在国内的BAT三大互联网巨头中,目前百度市值是最低的。阿里巴巴目前股价已经攀到了110美元之上,市值超过了2800亿美金,这个数字几乎是BAT中另外两家——腾讯和百度市值的总和,其中腾讯市值为11990亿港币(约合1500亿美金),差不多是阿里巴巴的一半,而百度市值875亿美金,只有阿里巴巴的零头。
不过,在阿呆看来,百度将是这三家中活的最久的一家公司,因为它在未来的技术——人工智能方面舍得投资。最近,人工智能突然变得很火,不过要知道搜索引擎是目前我们使用最多的人工智能技术。阿呆比较关注的是百度在硬件计算方面的研发实力,在三年前就大规模使用 GPU 代替 CPU 来支持云计算,并且现在还运行了一个大规模的 FPGA 集群。阿呆五年前曾经在微软从事FPGA加速搜索引擎的研究,明白用GPU和FPGA这种硬件进行计算的巨大优势:并行性和流水线。现在最强的Intel CPU最多也就64个核心,能并行跑64个线程,但这对并行计算来讲,简直就是小儿科。GPU和FPGA能够同时有成千上万个计算单元并行计算,FPGA还能自定义计算单元的逻辑。人工智能现在名声大噪是由于深度学习技术的发现,对做算法的人来讲,深度学习的优势是识别精度提高了,但对做计算的人来说,深度学习的好处是更加适合GPU和FPGA进行海量并行计算。看过《三体》的人都可能记得三体人为了不让地球人掌握人工智能技术,封锁了量子计算的研究,而没有量子计算的人工智能就是小儿科。但是,深度学习的发明,让人类在还至少需要一百年的量子计算机来临之前,能提早享受人工智能带来的便利。
两年前,百度的欧阳剑团队在著名国际会议HotChips上做了一个报告,说明他们使用FPGA做DNN计算的结果。我们一起来围观。
首先我们来看看百度的家底,它目前有几十个数据中心,几十万台服务器,超过1000PB的数据量。也不知道这1000PB有多少是网友上传的小电影,毕竟互联网上的数据,排名第一的是视频,第二是图片,其他的就是零头。这么多的数据放在那里就得利用起来,所以要经常分析一下,就是发现商机。我们看到百度每推出一个新产品,其实就是通过自己的数据发现网友有这方面的强烈需求,比如百度知道,百科,文库等等,目的就是要让你进了百度搜索,就留下来,别走了,你想要的这儿都有。
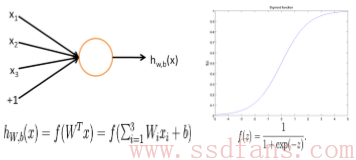
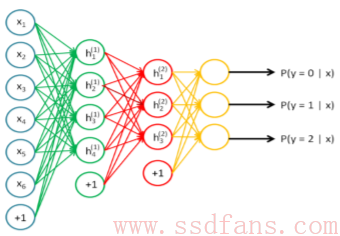
百度常用的一种数据分析技术叫做DNN:深度神经网络。这个东东可以做语音识别,图像搜索,图片文字提取,人脸识别,广告,搜索,自然语言处理等等,基本上百度的大部分服务都能涉及到。DNN是深度学习的一种,所谓深度学习,就是把计算分成很多层,每一层都不太复杂,算出一堆理论上也说不出来的东西出来,但是有个人摸索了几年,换了各种模型,发现一层层搞下来,最后算出来的东西居然还很有用:做图片分类和特征识别等精度比现有算法高多了。如下图,上图是传统神经网络,一些参数算出一个值,下面是DNN,分层计算,每层提取一些特征,最后一级的输出用分类器来筛选一下,得到需要的结果。现在搞深度学习研究的很多人的工作就是调整这个模型和参数,使得能用在自己的特殊应用领域。
DNN分为两块工作:
- 线下训练,就是搞一大堆数据,在设计的模型上按照训练算法各种算,最后得出一套最合适的参数,这就是机器学习:给机器一个框架,机器自己算出需要的结果。在百度的系统里面,训练的数据集是10TB-100TB,需要得到的参数有1千万到1千亿个。需要用一百多台机器组成集群,搭配GPU,同时用InfiniBand相互高速通信,才能搞定这个计算量。集群之间需要高速通信,所以不好扩展。
- 线上预测。直接拿训练好的参数来应用,比如语音识别和图片分类等等。用户量从几千万到几亿,每天要经受几亿甚至几十亿次使用。这种应用,机器之间相互通信比较少,适合扩展。所以集群规模比较大,几千台到几万台,搭配的CPU有AVX或者SSE指令集,AVX是SSE的扩展,SSE扩展了很多浮点运算的指令。服务器之间用万兆网卡通信。
可以看出,训练和预测都是计算密集型。训练数据量大,计算时间很长,阿呆以前试过小数据量单机做training,算个几天都正常。在百度的数据规模下,有时有训练时间达到几个月。但是百度这种公司业务多,需要算的任务很多,大家不可能什么应用都配个几百台机器的集群。线上预测是直接给用户使用的,对速度要求很高。目前有几种方案:
- GPU:功耗高,几百W很正常,高端GPU成本也不低,同时个头大,占地方,最重要的是数据中心需要增加散热和供电的能力,这个可不简单。
- CPU:性能不行,不适合并行计算。
- ASIC:研发和流片费用高,周期长,同时逻辑不能动态调整,不适合互联网公司,毕竟各种应用的算法总是在变化。
- FPGA:功耗低,一般低于40W。中端FPGA成本低,几百美金。自定义逻辑,也可以动态调整。
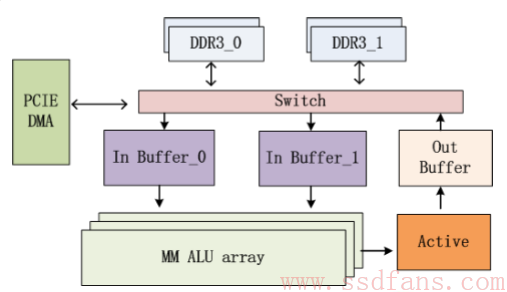
FPGA研发时间比GPU长一点,同时浮点处理器占用逻辑资源相当多,而DNN需要大量的浮点运算。还有一点是内存带宽没有GPU高,差好几倍。所以百度搞了个自己的FPGA计算平台:SDA,software Defined Accelerator. 计算能力达到400Gflops,就是说每秒能做4千亿次浮点运算。使用中端FPGA芯片Xilinx K7 480t,功耗不到30W。个头也不大,半高半长,1U服务器也能放,要知道很多GPU是全高全长。配4GB DDR3内存和PCIE2.0x8接口。实物如下图,还配个骚人的小花线,看起来是给风扇用的。

百度自己开发了浮点乘法器和加法器,比标准IP省了一半资源。架构图如下,软件上有矩阵乘法的API,同时API有点类似Nvidia的CUBLAS库。
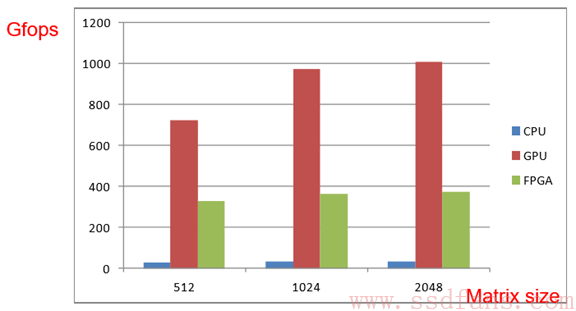
最后,和Intel E5620v2x2 16核CPU以及一个服务器级GPU作比较。FPGA搭配640个乘法器和640个加法器,运行频率300MHz。先看矩阵乘法。GPU胜出,毕竟核多,再多的乘法也不怕。
功耗还是FPGA给力,1W的电量算出最多的东西。

来看看实际工作能力,DNN的线上预测,上面的图数据量小,下面的图数据量量加大。看得出来,FPGA的处理能力是GPU的好几倍。
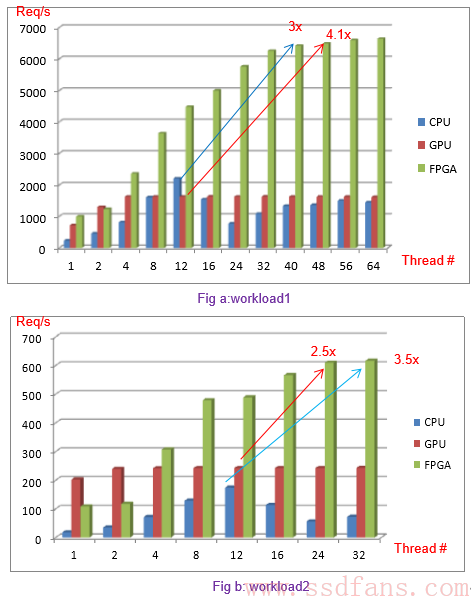
证明结果:搞DNN,FPGA比GPU牛!
引用:

