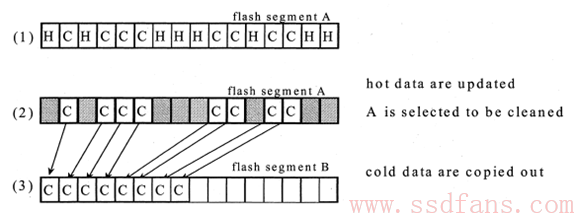
Cold data和Hot data混合:
在回收过程中把Cold data和Hot data分别迁移到不同的新的Block里。Cold data的处理方式与Read only data类似,最后收敛成一个Block里都是cold data。而hot data所在的Block因为更新频繁,很快就会充斥大量的Invalid Page,而valid page很少,回收这种Block性价比最高(需要移动的Valid page少,释放出来的Invalid page多)。过程如下图。
-
对部分区域的频繁读写,可能导致Hot data刚刚完成迁移,就立即被改写,再度成为垃圾,这种情况是需要尽量避免的。
总结起来,CAT算法的原则如下:
-
Read-only和Writable的数据分开放到不同Block;
-
GC过程中,迁移Hot data和Cold data到不同的Block;
-
通过Hot Degree属性判断数据属于Hot还是Cold data;
-
Hot Degree跟Block被改写次数正相关,跟Age(Block从被开始写入数据以到现在的时间)成反比;
-
某个Block的Hot degree如果大于平均值,则为Hot Block;
-
考虑Block的磨损情况,如果一个Block的PE cycle接近最大寿命时,将其内容与PE cycle最低的Block做交换;
CAT算法的公式:

-
μ代表一个Block里Valid Page的比例;
-
μ/(1-μ)理解为为了释放出(1-μ)的free page必须付出迁移μ的valid page,也就是整体的Cost;
-
1/age代表Hot degree跟Age成反比
-
NumberOfCleaning代表Hot degree跟Block的PE Cycle成正比
对每个Block进行计算,选择那些结果最高的Block进行GC过程。
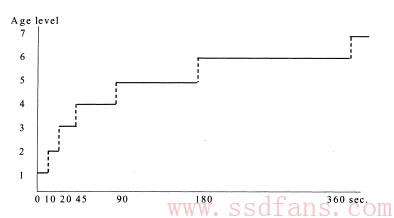
注:
实际计算age时,一般采用下面的转换公式
参考文献:《Cleaning policies in mobile computers using flash memory》by M.-L. Chiang a, R.-C. Chang
つづく

