很多人认为本轮人工智能热是因为深度学习算法的推出提升了机器学习的效率和精度,但真的仅仅是这个原因吗?阿呆列出一些大事记你就明白了:
2004年加拿大先进研究院 (Canadian Institute of Advanced Research, 简称 CIFAR)出资一千万加元资助多伦多大学57岁的穷教授Geoffrey Hinton组织的团队进行神经网络研究;
2006年Hinton发了一篇论文,提出现在深度学习算法的基本架构;
2012年底,Hinton 教授和他的两个研究生成立了一个名叫 DNNresearch (深度神经网络研究)的公司,三个月后就被谷歌以五百万美元收购;
2013年底,Hinton的高徒,在纽约大学教书的Yann LeCun, 2013 年底被Facebook聘请负责人工智能研究院;
2014年5月,人工智能科学家Andrew Ng被百度聘为首席科学家;
2016年11月,人工智能科学家,前微软亚洲研究院常务副院长芮勇出任联想集团高级副总裁兼CTO。
可以发现,2006年Hinton教授就已经提出深度学习算法了,学术界此后一直有很多人从事这方面研究,但是人工智能热却在6年后的2012年开始被工业界掀起。所以,必然是2012年发生了一件重大的事,使得深度学习从教授们的游戏变成工业界的宠儿。
2012年到底发生了什么?这必须要追溯到2009年,一群普林斯顿大学计算机系的学者建立了第一个超大型图像数据库ImageNet,供计算机视觉研究者使用。最初包含三百二十万个图像,它的目的,是要把英文里的八万个名词,每个词收集五百到一千个高清图片,存放到数据库里,最终达到五千万以上的图像。从2010 年开始,以 ImageNet 为基础的大型图像识别竞赛ImageNet Large Scale Visual Recognition Challenge 2010 (ILSVRC2010) 每年举办一次。竞赛的规则是:以数据库内几百万张图像为训练样本对机器进行培训,再用于五万个测试图像分类,如下图,给每个图片加个最接近的标签,比如老虎,狐狸之类,看看机器对图像的分类是否准确。

在2010和2011年两年,比赛的冠军使用的算法都是使用类似于支持向量机(SVM)的算法,这是一种设计非常精巧的算法。但是2012年,Hinton 教授和他的两个研究生 Alex Krizhevsky,Illya Sutskever (下图中三位)决定参赛,他们把将深度学习的最新技术用到 ImageNet 的问题上。他们设计了一个八层卷积神经网络的深度学习模型,使用了 两个 Nvidia 的 GTX 580 GPU (内存 3GB, 计算速度 1.6 TFLOPS),让程序接受一百二十万个图像训练, 花了接近六天时间。经过训练的模型,面对十五万个测试图像时,预测的头五个类别的错误率只有 15.3%,在2012年 ImageNet 的竞赛三十个团队的测试结果中,稳居第一。所有其他团队,采用的都是支持向量机技术,其中第二名错误率则高达 26.2%!
