随着人工智能的飞速发展,和业界对人工智能项目落地的巨大需求,移动端GPU的竞争也日益激烈,除了来自各GPU厂商之间的竞争之外,也要与专用芯片展开竞争(例如寒武纪的NPU等),可谓群雄逐鹿。
在之前的一篇浅析移动端GPU的文章中介绍过移动端GPU领域主要的三家厂商。随着苹果弃用PowerVR,在手机领域Mali和Adreno有着绝对的优势,而在物联网和自动驾驶领域,三家都并未建立起完整的生态。这两个领域除了GPU,也有一些专用芯片厂商入局,随着物联网和自动驾驶的发展,竞争将更加激烈。相对于其他移动厂商,PowerVR在GPU的技术方面披露的比较多,其中比较经典当书Rogue架构。Rogue架构采用的是延后式分块渲染架构(TBDR),凭借该技术,Rogue架构曾一直是移动端GPU的标杆。作为苹果移动端GPU的独家供应商,也曾风光无限。本文就对Rogue架构进行一些分析,欢迎高手点评斧正。
架构概述
Rogue架构是一种可编程的架构,能够支持通用计算和图形渲染。Rogue架构针对顶点和像素的传输、计算数据在内存之间的传输以及数据和计算核心之间的交互等提供了不同的硬件。本文将侧重于通用计算方面的特性。
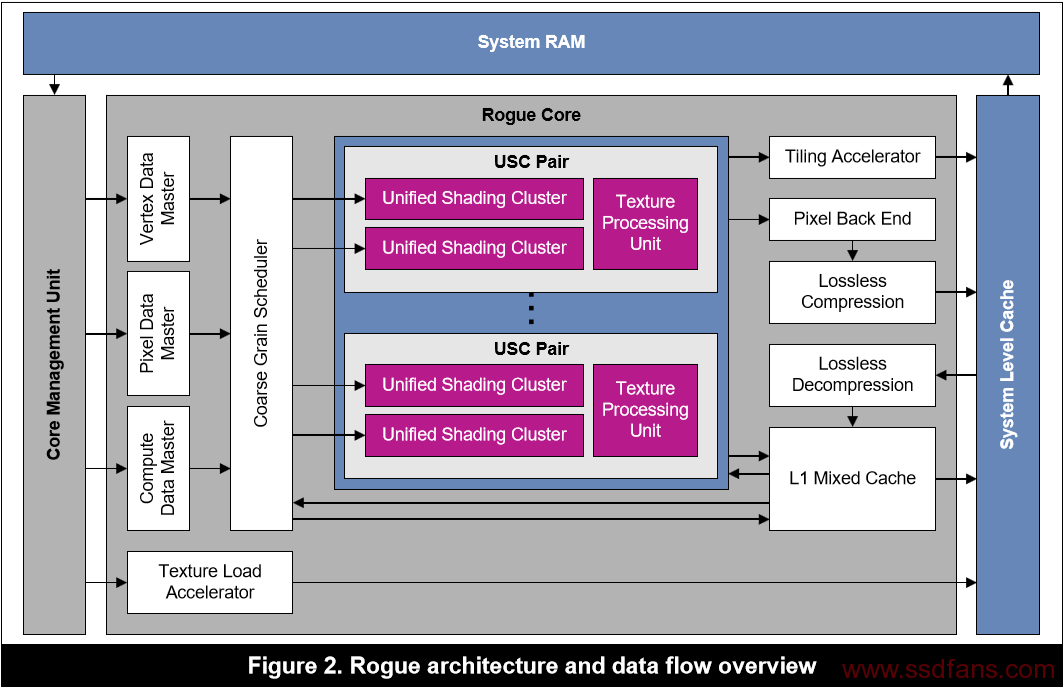
如上图所示,Rogue架构中通用计算相关的部件有计算数据控制器(Compute Data Master,CDM),粗粒度调度器(Coarse Grain Scheduler,CGS),统一渲染集群(Unified Shading Clusters),L1混合缓存(L1 Mixed Cache)。
