
Intel代号为Knights Landing的第二代Xeon Phi处理器配备了Omni Path高速互联接口。Intel在高速互联领域很在就开始布局,早在2012年就收购了QLogic Infiniband技术和Cray的互联技术。它的最终目标是开发Infiniband和True Scale的替代技术,能够更快,更好,更便宜。所以,Intel推出Omni-Path真是煞费苦心,不是简单的一个接口,而是完整的生态链。
互联芯片对超算的巨大作用
我们来看看美国田纳西大学计算机学教授杰克·唐加拉对中国超算的评价:虽然”天河一号”的处理器仍主要采用美国产品,但其互联芯片已全部替换为中国研究人员自主研制的产品。他说:”互联芯片主要涉及处理器之间的信息流动,对于超级计算机的整体性能起到关键作用。’天河一号’的互联芯片由中国研制,具有世界最先进的水平。”(《中国超级计算机运算速度夺冠 互联芯片自制》,http://info.ec.hc360.com/2010/11/171024365014.shtml)中国做出全球排名第一的天河一号超级计算机,自主研发的互联芯片立了大功。


为什么开发Omni-Path:一个字,钱!
Intel作为一家芯片公司,主要利润还是来自于卖CPU,所以它做很多产业链层次的事情,比如推广NVMe等,都是为了多卖CPU。在高性能计算领域,目前互联芯片和硬件的成本越来越高,每台超级计算机的预算都是固定的,所以在互联器件上投资变多,意味着Intel的CPU买的就少了。与此同时,互联网络的高成本直接推高了超级计算机的成本,购买超级计算机的门槛随之变高,买的人就少了,Intel的CPU也卖的少了。所以Intel要开发更便宜的互联网络架构——Omni Path。
下图是QLogic的True Scale控制器,以及True Scale和Omni-Path对比表。

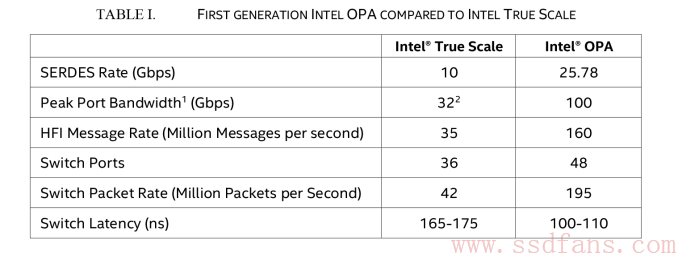
Omni-Path为什么更便宜?
减少器件数
Intel把很多分立器件集成到一个芯片里面,同时把Omni-Path控制器芯片和Knights Landing CPU通过MCM封装技术封装在一起,共享PCIe接口,未来肯定是要把他俩做成同一块芯片。集成有两大优点:降低成本+增加可靠性。
PCIe 3.0版的Omni Path板卡
Intel对于那些不买Xeon Phi处理器的客户,也设计了PCIe 3.0 Omni Path转接卡,把卡插在主板上,就能让PC连接Omni-Path设备。通过PCIe 3.0 x16或x8支持一到两个Omni-Path接口,只有PCIe 3.0 x16才能达到100Gb/s的峰值带宽。一般衡量功耗的指标叫TDP,”Thermal Design Power”,即”热设计功耗”,是反应一颗处理器热量释放的指标,它的含义是当处理器达到负荷最大的时候,释放出的热量,单位为瓦(W)。板卡TDP功耗为8W,最大负载时12W。

