前段时间我们收到了SMI送测的NVMe主控 SM2262,主要面向于Client市场,支持8个NAND Channel, PCIe Gen3x4, NVMe 1.3。
其硬件架构如下:
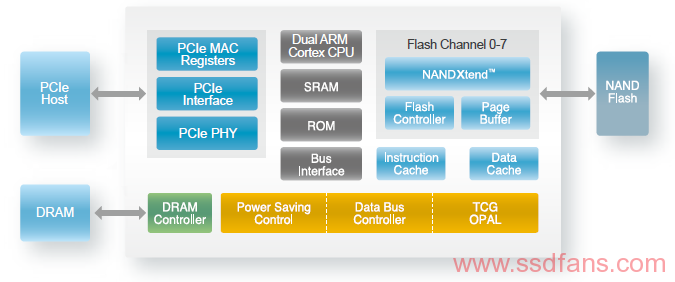
我们拿到的开发板是M.2接口,容量512GB的版本, 采用美光B16A 3D TLC NAND和南亚DDR3 DRAM (512MB)。
我们分别使用Crystal DiskMark和FIO进行了测试,数据如下:
|
官方数据 |
CrystalDiskMark |
FIO (30秒) |
|
|
Seq Read |
3200 MB/S |
3232 MB/S |
3222 MB/S |
|
Seq Write |
1900 MB/S |
1821 MB/S |
1722 MB/S |
|
Rand Read |
370K |
346K |
428K |
|
Rand Write |
300K |
289K |
264K |
从结果来看,官方数据基本靠谱。当然,这些数据只是最高性能,体现的是新盘的读写速度。
继续看稳态的性能数据,首先对SSD做了如下的预处理:
- 使用Block Size=1M进行2次全盘顺序写覆盖;
- 使用Block Size=4K进行2次全盘随机写覆盖;
完成预处理之后,使用FIO重新测试读写性能 (读写20G),性能下降非常大,尤其是顺序读性能下降了80%(这个不太合乎逻辑)
|
新盘 |
稳态 |
降幅 |
|
|
Seq Read |
3222 MB/S |
580 MB/S |
82% |
|
Seq Write |
1722 MB/S |
112 MB/S |
93% |
|
Rand Read |
428K |
229K |
46% |
|
Rand Write |
264K |
11K |
96% |
使用Block Size=128K对测试的20G空间进行了顺序写覆盖后再度进行测试,顺序读性能有了较大回升,顺序/随机写入的速度也有所提升。
|
新盘 |
稳态 (随机覆盖) |
降幅 |
稳态 (顺序覆盖) |
降幅 |
|
|
Seq Read |
3222 MB/S |
580 MB/S |
82% |
2828 MB/S |
12% |
|
Seq Write |
1722 MB/S |
112 MB/S |
93% |
212 MB/S |
88% |
|
Rand Read |
428K |
229K |
46% |
224K |
48% |
|
Rand Write |
264K |
11K |
96% |
29K |
89% |
针对随机覆盖以后顺序性能暴跌的问题,SMI配合我们在实验室也做了相关测试:
- 顺序写,随机读,随机写的性能降幅都与我们大致相同
- 但是顺序读的结果与我们有很大偏差 — 只有10%左右的降幅
|
SSDFans结果 |
新盘 |
稳态 |
降幅 |
稳态 |
降幅 |
|
(随机覆盖) |
(顺序覆盖) |
||||
|
Seq Read (MB/s) |
3222 |
580 |
82% |
2828 |
12% |
|
Seq Write (MB/s) |
1722 |
112 |
93% |
212 |
88% |
|
Rand Read (IOPS) |
428K |
229K |
46% |
224K |
48% |
|
Rand Write (IOPS) |
264K |
11K |
96% |
29K |
89% |
|
SMI结果 |
新盘 |
稳态 |
降幅 |
稳态 |
降幅 |
|
(随机覆盖) |
(顺序覆盖) |
||||
|
Seq Read (MB/s) |
3037 |
2736 |
10% |
2728 |
10% |
|
Seq Write (MB/s) |
1673 |
60.5 |
96% |
370 |
78% |
|
Rand Read (IOPS) |
372,320 |
219843 |
41% |
221757 |
40% |
|
Rand Write (IOPS) |
255,720 |
26428 |
90% |
34265 |
87% |
经过比较双方的测试流程,发现了一点不同:
|
序号 |
SSDFans |
SMI |
|
1 |
新盘顺序读,写测试 |
新盘顺序读,写测试 |
|
2 |
新盘随机读,写测试 |
新盘随机读,写测试 |
|
3 |
预处理—顺序覆盖写2遍 |
预处理—顺序覆盖写2遍 |
|
4 |
预处理—随机覆盖写2遍 |
预处理—随机覆盖写2遍 |
|
5 |
稳态顺序读测试 |
稳态顺序写测试 |
|
6 |
稳态顺序写测试 |
稳态顺序读测试 |
|
7 |
稳态随机读,写测试 |
稳态随机读,写测试 |
在预处理以后:
- 我们先做顺序读测试,再做顺序写测试;
- SMI先做顺序写测试,再做顺序读测试;
为什么在4K随机写入覆盖后的区域,顺序128K读取的性能会暴跌呢?
原因在于:FIO下发一个128K的读命令,虽然逻辑地址是连续的,但是因为之前的4K随机写入,其对应的物理地址是随机的,无法像顺序的4K物理地址读一样可以多笔共享一次physical NAND读操作,所以读速度会大幅下降。
我们正在继续稳定性以及性能曲线的测试,请关注后续文章。