GPU的整个计算流程是,CDM负责将CPU分配的单个任务拆分为多个子任务,然后传递给CGS,由CGS将多个独立的子任务部署到USC上去执行。只有计算任务是由CDM处理的,所以CDM是计算任务专用的通道。
每个USC pair包含两个USCs和一个纹理处理单元(Texture Processing Unit,TPU),这样可以有效的平衡纹理访问和计算。USC是Rogue架构中的主要计算单元。TPU是一种专门加速内核代码中访问图像和纹理的硬件,它拥有独立的缓存,能够加速处理器对图像数据的访问。对于一些需要对图像进行专门访问的算法和一些大尺寸的图像,TPU可以提供很好的加速效果。
L1混合缓存是Rogue架构的主要缓存,所有对内存的访问都会首先在这里缓存。当数据读取不能使用该缓存的时候,则会使用系统级缓存。系统级的高速缓存直接与系统RAM交互,也是数据命中缓存的最后机会。
统一渲染集群(USC)
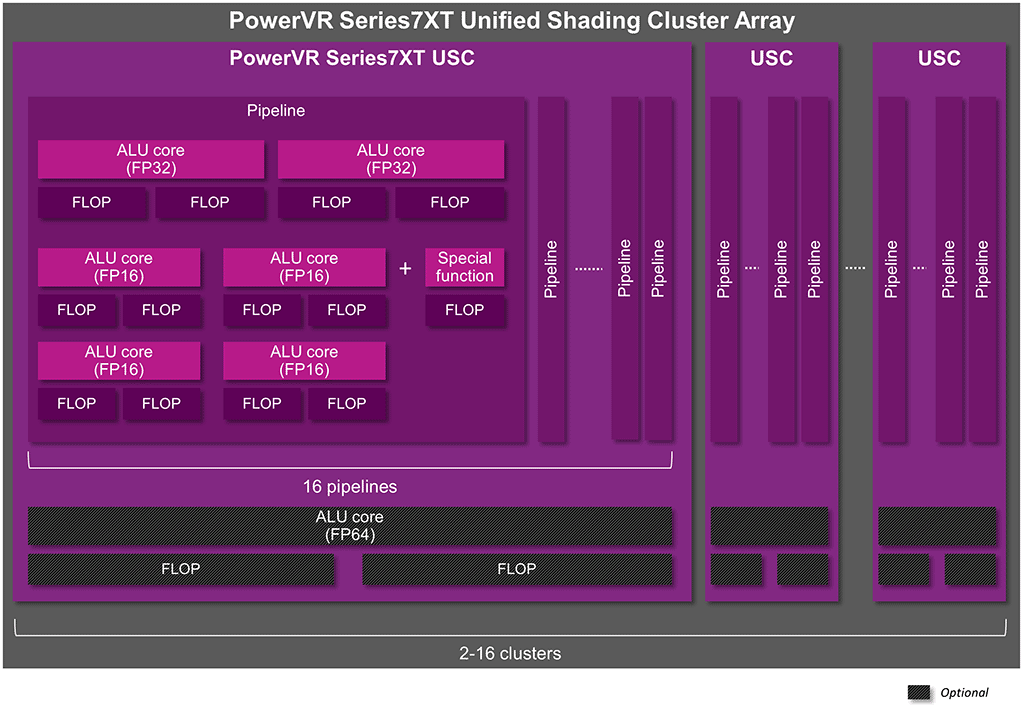
Rogue架构中负责计算的核心部件是USC,是一个可编程的标量SIMD处理器,通常包含16个ALU Pilelines,用来执行计算内核中代码。下图为Rogue架构中的USC示意图。
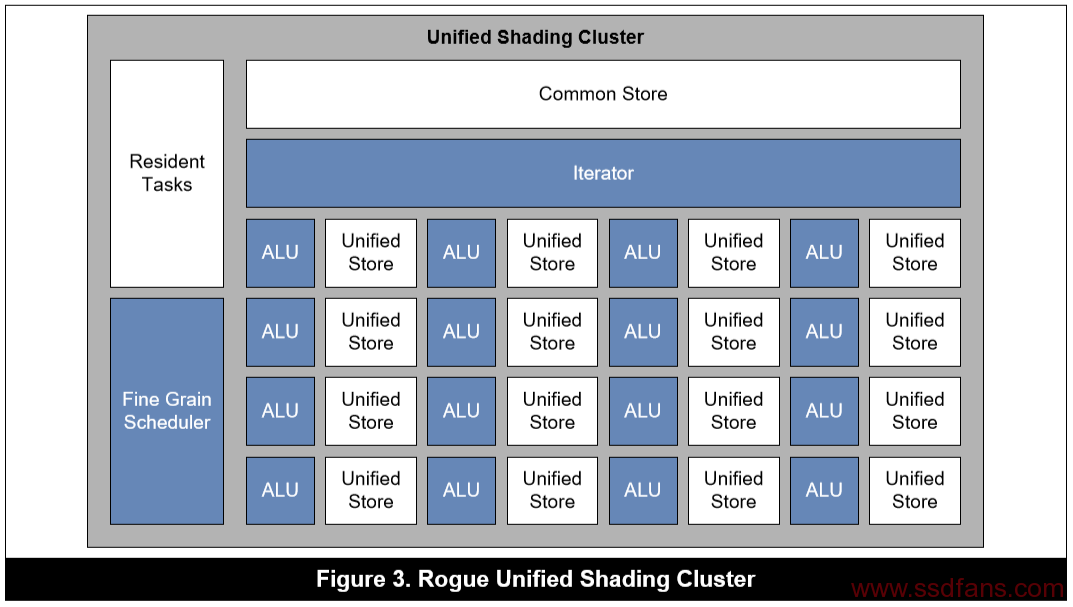
图中包含多种部件,我们只关心两种,一种是内存,一种是ALU。USC内部的内存空间主要包括两个寄存器组,一个是Common Store,由整个USC共享;一个是Unified Store,每4个ALU 管线(Pipelines)共享一块。
