眼下最热的技术莫过于人工智能了,很多大公司都开始布局。比如老牌PC厂商联想最近聘请原微软亚洲研究院常务副院长,人工智能科学家芮勇担任CTO,他说,联想正在进行” from device only to device + cloud powered by AI”的转型,而这些新型智能设备都是联想为迎接”设备+云”的未来时代所做出的创新尝试。随着芮勇的加盟,他将进一步加大对人工智能相关性人才的引进和研发投入,从而开启联想发力人工智能的新篇章。可以看出,首先进入物联网时代之后,人工智能有着迫切的需求,各种空调,冰箱,汽车,手机,手表,家电等设备需要更加智能,同时也要能够对云端大数据进行分析,挖掘信息中的规律。其次,人工智能在深度学习技术被发现之后,发展突飞猛进,因为深度学习一下子提高了机器学习的精度。但是深度学习对计算的要求很高,所以目前是硬件落后的计算能力限制了深度学习的大规模推广。

曾经的人工智能是比较简单的,针对某一个领域的问题,由熟悉这个领域的人依赖自己的专业知识,使用已知的公式或者模型,从数据中通过分析获得规律。但是现在,人工智能面临着越来越复杂的问题,比如人脸识别,语音识别,医疗诊断等,这些没有现成的公式或者算法来解决。2006年,潜心研究人工智能几十年的Geoffrey Hinton教授(上图中的老大爷)提出了源于神经网络的深度学习技术,很快吸引了大家的注意。维基上说Hinton爸爸的爷爷是Boole,这个人提出了码农最熟悉的Bool代数。看来也是出生于书香门第啊。
对硬件计算来说,深度学习有以下优点:
- 数据并行:图像或者视频中像素或者区域上进行的计算可以并行,而且目前流行的办法不是一次处理一整张图,而是切成很多小块进行处理,小块之间相互独立计算;
- 流水线操作:深度学习分很多层计算,层与层之间可以流水线操作,就是一层计算做完,数据集体跳到下一个计算单元,空出的位置留给后面的层继续算。
并行和流水线都是硬件的优势,为什么?其实我们的CPU一般单线程程序都是顺序执行,时间比较长,但是只用一个ALU。而用硬件做计算,它最擅长的就是用空间换时间(蒋介石抗日的大战略),把计算任务分成很多并行和流水线的小任务,大家同时进行,性能翻成千上万倍。举个例子,汽车过收费站,为了加快通关速度,同时开很多个车道,这个叫做并行。每个车道里面把验车、收钱、找钱、开门分成四个任务,安排四个人流水操作,这个叫做流水线。
传统上,硬件计算有两种选择:通用处理器和定制芯片。前者不太灵活,性能差,后者成本太高。而FPGA因为可编程的特征,介于二者之间。目前FPGA市场85%的份额都在Altera和Xilinx两大巨头手里,整个FPGA市场是100亿美金量级。首先CPU 做深度学习实在是差了点,并行性太弱。比较常用的是GPU,所以我们来把GPU和FPGA做个比较。GPU的架构是成千上万个并行处理单元,如下图,要用GPU做计算,就是要对算法进行重构,使得能够分解为很多个并行小任务,平摊到GPU的每个核心去执行。

而FPGA就不需要为了特定架构去改算法,因为它是定制逻辑,直接把算法转成硬件逻辑。但是FPGA也有两个缺点:
- 编程语言Verilog或VHDL需要硬件逻辑基础,需要你懂时序图,能调时序;
- 编译综合和布局布线比较久,一般稍大一点的工程要几个小时。
所以FPGA厂商开始支持程序员友好的语言:OpenCL,它跟Nvidia的CUDA有点类似,就是个并行程序编程语言。只不过CUDA是Nvidia自家的,OpenCL是开源,免费的,由Khronos组织负责维护。目前Xilinx和Altera都有OpenCL的开发包SDK,支持在自己芯片上编程。OpenCL的核心叫做kernel,就是把计算分成很多个叫做kernel的小单元并行计算,至于kernel里面是什么自己定制。尽管硬件编译时间久,但是深度学习的特点是算法修改后,很多kernel是不变的,所以增量编译就很快。
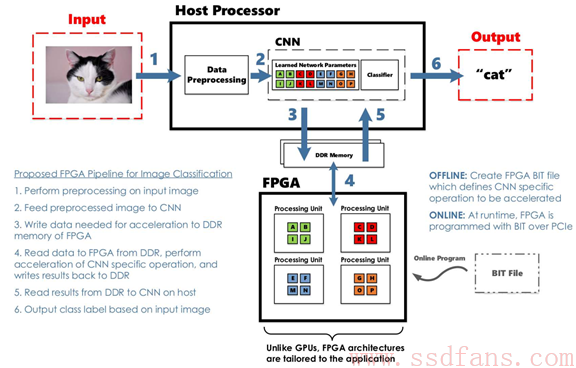
上图是一个FPGA来做图像分类的例子,一次分类分以下步骤:
- CPU做图像预处理,主要是图片调成标准格式;
- 图像送到CNN;
- 把需要硬件加速的数据写到FPGA的DDR内存;
- FPGA对数据进行硬件加速,结果写回到DDR内存;
- CPU把结果读到主机;
- CPU对结果进行分类并输出:原来是一只猫猫!