除了上面那款适配卡,Intel还开发了其他Omni-Path互联架构中的组件,比如48口的交换机,这样就能互联更多的设备,要知道Infiniband交换机最多只有36口。看起来仅仅是多了33%的端口,但其实在实践中却会发挥巨大的优势。我们来简单计算一下就能明白。在一个1000个节点的互连网络中,理论上来讲,最佳情况下,Omni-path节点收到其他节点的通信要求(hop)不会超过3个,而Infiniband就会达到5个,hop越少意味着节点之间相互通信要通过的交换机就越少,延迟就越短,这对超级计算机性能提升太大了。
Omni-Path互连网络架构
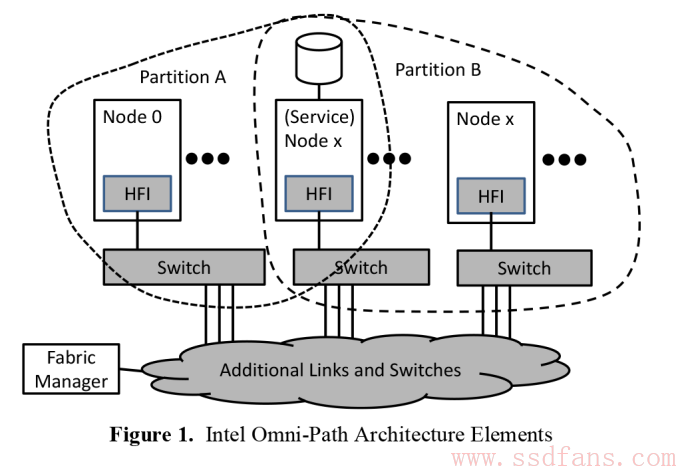
我们要知道,OPA(Omni-Path Architecture)的设计出发点是在提升性能的同时降低成本,所以有一个特点就是容错率更高,容错率高,对硬件的精度要求就不高,成本就可以省下来。硬件可以差一点,互联线缆甚至不用光纤,铜线就可以了。目标容错率是一万亿分之一,说简单一点就是以100Gb/s传输,10秒钟出错一个bit是可以接受的。
容错率这么高,是不是纠错能力就能很强才行?Wrong!其实OPA并没有用什么牛逼的纠错技术,比如Forward Error Correction之类,用的就是简单的CRC和重发机制。因为Forward Error Correction在出错后,需要发送端重新经过互联网络的一个个节点把数据包重发给目标,延迟很长,而OPA只需要出错时的两个节点之间重发,延迟很短。
OSI模型
下图是OSI模型的例子,看看我们常见的各种协议处于哪一层次。
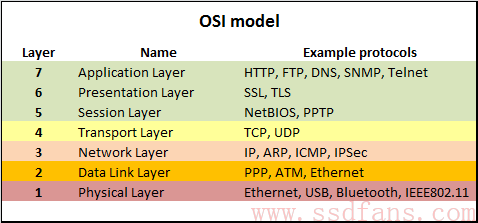
OPA并没有简单的使用OSI模型,类似于其他协议,它有个Fabric Packet (FP),是节点之间的包,但不同的是,发送的不是FP,而是下面一层Link Transfer Packet (LTP),OPA里面称为1.5层,出错的时候是在这一层完成重发。大部分工作也是在LTP层完成,1个LTP是1056 bit,其中1024 bit数据,16 bit FLIT,每个FLIT1个bit,FLIT其实就是一段数据。14bit CRC,还有2bit Intel叫做虚拟通道信用(virtual lane credit)。1024 bit的数据被拆成16个64bit的FLIT(Flow Control Digits),FLIT是数据的最小单位,一个LTP可以包含来自不同FP的FLIT,打包成一个LTP。
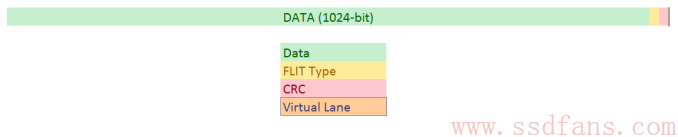
所以OPA的码率是1024/1056=64/66b,和其他互联架构类似。对于数据,Intel用了数据扰乱技术,使得奇偶校验能更好地发挥,同时也不用做额外的编码和冗余数据。扰乱其实就是把数据打乱,让有序的数据变得随机,0和1随机分布,而不是连续出现,出错的概率会降低。Martrixer的理解是频谱变宽了,噪声就降低了。
Intel还搞了个小小的超频,100Gb/s的时钟频率是25.78125Gbps,不知要求是不是25Gbps就够了。当LTP接收节点收到数据后通过CRC发现出错,就会在LTP转发给下一节点之前请求上一节点重发。如果很不幸,这一机制没起作用,那在FP层还会发现数据出错了,要求重发整个FP,相当于双保险啊!
不公平啊,数据还分高富帅和屌丝( ▼-▼ )
OPA还搞了个Traffic Flow Optimization技术,就是数据是分阶级的,高富帅数据和屌丝数据,怎么做到的呢?就是LTP里面有来自不同FP的FLIT,那么优先发送高富帅FP的FLIT,屌丝的优先级低。理论上分了32级优先级,其实一开始希望4-8级就够用了。
商业化程度
其实有很多厂家已经开始使用OPA了,Intel说已经有100个产业链厂商使用了OPA,装备了10万个节点了。当然,OPA还是和Xeon Phi处理器紧密绑定,今年我们估计就能看到产品了。

引用:
Ryan Smith, http://www.anandtech.com/show/9561/exploring-intels-omnipath-network-fabric
想要每天看一条SSD文章吗?扫一扫,微信关注我们!或者微信搜索公众号ssdfans关注。


