作者:李大虾

dvsFTL
在不影响其他Nand要求的情况下,提高Nand持久度而设计的基于DeVTS的FTL叫dvsFTL。基于Nand持久度模型,动态改变擦除尺度模式和写性能调整模式。
dvsFTL架构如下: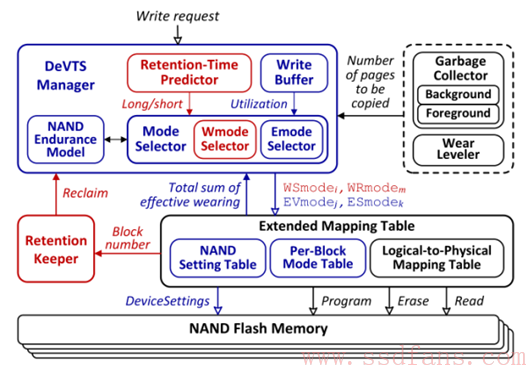 DeVTS Manager是关键模块,它选择最合适的擦除尺度模式和写性能调整模式,以达到给定写请求的性能和保持力的要求。
DeVTS Manager是关键模块,它选择最合适的擦除尺度模式和写性能调整模式,以达到给定写请求的性能和保持力的要求。
写性能要求的write-speed mode(WSmode)和erase-speed mode(ESmode)根据write buffer来估算。
保持力要求的write-retention mode(WRmode)通过retention-time predictor来预测。
DeVTS Manager通过选择写性能调整模式决定erase-voltage mode(EVmode)。
retention keeper周期检查写入数据的剩余retention时间,如果到期就重新写入到另一个Page。
mapping table除了logical到physical的地址映射信息还会额外存放每个block的mode信息(比如erase/write mode和ΣEW)。
注:可以通过Device Setting来配置不同Nand Device的write/erase mode。
-
Write-Speed Mode选择
最适合的Write-Speed Mode:在可变的write-mode中存在最慢write-mode,但不影响整体性能。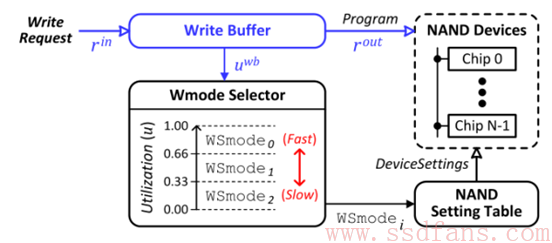 DeVTS manager里面的Wmode selector通过使用上图中的uwb评估给定写请求的写性能要求,uwb在运行时反应从系统host端到来数据速度rin和写到flash里面的速度rout的差,因此rin<rout,uwb会减少,在这种情况下就不用最大化写性能(可以适当慢写)。相反,rin>rout,uwb增加,则要求尽可能快的写。
DeVTS manager里面的Wmode selector通过使用上图中的uwb评估给定写请求的写性能要求,uwb在运行时反应从系统host端到来数据速度rin和写到flash里面的速度rout的差,因此rin<rout,uwb会减少,在这种情况下就不用最大化写性能(可以适当慢写)。相反,rin>rout,uwb增加,则要求尽可能快的写。
图中设置了三级写性能要求,uwb小于0.33时候,从buffer写到nand page使用WSmode2(最低写入速度);uwb大于0.66时候,使用WSmode0最快写入速度。
当Garbage Collection发生时候,rout会明显减少,例如GC操作50%的Nand空间,rout会减少50%,如果rout降到rin以下使uwb增加,最快写入模式能缓解GC带来的影响。
-
Write-Retention Mode选择
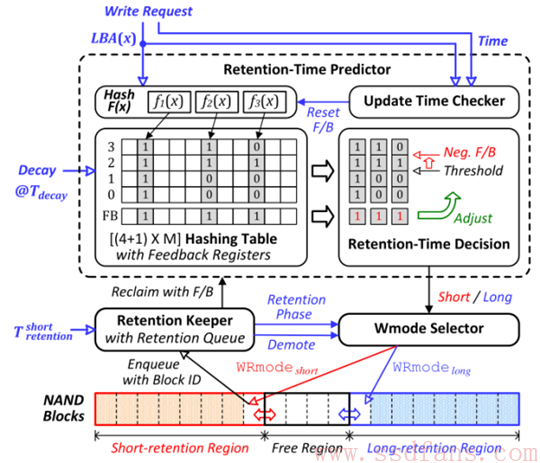 Wmode selector为给定预测未来更新时间的写请求提供最适当的write-retention mode。
Wmode selector为给定预测未来更新时间的写请求提供最适当的write-retention mode。
首先在预测的周期内执行,这个时间要比Nand设备本身的短很多,Wmode Selector就会选择WRmode short来执行。当预测未来retention时间要求不正确,reclaim程序被调用,用来保护数据的持久性。然而太过频繁的reclaim操作会降低retention的能力,因此要减少reclaim page的数目和overhead reclaim。
