LZ77又叫LZ1, 是最典型的字典压缩算法,核心思想是最大限度替换信息里重复的东西。
通俗来讲,熟人聊天很轻松,是因为彼此有一个共通的内容库,讲话的时候不必事事明说,只需要“举一便可反三”。
这种思想,就是词典压缩。用histroy的数据作为共通的内容库,后面新来的内容,只需要检查历史数据看一下有出现过,要最大限度的替换现在的内容。
闲话少说。
举个例子,一串字符串:aacaacabcabaaac
用LZ77 压缩:
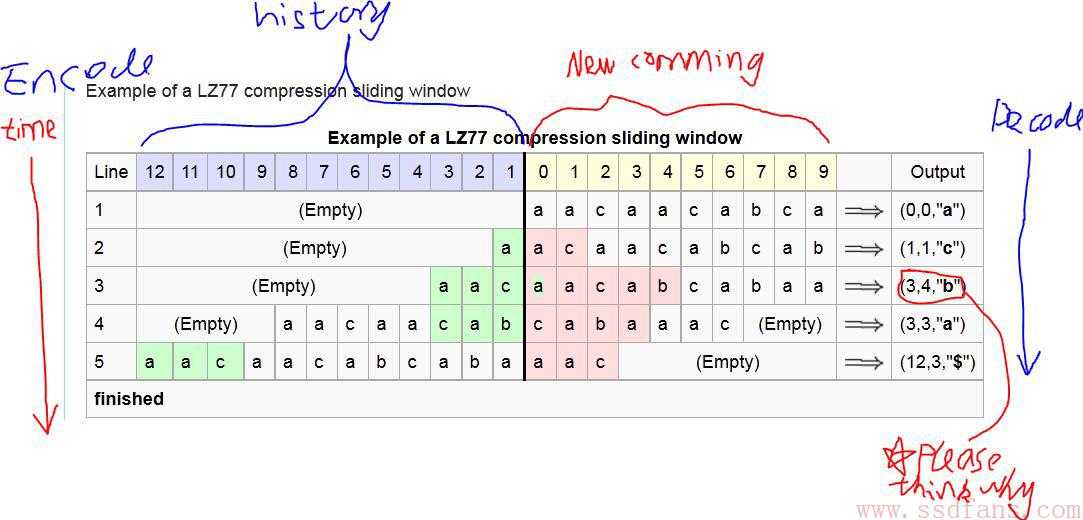
Pictrue from wikipedia, notes by ssdfans.
Output 数据结构:
(a,b,”nextstr”)
a:匹配字符串在历史字典里边(history区域)的起始位置(最左边的绿色字符位置)
b:匹配字符串的长度(绿色区域长度,并且等于红色区域长度减去1)
nextstr:在输入数据(New comming)当前被匹配位置的下一个字符(红色区域最后一个字符)
———————————-
From wikipedia:
LZ77 and LZ78 are the two lossless data compression algorithms published in papers by Abraham Lempel and Jacob Ziv in 1977[1] and 1978.[2] They are also known as LZ1 and LZ2 respectively.[3] These two algorithms form the basis for many variations including LZW, LZSS, LZMA and others. Besides their academic influence, these algorithms formed the basis of several ubiquitous compression schemes, including GIF and the DEFLATE algorithm used in PNG.
They are both theoretically dictionary coders. LZ77 maintains a sliding window during compression. This was later shown to be equivalent to the explicit dictionary constructed by LZ78—however, they are only equivalent when the entire data is intended to be decompressed. LZ78 decompression allows random access to the input as long as the entire dictionary is available,[dubious ] while LZ77 decompression must always start at the beginning of the input.
想要每天看一条SSD文章吗?扫一扫,微信关注我们!或者微信搜索公众号ssdfans关注。