2012年十月十三日, 当竞赛结果公布后,学术界沸腾了!这是神经网络二十多年来, 第一次, 在图像识别领域, 毫无疑义的, 大幅度挫败了别的技术。其实不只是学术界,工业界更激动,看到了人工智能实用的曙光。所以,就有了开头那些事件,请相信,人工智能的大跃进,在未来一二十年内,将会深远的影响我们的生活。类似的例子,上次是互联网。

可以看出,人工智能大热表面看起来是深度学习算法的推出,但实质上是硬件架构的革命,使得本来看起来很笨拙耗时很久的多层神经网络算法能够短期内完成训练,反而比设计精巧的支持向量机识别精度更高。在人类历史上,这种现象不断重演。举个例子来说,在有史记载的大半个人类历史中,最强大的军事力量莫过于草原骑兵,从匈奴、鲜卑、突厥、大唐、契丹到一统欧亚的蒙古骑兵,几十万人就可以征服数万里的疆域。但是,近代以来,火枪、大炮和汽车的发明使得本来突击性没有骑兵强的步兵战斗力更强,以至于在北洋时期军阀徐树铮率领仅仅8000名装备现代武器的普通士兵就收复了在沙俄和日本怂恿下妄图独立的外蒙古。而这件事,在两千年前的汉武帝时代,却动用了举国之力,三代皇帝上百年的长期战争才实现。
目前适合深度学习的计算架构主要有GPU、FPGA和深度学习专用处理器几种。
在介绍硬件架构之前,阿呆要先来介绍两种架构类型:数据密集型和计算密集型。前者是指要频繁从内存、硬盘读写很多数据,比如我们平时看上网看小电影,文档编辑等,这些功能要求数据访问速度要快,对CPU的要求就是缓存得够大。后者是指进行很多计算,比如玩极品飞车等大型游戏,各种效果都是硬件算出来的,这个需要CPU频率高、核心多。
Intel的CPU设计的很复杂,配几十个核心,运行频率高达几GHz,每个核心有自己的缓存,CPU内还有一级、二级、三级缓存。如上图的CPU照片,缓存占了大部分面积。
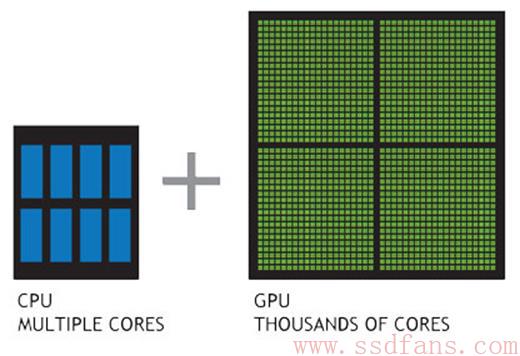
GPU是目前科研领域比较常用的硬件计算工具,因为它编程语言简单,上手快。下面这张图显示了GPU为什么快:计算核心数是CPU的几百倍!它就是把几千个计算核心塞到一个芯片里面,运行频率尽管只有几百MHz,但是核心多,整体性能好。一个猛张飞也打不过几百个小兵啊。所以,GPU比较适合计算密集型应用,比如打游戏、搞深度学习。而CPU的缺点就是太通用了,数据读写和计算两种功能都得照顾一下,反而搞得自己在计算方面被GPU甩几条大街。
在介绍FPGA之前,阿呆又要科普一下一个计算架构的术语:粒度。在深度学习出现之前,搞计算机体系结构研究的学者们是很无聊的一帮人,因为这个领域的创新实在是太少了,架构玩来玩去就那么几种。但是论文还是得发,要不怎么混口饭吃呢?所以他们发明出了很多行内的黑话,让外面的人以为他们有很多科研创新。比如粒度就是其中之一,它的意思就是计算核心的大小,大的叫粗粒度,小的叫细粒度。粒度大了,单个性能好,也好管理,但是有时候有点浪费,因为不需要这么大的粒度。粒度小了比较省资源,比较灵活,但是不好管理。比如公交车和地铁高峰时段装的人多,但是非高峰时间上座率低,比较浪费,乘客还必须大老远跑到车站去等车。出租车和电瓶车、摩拜单车送客户到家,很灵活,不过高峰时装的人少,车多了马路上乱糟糟的,不好管理。只要你写论文,这两个概念总得提一下,显得很时髦(蛋疼)。阿呆以前从事过这份工作,发论文写过不少行话。不过,当深度学习热潮起来的时候,最兴奋的莫过于搞计算机体系结构研究的人了,一下子从养老院变成了忙忙碌碌的发改委:终于可以干点正事了,不用整天琢磨新名词。各大计算机体系结构的国际顶级会议都变成了机器学习体系结构学术会议。