我们从两个层面上解决上述问题:retention时间预测的资源优化和retention管理的技术要求。
(1)Retention要求预测:
依据:最近请求的平均更新间隔
实现:每当一个LBA的写请求发生,该LBA映射的多维计数器增加。为了更新间隔和预测最短保持时间比较,所有计数器必须在指定的时间内减少。比如更新间隔短语预测最短保持时间,则计数器值增加,相反减少。多个周期后,计数器值大于预设的阈值,保持时间预测器认为最近更新间隔平均要短于预测最短保持时间,也就意味着最近该写请求更新频繁,可以用空间局部性原理改善。
技巧:为每个LBA设计计数器实在是太浪费,如图所示,使用3个hash函数仅保留有限个计数器。这个技巧值得仔细研究一下。
(2)最大化Endurance效果:
这个就要求减少误判断了,降低reclaim。
误预测控制:hash冲突是误预测的根源。如图所示,hash冲突无意的增加了cold data的计数器,因此会被认为是短保留数据,这种数据被定义为false-short,最终被reclaim。
误预测控制,就是如图所示增加反馈寄存器,检测数据被reclaim就设为1,依次来阻止后面出现的连续误预测。如果反馈寄存器都被设置了1,retention-time predictor就会增加决策阈值水平。
例子:一个写请求的计数器值为15、12、4,假设预测阈值是4,但所有反馈寄存器位为1,这个写请求被认为是长保留数据,因为预测阈值会被从4提高到8。
如果预测正确(例如写到短保留时间会在最短保持时间内更新),反馈寄存器会被重设为0,并且预测阈值恢复正常。
选择性保持调整:当太多的page被reclaim,就要暂停保持能力调整。
例子:假设每个block有100个page,组合WRmode short和WSmode0写5000个page,首先50个block会在EVmode 2被擦除(有效的wearing是0.59),根据原理部分介绍,保持力调整写的总endurance收益在20.5(=(1-0.59)*50)。每个block的60个page会被WRmode long reclaim的话,在reclaim期间就有30(=60*50/100)个block会被EVmode 0擦除。因此reclaim写导致总的endurance失去部分是23.4(=0.78*30)。所以失去要比收益的大。
因此就不能用short-retention的写模式,这就要求计算收支平衡点。对于例子来说,每个block的收支平衡点reclaim page数目在52.6(=(1-0.59)/0.78*100)。retention keeper会持续地监控每个block的平均reclaim的page数目,当大于这个收支平衡点,就会暂停保持能力调整,忽略保持时间预测,选择WRmode long的模式。如果小于就重新启动保持能力调整。
(3)最小化Reclaim Overhead:
由于比较难的预估误预测,就有了最小化reclaim overhead的需求。reclaim目标是保护WRmode short存储的数据耐久性,在deadline到期之前为了可靠的重写误预测的数据,retention keeper会周期地检查剩余retention时间,这也是一件很消耗系统资源的程序。因此设计了一个简单有效的reclaim技术:
如图所示,设置两个区域,一个是short-retention region,另一个是long-retention region;当要写short-retention的数据,会从free block region选择一个free block id和写入时间插入到retention keeper的retention队列中。虽然这个block的后面写入时间不同,但是用第一个写入block的时间作为该block的最差dead-line是很好的选择。retention队列可以选择FIFO的方式,每个block的剩余retention时间就是自动的升序排列,方便检查。当retention keeper检测到某个retention dead-line到了,错误预测的page所在的block在reclaim过程中变为free block,并且使用WRmode long将数据写到long-retention region。
