
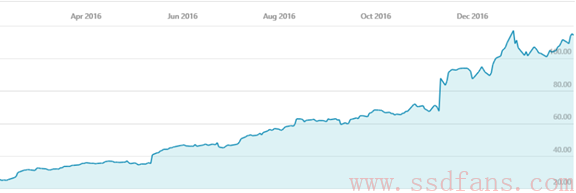
在过去的一年里,NVIDIA的股价从26美金一路疯涨到了114美金。如下图。
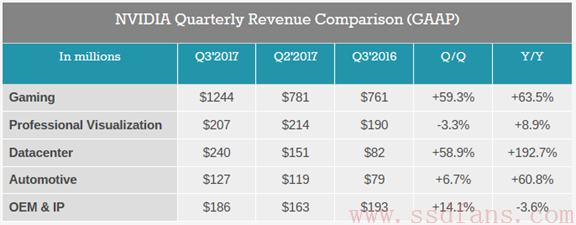
不只是各种概念让人对未来充满期待,这家公司赚钱能力也很强,去年第三季度的财报发布之后,我们来看看最近的增长情况。如下表,是ANANDTECH整理的最近三个季度各个业务收入增长情况,很明显,游戏是最大头。不过很显眼的是数据中心业务,年度增长率达到192.7%!所以我们可以明白为什么NVIDIA这么不遗余力地推广深度学习应用,这个市场的未来太大了。
阿呆之前就说过,本轮人工智能热的幕后推手是硬件架构革命。其实从产学研层次来讲,深度学习有三个方面:
- 研究层面:不断提出新算法和框架,提升精度和速度。这方面主要是各路科研人员在努力,目前最火。
- 应用层面:把AI技术深度应用到我们生活中的方方面面,比如辅助驾驶,智能监控,语音识别等等,这个比较艰苦,但是市场很大。想想移动互联网当前的市场有多大就能理解了。尽管未来市场很大,但是现在很多公司都是雷声大,雨点小。需要时间的磨砺和经验积累。阿呆以前听过罗格斯-新泽西州立大学熊辉教授的一个报告,他说大数据分析中,在某个领域中的经验非常重要,需要长期积累,否则,仅靠机器很难充分挖掘海量数据中的有效信息。人工智能也是如此,只有在一个行业中有长期的应用积累,才能利用该领域数据实现智能化。所以,该行业的创业公司要能够熬得住,活下来就有希望抓住机遇。
- 硬件层面:推出适合人工智能计算的各种硬件产品,如GPU,FPGA,专用芯片等。这个是当前真的能赚钱的领域,因为可以直接应用到已经成熟的行业中。硬件赚钱靠的是量,只有量大了,才能摊薄成本,提升利润率。在安防,驾驶,数据中心等成熟行业中,人工智能硬件需求量很大。
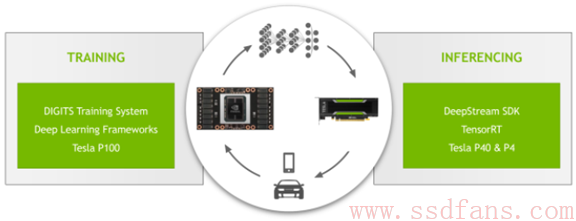
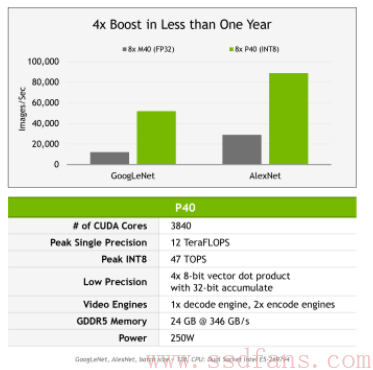
本文我们来看看NVIDIA最新的Tesla GPU,专门用来做神经网络预测计算,就是根据训练好的模型直接计算来分析用户数据,最新的GPU是P40和P4。另一个计算叫做训练,对应的GPU是P100.它俩什么关系呢?就是训练是用已有的数据集算出最合适的模型,预测是使用模型实时计算最新数据。训练对精度和计算能力要求高,一般是16位浮点,Tesla P100具有超强16位浮点计算能力。而预测对精度的要求稍微低一点,甚至8位整型就够了。下表是上一代产品Maxwell架构的M40和M4与Pascal架构的P40,P4对比。1个32位浮点核心能做4个8位整型运算。
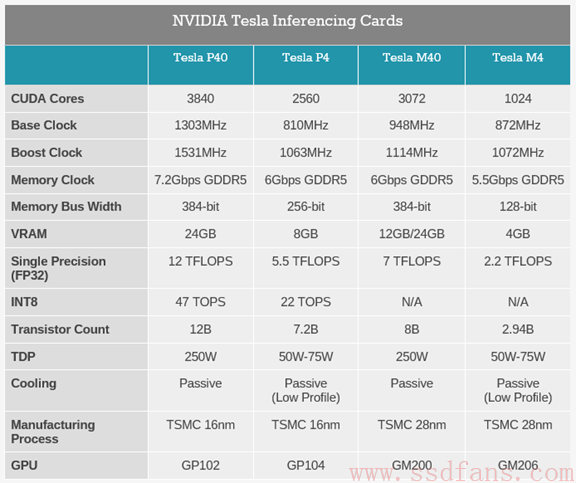
据称,新平台在GPU集群中能提升4倍性能。P40有3840个CUDA Core,P4有2560个。P40的定位是高性能服务器,功耗250瓦,P4用在刀片式服务器,功耗50瓦或75瓦。
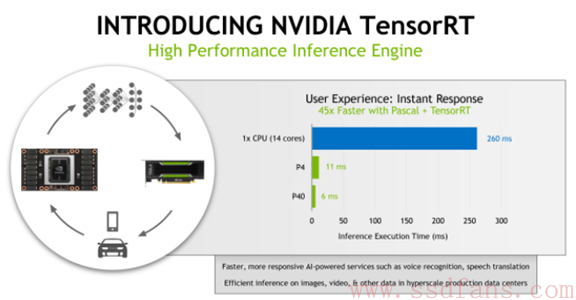
NVIDIA还提供了两个软件工具:TensorRT库和软件开发包DeepStream SDK。TensorRT是NVIDIA推出的库,主要是帮助开发者把已经训练好的16位和32位的浮点神经网络模型移植到8位整型架构,这样能提供翻2倍或者4倍的计算能力。
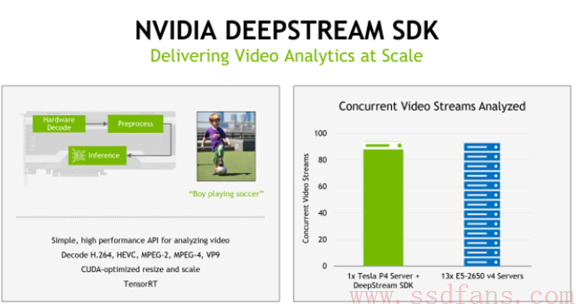
DeepStream是视频处理库,使用TensorRT库和GPU内部的解码器,来快速解码和分析视频。之所以推出这个,是因为深度学习目前的一个重要应用就是视频实时分析。
人工智能硬件大战才刚刚开始,未来几年我们将看到各种巨头和新创公司的创新产品。吃瓜群众请准备好小板凳,等着看好戏。