Unified Store是USC中4个小的由寄存器组成的存储体,每个存储体被4个ALU Pipes所共享,对应于OpenCL中的私有存储。每个Unified store包含1280个128-bit的寄存器,也就是说,每个ALU管线平均拥有320个寄存器。例如,如果每个线程申请10个寄存器,那么,每个USC上只能执行512个线程(每个ALU管线执行32个线程,需要320个寄存器),这也是达到推荐占有率所需最小的线程数。由于每个线程拥有独立的寄存器等资源,所以可以实现0开销的warp切换,切换的时候不需要进行中间数据转存。当然在具体计算中,每个线程即OpenCL的WorkItem所能拥有的寄存器,与多种因素有关。
这128位的寄存器可以像4个32位寄存器一样,被内核有效的访问,所以内核最多可以使用40个32位寄存器,达到推荐的利用率。如果一个给定的内核需要的寄存器不止这些,此时驻留的任务就会减少,减少执行每个任务的线程数量,这样每个线程就会获得更多的寄存器空间。Imagination的编译器只会降低利用率,因为占有率对于隐藏线程中的延迟是至关重要的。
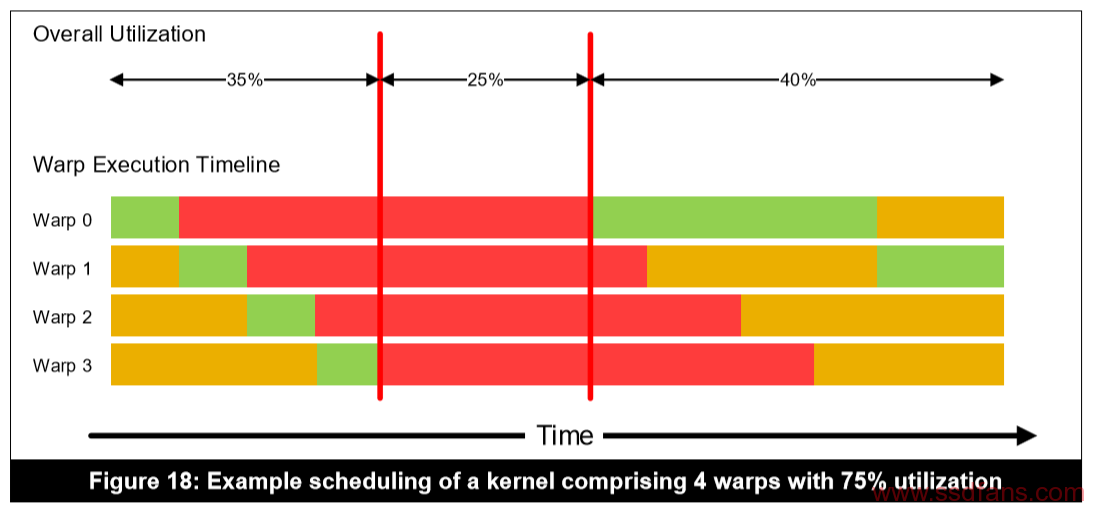
USC利用率(USC/Multiprocessor utilization),是指USC执行活动的warp所用的时间与被阻断的时间之比。如下图所示,其利用率为75%。
USC的占有率是指驻留的warps与可用的驻留槽的比率。如下图所示,展示了驻留的warps和可用warps的示意图。驻留槽的数量与具体产品有关,大多是16个。图中的占有率为6/16.
