随着计算机行业的飞速发展,CPU的速度和内存的大小都发生了翻天覆地的变化,在处理器速度不断增加的形势下,处理器处理数据的能力也得到大大提升。数据是存储在内存中的,内存吞吐率虽然得到很大的提升,但是相对于处理器来讲,仍然非常慢。处理器要从内存中直接读取数据都要花大概几百个时钟周期,在这几百个时钟周期内,处理器除了等待什么也不能做。在这种环境下,才提出了Cache的概念。计算机中常见的存储介质如图1所示,在梯形图中从上到下容量依次递增,速率依次递减,每字节的成本依次递减(图中列出的外部存储不是绝对满足这两条性质,由于受到生产工艺和时间的影响;寄存器访问速度是最快的,编程有一个register关键字,对于重复次数很多的变量可以用register声明,这个变量就被放到寄存器空间,寄存器空间很小,register不宜多用)。
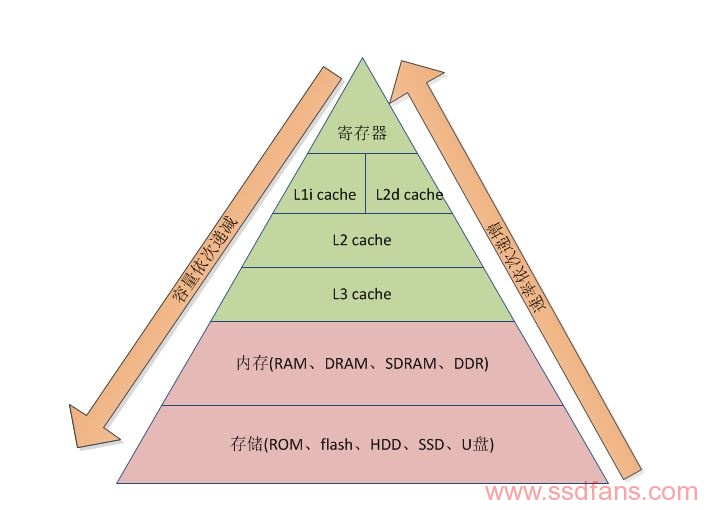
图1
CPU与内存交互数据有两种方式。图2中(a)方式比较古老;(b)图中引入了cache高速缓存,当CPU需要从内存中获取数据时,cache可以提前把CPU所需要指令和数据从内存中预取到cache缓存中,CPU直接从cache中取指令和数据。没有引入cache读取依次内存大约为150个时钟周期,引入cache后,L3 cache命中读取一次内存需要40个时钟周期。
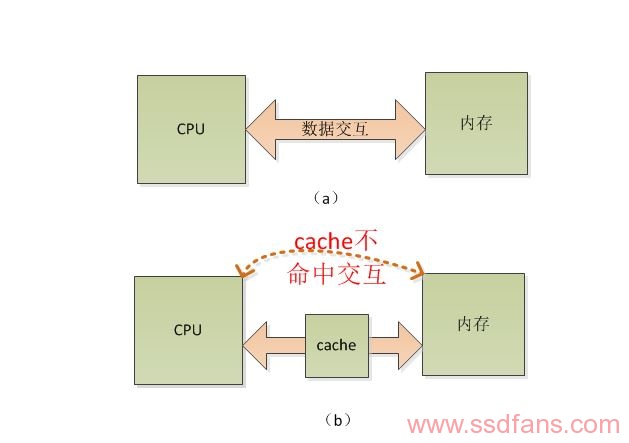
图2
Cache大多是SRAM(静态RAM),而内存大多是DRAM(动态随即存储)或者DDR(双倍动态随机存储),Cache由三级组成,一级(L1)最快,但是容量最小;三级(LLC,Last Level Cache)最慢,但是容量最大。在多核CPU中每个核拥有独立的L1和L2两级cache,L1 Cache一般把指令和数据分布存放,数据Cache用来存储数据,而指令Cache用于存放指令,为了保证所有的核看到正确的内存数据,一个核在写入L1 cache后,CPU会执行Cache一致性算法(Cache一致性算法在本文不涉及)把对应的cacheline(cache line是cache与内存数据交换的最小单位,如图3所示)同步到其他核,这个过程并不很快,是微秒级的,相比之下写入L1 cache只需要若干纳秒。当很多线程在频繁修改某个字段时,这个字段所在的cache line被不停地同步到不同的核上,就像在核间弹来弹去,这个现象就叫做cache bouncing。三级 Cache 由所有的核所共有,由于共享的存在,有的处理器可能会极大地占用三级Cache,导致其他处理器只能占用极小的容量,从而导致Cache不命中,性能下降。英特尔公司推出了Intel® CAT技术,通过软件配置算法来控制每个核可以用到的Cache大小。
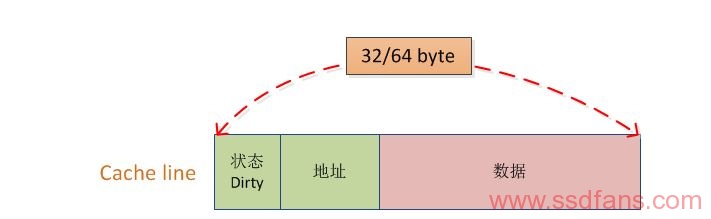
图3
内存的数据被加载到Cache后,在某个时刻其要被写回内存,写内存有如下5种策略:写通(write-through)、写回(write-back)、写一次(write-once)、WC(write-combining)和UC(uncacheable)。
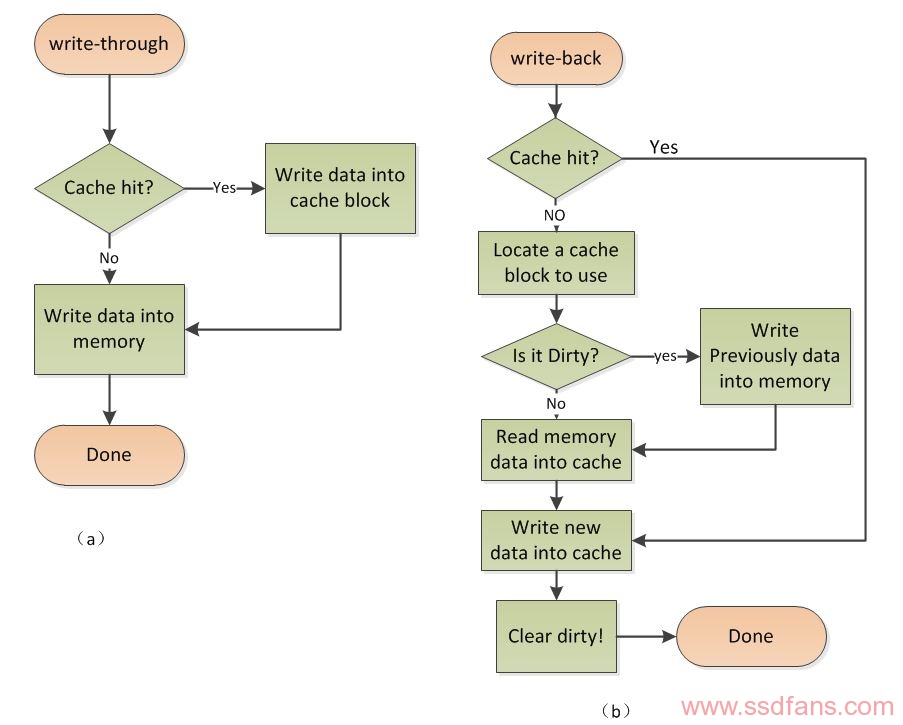
图4