-
Erase-Voltage模式选择
选择合适的erase-voltage是dvsFTL的关键,使用EVmode5(最低erase-voltage)可以增大Nand endurance,此时必须选择WSmode2(最慢写模式),这时写的性能退化明显。
如果reclaim的时候,EVmode5模式用于近期会被更新的hot data block,浅擦的block会被cold data写,这样endurance收益就会变得很差。当全部使用EVmode0(最高erase-voltage),维持全部的write-performance也达不到潜在的性能。因此评估未来写请求的要求,同样是选择正确的erase-voltage模式的关键步骤。
前台GC过程,Wmode selector会选择接收到的写请求的write-speed和write-retention模式,被擦除块会选择NAND endurance模型中相对应的erase-voltage。比如∑EW小于0.5K时,选择WRmode short和WSmode 0,Emode selector会选择EVmode 2作为合适的erase-voltage。
后台GC过程,难以预估顺序的写请求,因为后台GC运行在写请求没有被调用时候,因此Emode selector延迟决定正确的erase-voltage模式,选择默认的EVmode 5(浅擦,最低erase-voltage),如果这个block没有被写满,下一个写请求就不用再选择,直接写入。如果选择的写模式不能兼容EVmode 5,选择的块会额外的使用lazy erase(懒擦除)操作(latency小于1000us),虽然block的第一个page写延时增加77%,但是由于lazy erase推进第一个page的写,整体写性能的负面影响只要0.6%,而DeVTS可以充分利用寿命的增加。
-
Erase-Speed模式选择
Emode selector选择正确的erase-speed模式能提供额外的寿命并不影响整体的写性能。由于在erase期间,写请求的数据在缓存中不能被写入Nand中,当持续写请求,buffer的利用率增加。根据buffer利用情况来判断使用ESmode fast还是ESmode slow。判断标准是当前buffer的使用率和erase期间增加的buffer使用率总和U*。
如果U*大于1选择ESmode fast,否则额外检查ESmode slow的结果在当前的write-speed模式下。如果U*增加到当前缓存利用率分界之上(0.33或0.66,参见第一节介绍配图),写请求将会使用快速写模式,这时候由于endurance收益在慢擦模式下小于快写模式。参见下图(图中数值代表有效磨损,值越大,磨损越厉害):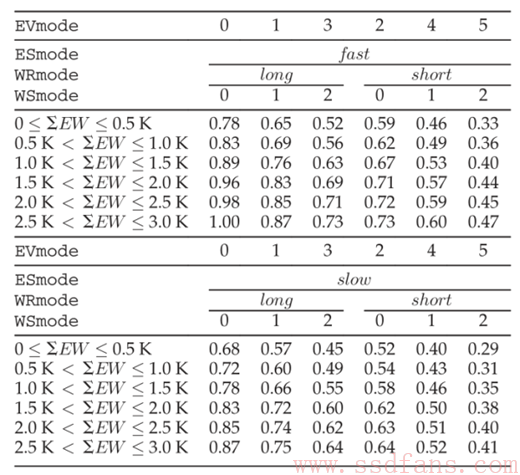
-
可以看出ESmode slow是一个适合的选择,既不影响整体写性能而且提高了寿命。
-
DeVTS-Aware Garbage Collection
GC程序被调用,为数据copy选择一个合适的write-speed模式也最大化DeVTS效率的挑战。如果有效数据copy一直选择快速写模式,性能会很好。然而由于深度擦除(兼容快速写模式)被频繁使用,增加擦除电压不可避免。相反,如果数据copy过程中一直使用慢写模式,写性能会明显降低。由于在数据copy过程中,写请求会将数据写入buffer中而不会写入flash。因此buffer利用率根据有效数据copy的大小而增加。因此,buffer的有效利用率在有效数据copy之后的改变反应了模式选择,大于1选择快写模式(WSmode 0),否则选择不影响当前write-speed模式的最快可用写模式。