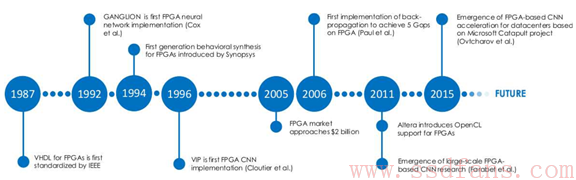
看起来FPGA现在才和人工智能缠缠绵绵,但其实他俩很早就有染了。下图是八卦妓者记录的时间表。看得出来,1992年就有人用FPGA做神经网络加速了。但是那时候FPGA性能不行,到现在,已经有人跑出了很高的速度。比如微软的研究员Ovtcharov用FPGA做卷积神经网络CNN,基于ImageNet 1K数据集,每秒处理图像134张,使用了一块Stratix V D5 FPGA,功耗25W。但是如果用更牛的Arria 10 GX1150 FPGA,能在同样功耗下实现每秒处理233张图。同样的计算,高性能GPU的结果是每秒500-824张,但是功耗却达到235W,差了10倍!微软使用了自己开发的FPGA板卡和服务器,打算放到数据中心,来提升搜索引擎性能。还有很多人发表论文,使用FPGA来做深度学习的各个方面和领域,不仅是分类,还有训练。
展望未来,深度学习进一步普及,需要硬件能力的提升。所以很多硬件厂商纷纷出动,比如Intel收购了Altera之后,今年8月又收购了深度学习初创公司 Nervana Systems,交易金额据传约为 4.08 亿美元,Nervana 由原高通神经网络研发负责人于 2014 年创建,拥有目前最快的深度学习框架,并且预计于明年推出深度学习专用芯片,号称速度比 GPU 快10倍。深度学习算法更新换代很快,通用深度学习处理器要想通用又有高性能很难。FPGA的优势是很明显的,算法可定制,同时有很省电。FPGA最适合部署在深度学习集群中,每个节点配若干块,占用空间小,同时不增加数据中心的供电和散热成本。还能配置服务器的其他计算功能到FPGA,比如索引数据存储,KV存储,固态硬盘控制等。
目前最需要的就是FPGA的开发工具更加简单,编译速度更快,方便更多硬件小白使用。
想学习用OpenCL搞深度学习的可以关注一下项目:
- Caffe:目前最主流的工具;
- Torch:用Lua编写的计算框架,有个CLTorch项目支持OpenCL;
- Theano:也支持OpenCL;
- Deep CL:一个支持深度卷积神经网络的OpenCL库。
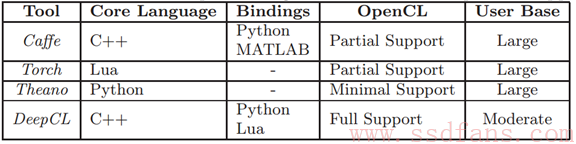
它们对OpenCL的支持如上表。Caffe用的人最多,资源也多,最适合初学者。
引用:
Deep Learning on FPGAs: Past, Present, and Future;Griffin Lacey等,University of Guelph

