作者 琥珀

近期,谷歌的AI研究机构DeepMind研发的最新版本的AlphaGo Zero横空出世,将打败世界冠军的AlphaGo赶下神坛。AlphaGo Zero凭借的正是前所未有的”自学”棋局的能力,这种能力也将协助DeepMind研发出针对科学领域极为困难的一些问题的解决算法。
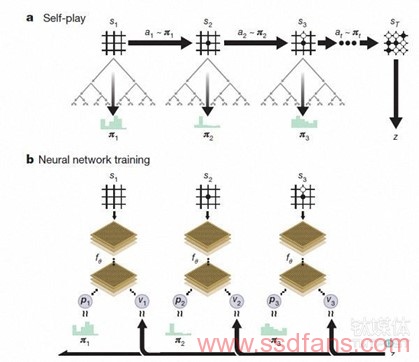
Zero继承了AlphaGo的三大基础架构:搜索算法,蒙特卡洛模拟和深度神经网络。搜索算法用于控制每一步的落子。算法先列出每一步所有不同的落子可能,再分析每一个落子若干步之后的结局,然后返回来决定哪一步更可能战胜自己的对手,这一算法还曾用于IBM的”深蓝”中。蒙特卡洛模拟则是通过生成可能出现的局面来帮助AlphaGo理解每一步的重要性和每一步所产生的后果,来帮助系统进行决策。而作为深度学习基础的深度神经网络在设计的第一时间就被用在了AlphaGo中,AlphaGo中共包含两个不同用途的神经网络,一个用于围棋的决策,一个则用来验证不同的决策产生的后果。
除了基础的算法结构,AlphaGo和Zero使用了完全不同的学习策略。早期版本的AlphaGo之所以能够”独孤求败”,他的武功秘籍就在于他无可比拟的数据量上,在训练过程中,需要从数十万盘围棋游戏的对局信息中学习到新的知识,极大的依赖于人类的经验知识。而”青出于蓝而胜于蓝”的AlphaGo Zero则不然,他不再需要那些庞大的数据,他要的只是围棋的游戏规则,然后在游戏规则的基础上自己与自己进行博弈对局,也就是我们所说的”左右互搏”,每当一局”互搏”游戏结束后,他会从胜利的一方学习经验,从告负的一方吸取教训,不断重复这个过程,这样一来,他就可以从自己的身上学习到新的游戏技巧。只需要经过100天的自我对弈,Zero已经可以以10比0的大比分打败那个曾经战胜了李在石的AlphaGo,而如果能够自我对弈40天以上,Zero就能以百分之九十的胜率打败最新版本的AlphaGo。AlphaGo的打遍天下无敌手只是昙花一现,Zero的前所未有的强大直接将AlphaGo送下神坛,退出历史舞台。

Zero的成功也对人类棋手具有一定的启发意义。Zero的项目主管David Silver介绍道,没有了人类经验的指导,在Zero最开始的对局中,他完全就像是一个初学者,会犯一些十分愚蠢的错误。而随着对局数量的增加,他就像是一个围棋天才一般,开始逐渐具有职业棋手的专业水平,开始规避对手的陷阱,他的棋路也逐渐成熟。与此同时,在Zero不断探索新的棋路的过程中,我们也在其中发现了一些人类曾经苦思冥想得到的精妙的技巧,这也从侧面证明了人类对于围棋的研究走的路是正确的,而我们更想知道,我们对于围棋的研究,是否走到了路的尽头,前面是不是还有更加广阔的前景。自我学习的其中一个目的就是为了摒弃人类的经验的桎梏,让Zero从无到有的进行学习,我们也期望Zero学习到的一些新的策略可以启发人类棋手,增进他们的实力。在AlphaGo Zero横空出世的当天,曾经和AlphaGo有过交战的柯洁在第一时间回应,”对于AlphaGo的自我进步来讲…人类太多余了”。
除了能够启发人类棋手,Zero还有其他方面的优势。原有的AlphaGo在训练的过程中需要用到48块TPU(TPU是谷歌研发的一种专用的人工智能处理器),Zero则大大减少了所需要的计算资源。并且,正是因为我们我们解除了对数据的依赖,使得我们可以设计出更加先进的人工智能算法。
长期以来,学术界中一直有一种观点认为,现有的人工智能算法之所以能够获得优秀的结果是得益于现在相对廉价的计算资源和庞大的数据采集,算法本身在其中起到的作用微乎其微,而此次AlphaGo Zero的成功则是一次有力的回击,证明了在现有的我们取得的进步中,算法也有至关重要的地位。

增强学习,作为AlphaGo系列的主要算法,最近五六年逐步从纯粹的学术研究到应用与社会各界,主要得益于DeepMind的大力推动,而此次Zero能够脱离数据和计算资源的桎梏,取得如此巨大的成功,对于推动增强学习以及人工智能的发展具有重要的意义。DeepMind的联合创始人Demis Hassabis介绍道,Zero做的工作实质上是在纷繁复杂的数据中搜索我们想要的信息,只不过在围棋领域中需要额外学习围棋规则罢了,所以这种系统还可以应用到其他的领域中,新药研发,蛋白质折叠,量子化学,粒子物理以及材料设计等。Hassabis还说道,Zero的一种变形其实可以用来帮助物理学家搜索”室温下超导体”的组成。当电流通过一个超导体物质中,能量不会有任何损失,而现有的超导体都只存在于极低温度下,而室温下超导体只是一种理论上存在的物质。在这个例子中,科学家们就可以使用AlphaGo的这种类似的系统来搜索得到人类还未能发现的物质组成结构。当然,将Zero应用于其他领域会遇到很多难以解决的问题,但这至少是一条可能通往正确答案的道路。
人工智能在围棋领域所获得的巨大成功并不能代表整个领域的现状。围棋规则中的黑白执子,网格状的棋盘都十分有利于计算机来理解围棋的规则和模拟围棋的进行,只要有足够多的时间和计算资源,理论上讲可以穷尽所有的可能性。可以说,AI在围棋上的优秀表现很有可能也只是局限于这个狭窄的领域中。所以说,我们应该理性看待人工智能的现有的发展,公众和媒体要认识到人工智能的发展是一个长期,持久性的战斗,不是一朝一夕就可以”毕其功于一役”,还要鼓励更多的优秀人才投入到这个蓬勃发展浪潮中,毕竟,这是人工智能”最好的时代”。