写通(write-through):当cache写命中时,处理器对Cache写入的同时,将数据写入到内存中,内存的数据和Cache中的数据都是同步的,这种方式比较简单、可靠。但是处理每次对cache更新都需要对内存写操作,因此总线工作繁忙,内存的带宽被大大占用,因此运行速度会受到影响。假设一段程序在频繁地修改一个局部变量,局部变量生存周期很短,而且其他进程/线程也用不到它,CPU依然会频繁地在Cache和内存之间交换数据,造成不必要的带宽损失。当cache写未命中时,只有直接向主存写入了,但此时是否将修改过的主存块取到cache,写直达法却有两种选择。一是取来并且为它分配一个位置,称为WTWA(Write–Through–with–Write–Allocate)。另一种是不取称为WTNWA法(WriteThrough–with.NO-Write–Allocate)。前 一种法保持了cache/主存的一致性,但操作复杂,而后一种方法操作简化,但命中率降低,内存的修改块只有在读未命中对cache 进行替换时,才有可能射到cache 。写通发保证了写cache与写主存同步进行,图4中(a)图为写通法WTNWA法的流程图。
写回(write-back):当CPU对cache写命中时,只修改cache的内容不立即写入主存,只当此行被换出时才写回主存。这种策略使cache在CPU-主存之间,不仅在读方而且在写方向上都起到高速缓存作用。对一cache行的多次写命中都在cache中快速完成修改,只是需被替换时才写回速度较慢的主存,减少了访问主的次数从而提高了效率。为支持这种策略,每个cache行必须配置一个修改位(就是图三中状态字节),以反映此行是否被CPU修改过。当某行被换出时,根据此行修改位为是为0。对于cache写未命中,写回法的处理是为包含欲写字的主存块在cache分配一行,将此块整个拷贝到Cache后对其进行修改, 因为尔后对此块的多读/写访问的可能性很大。拷贝主存块时虽已读访问到主存,但此时并不对主存块修改。因为换出的cache很可能此期间要写回主存,为避免此过程耗时长,写未命中对将新块读入后,只在cache中进行写修改。统一地将主存写修改操作留待换出时进行,图4中(b)图为写回策略的流程图。
写一次(write–once):写一次是一种基于写回又结合了写通的写策略,即写命中和写未命中的处理与写回法基本相同,只是第一次写命中时要同时写入主存。这策略主要用于某些处理器的片内cache,例如Pentium处理器的片内数据cache就采用的是写一次法。因为片内cache写命中时,写操作就在CPU内部高完成,若没有 内存地址及其它指示信号送出,就不便于系统中的其它cache监听(snoop)。采用写一次法,在第一次片内cache写命中时,CPU要在线上启动一个存储写周期。其它cache监听到此主存块地址及写信号后,即可把它们各自保存可能有的该块拷贝及时作废(无效处理)。尔后若有 对片cache此行的再次或多次写命中,则按回写法处理,无需再送出信号了。
WC(write-combining):write-combining策略是针对于具体设备内存(如显卡的RAM)的一种优化处理策略。对于这些设备来说,数据从Cache到内存转移的开销比直接访问相应的内存的开销还要高得多,所以应该尽量避免过多的数据转移。这种策略是一个Cache line里的数据一个字一个字地都被改写完了之后,才将该 Cache line 写回到内存中。
UC(uncacheable):uncacheable 内存是一部分特殊的内存,比如PCI设备的I/O空间通过MMIO方式被映射成内存来访问。这种内存是不能缓存在Cache中的,因为设备驱动在修改这种内存时,总是期望这种改变能够尽快通过总线写回到设备内部,从而驱动设备做出相应的动作。如果放Cache中,硬件就无法收到指令。