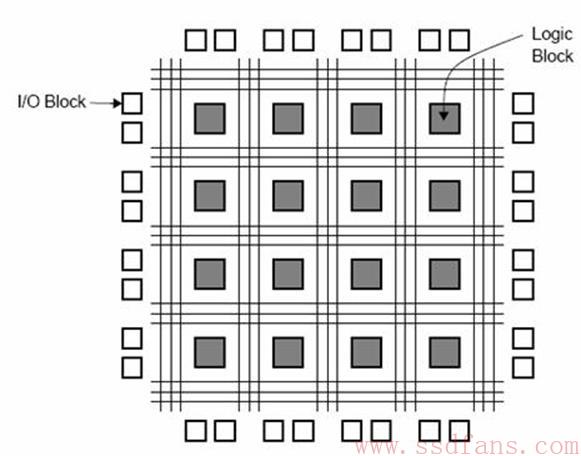
GPU属于粗粒度的并行处理器,FPGA相比GPU就是细粒度的并行处理单元。如下图,FPGA是可定制逻辑的芯片,逻辑的粒度细到与非门。它里面的最小单元是逻辑单元,你可以来实现与非门等最基本的逻辑,最后用很多个逻辑单元搭建出复杂的逻辑。现代FPGA包含几百万个逻辑单元,还有几千个乘法器硬核和几十Mb的缓存。你如果水平够强,理论上可以用FPGA搭出CPU或者GPU。
最后出场的就是深度学习专用处理器,目前有很多创业公司都在做这方面的芯片。不过可喜的是,这回中国也和世界同步了。有人说,以前是美国人原始创新,发明一个高科技,赚第一桶金;接着,日韩企业跟进,做精,卖到全世界,不过也是中产阶级才能用的起的;最后,中国企业来山寨,价格超低,做成了大路货,亚非拉美普通人民都能享用。但现在,美国人一有概念,中国就开始大量制造了,价格又低,质量又好,比如平衡车、VR等。在上一个十年,中国企业经过艰苦努力,直接抢了日韩制造企业的空间,按照兔子的未来规划,下一个十年中国的目标是高端制造,比如半导体、大飞机、尖端军工、高铁、新能源、量子通信等,意味着要抢美帝的高科技了。
在人工智能算法领域,2015年ImageNet比赛中,中国科技大学和微软亚洲研究院联合培养的博士任少卿等人开发的算法夺冠,把图像分类的错误率降低至4.94%,要知道人眼辨识的错误率大概为5.1%,意味着在看图片这方面机器比人强了!
在人工智能专用芯片方面,我们看新闻知道Google推出了机器学习专用芯片TPU(Tensor Processing Unit)。
Intel 收购了一家致力于机器学习、深度学习的新创公司 Nervana,增强公司生产的 Xeon CPU在深度学习方面的表现。
在中国,同步的出现了几家人工智能芯片厂商。首先最引人注目的是中科院计算所的”寒武纪”人工智能芯片,由中国科技大学少年班毕业的两位天才少年陈云霁和陈天石主导开发,在世界上首次提出深度学习处理器专用指令集DianNaoYu。
另外资本市场比较抢眼的是原百度深度学习研究员负责人余凯创办的地平线机器人科技,他们的目标是商业化的人工智能芯片,实现自动驾驶等功能。
硅谷团队Kneron的提供深度学习算法给芯片公司,应用到智能安防,辅助驾驶等领域,卖的是授权费。
几位清华大学老师和校友创办的深鉴科技目标是开拓人工智能的应用边界,开发压缩、编译、加速三位一体的自动化流程, 实现算法、软件、硬件协同优化,打造更小,更快,更高效的深度学习DPU平台。其实就是通过编译器和算法的优化,使得芯片能多快好省地跑某个领域的深度学习算法。
最后,来总结一下。
GPU是目前最常用的深度学习工具,优点是上手快,开发简单。缺点是个头大,全高全长,而且比较耗电,比如下面这个GPU服务器,里面有8块GPU,目前Nvidia的Tesla GPU每个功耗在250W以上,所以这台机器跑起来功耗至少在两千瓦,如果1度电1块钱,开一年电费要17520。这还不包括空调费用,如果制冷成本是功耗的一半,那么一年的费用在两万五千人民币!

FPGA的特点是功耗低,尽管价格比GPU贵,但是电费少,总体还是划算的。性能方面通用算法性能比GPU稍差,但是经过优化后差不多。因为不需要为了制冷重新设计,所以比较适合数据中心大规模部署。最后就是开发比GPU复杂一些,不过在OpenCL普及,FPGA厂商对OpenCL支持能力提升后,开发难度也会降低。
最后,各种人工智能专用芯片的目标还是特定领域,比如安防监控(举个例子:满大街的摄像头自动识别通缉犯),智能驾驶等等。
引用:
王川:深度学习有多深?学了究竟有几分?

