作者 琥珀
经过三年的研究,2015年Microsoft提出了一种使用现场可编程门阵列(FPGAs)加速Bing搜索引擎的方案。这些CPU-FPGA混合器在当年便投入生产和布置,用以加速Bing页面排名功能。除此之外,微软开始寻找其他与FPGA结合使用的工作。深度学习刚好就是可以使微软从FPGA中受益的下一个重要工作。
当我们有一个在CPU上不能快速完成的工作或应用程序时,就必须考虑为其分配大量资源以便于及时获得相应的结果,在这些资源中一般都会包含专门用于加速计算的相关设备。深度学习便是这么一个例子,卷积神经网络只有在具有非常大的训练数据集与具有相当强的并行计算能力的GPU结合的情况下才能工作的更好。利用GPU可以将深度学习相关应用加速几个甚至十几个数量级。因此,当我们需要一个深度学习系统时,我们首先会想到需要一个大的GPU集群。然而微软的研究人员对此给出了不同意见,研究人员Eric Chung解释说“数据处理中心很有趣,因为我们可以扩大它的规模。关键是在数据处理中心我们可以设置大量的可替代资源,可以按需分配特定的任务,当不再需要该资源时,可以将这些资源用于其他应用程序。 数据处理中心需要处理多种多样的应用程序,与仅仅需要一个深度学习平台相比,这是一个非常不同的问题。”
系统设计的选择需要能够平衡具有针对具体应用的专门功能与希望拥有一整套基础设施的经济性和简单性的愿望。正如大部分从业者知道的那样,FPGA基本上是一种模拟ASIC操作的方法。与GPU加速器相比,FPGA的编程难度要高一些,但它具有更好的灵活性,它可以被编程并用来做任何芯片都可以做的工作,这可以更好的实现软件中的算法。但FPGA的缺点也存在,例如至少在Altera和Xilinx提供的当前几代FPGA中,FPGA的峰值性能低于GPU加速器。因此,FPGA代表了通用目的和专用硬件之间的平衡。
研究人员Eric Chung解释说,与建立仅需要做某些工作的深度学习系统的研究人员或商业企业不同,微软必须大规模运营其基础设施,这使得加速器的选择与抽象运作有所不同。在微软研究技术实验室,微软公司开放云服务器,因此它们可以配备FPGA加速器,称为Catapult系统。Chung同时表示:微软可以将GPU加速器放在每个服务器上,这对于同质性和可维护性是非常有利的,但是这将大大增加服务器的功耗和成本。同时并不是所有的工作负载都必须使用这些GPU,即使它们可以被放入开放云服务器。与其FPGA相似,微软可以使用面向笔记本电脑的40瓦GPU,并将其插入到夹层卡中,但是GPU却不像FPGA那样具有可扩展性,因为FPGA可以执行多种任务。同时很清楚的是,微软希望在其Open Cloud Servers节点内部具有低功耗的某种相对加速器。
对于各种识别系统,微软使用深度卷积神经网络,并希望使用其基础架构来训练网络,同时在实际应用中进行照片、视频和语音识别的训练。Chung表示,微软的目标是使用Catapult FPGA附加组件为其Open Cloud Servers提供神经网络的性能提升,并希望以30%的增量成本和10%的增量功率预算来实现。顺便说一下,微软可以在一秒钟内改变FPGA的运算方式,并创建了一个不同的软件堆栈,它称之为Azure SmartNIC,它是与FPGA结合的网络接口卡,可以进行线速加密/解密和压缩/解压缩网络流量,还可以使用相同Catapult夹层卡中其他软件定义的网络功能。
下图是一个微软的Open Cloud Server节点,上面有2个CPU,还搭配了2块SSD。右下角就是FPGA加速卡。

Catapult FPGA卡有一个含有172,600个自适应逻辑模块(ALM)的Stratix V D5,它可以在附加上1,590个硬编码数字信号处理器(DSP)和2,014个M20K存储器块(容量为39Mbits)的情况下运行FPGA中的”代码”。 Catapult FPGA夹层卡具有32 MB NAND闪存和8 GB DDR3 DRAM内存(两根支持1.33 GHz)用于存储,并具有单个PCI-Express 3.0 x8连接,可将FPGA挂接到Open Cloud Server节点。图1是在FPGA上运行的神经网络的加速器构件:
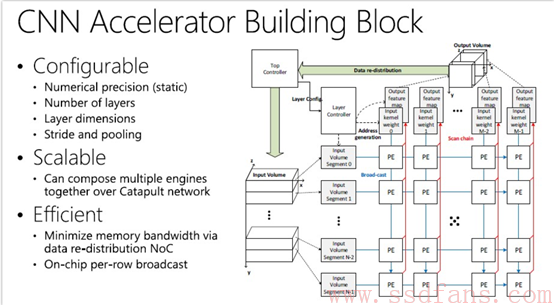
图1 神经网络的加速器构件
Catapult网络允许神经网络跨越多个FPGA扩展。该结构中每个FPGA都有两个Mini-SAS SFF-8088端口,它们用于制造仅用于FPGA的专用网络结构,并且与10Gb/s以太网交换架构分离,这使得Xeon服务器节点可以相互连接并共享工作和数据。SAS连接以20Gb /s的速度运行,并且在SAS架构上有大约400纳秒的延迟。每个Open Cloud Server有48个节点,其环面互连工作原理如下:六个相邻的FPGA卡以东西方式相互连接,然后这些多组FPGA以南北方式相互联系,以覆盖单个开放式云端服务器中的所有48个FPGA。
关键是,这种FPGA架构允许多达48台设备组合在一起工作,而不涉及CPU或其它网络。这是微软已经做出的关键探索之一,这种FPGA扩展能够和GPU或其他特殊ASIC的加速器来运行的神经网络方案进行竞争。Chung表示,神经网络进行训练时,FPGA有两种不同的运行模式:一种处理单个图像以尽可能快地进行分类;另一种在批处理模式下可以向网络中输入一批图像,并对它们进行并行分类。
那么当涉及神经网络训练时,FPGA集群如何与CPU和GPU进行对比?微软使用ImageNet基准数据集对其Catapult配置进行了一些测试,并将其与原始CPU和CPU-GPU混合设备进行了比较。图2和图3是相关测试结果。
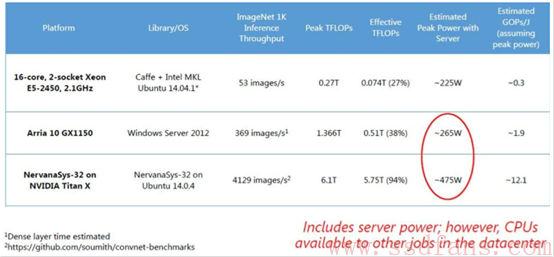
图2
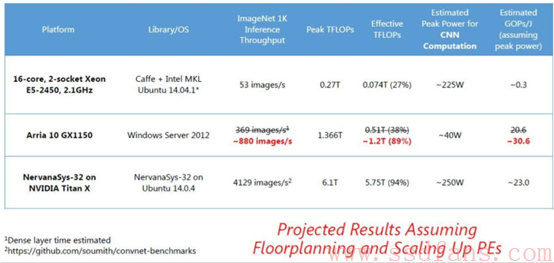
图3
CPU测试是针对使用八核Xeon E5处理器的Open Cloud Server节点,它运行Linux和Caffe神经网络框架。该服务器节点具有270 GHz的性能,处理器运行在2.1 GHz,它可以在ImageNet-1K测试中每秒处理53张图像。该机器的功率峰值功率为225瓦,每焦耳每秒可达3亿次。
对于最新的深度学习测试,微软将Catapult系统中的Stratix V FPGA卡升级到具有更多的优势的Altera的Arria 10 GX1150。 微软公司一直预测,在ImageNet-1K上使用Arria 10 FPGA可以获得大约233张图像/秒的处理速度,但是它的实际测试结果比预测的要好一些,每秒可以处理369张图像,具有265瓦的功率消耗,每焦耳每秒可达19亿次,这比普通CPU的功率效率好得多。Arria 10 FPGA的原始性能为1.36 teraflop,Chung表示这是FPGA运行在270 MHz时的结果,但微软希望通过整体规划和其他调整,可以将其提升到400 MHz左右。通过这些调整,Chung希望将FPGA的使用率从35%提高到89%,并可以在ImageNet-1K基准数据集上每秒处理高达880张图像。
对于CPU-GPU测试架构,微软引用了Titan X GPU显卡与Intel的Core i7-5930K处理器配对的组合,Titan X GPU显卡具有6.1 teraflops的单精度浮点运算能力。该架构在ImageNet-1K测试中每秒可以处理4,129张图像,功率为475瓦,每焦耳每秒可达到121亿次。
Chung表示,在深度学习的集群中,CPU主要是将数据批量传输到FPGA进行处理,而且大部分都是空闲的。所以在一个专门的深度学习集群中,这些空闲的芯片虽然消耗电力,但不做任何真正的工作。Chung说:”在这个计算中,我们考虑服务器的总体功耗,但这并不完全正确,因为经常有很多任务在数据处理中心中,而且此时CPU大部分都是空闲的,你可以使用它们来进行其他工作。”
Chung指出,微软仍在使用未充分利用的FPGA,”如果我们做了一些整体布局规划和扩展设计并最大限度地利用了所有的FPGA,我们可以把它推到每秒处理大约880个图像,到时我们将会开始看到一些非常有趣的能源效率数字。”