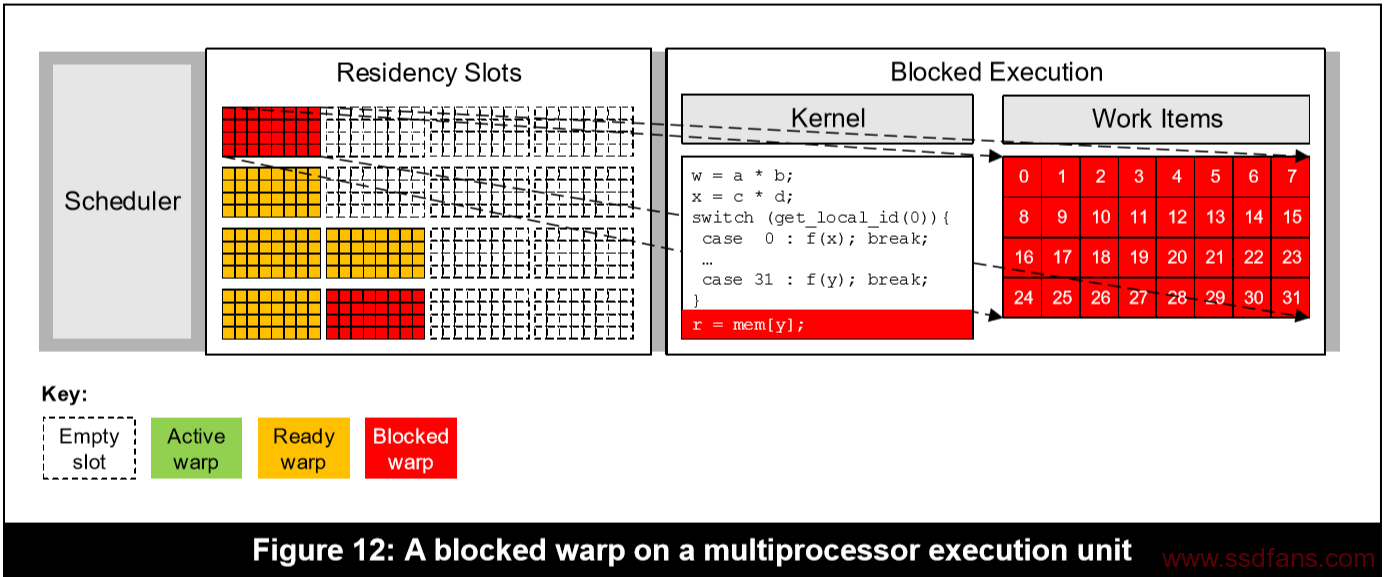
所以,当寄存器不够用的时候,编译器会牺牲利用率,保证占有率,有利于隐藏延迟。如果寄存器溢出严重,利用率不会无限制降低,会达到一个限度后,将溢出的寄存器分配到主存储器中,也就是全局存储(global memory),这样会造成很高的带宽和延迟成本,大幅度降低程序的性能。当然,这种调度是有软件控制的,所以不同的设备之间会有区别。
Common Store就是通常意义上的共享内存,它是对一个USC中的所有ALU Pipelines可见的,主要用于线程之间的数据交换,任何共享的内存都存储在这个位置,例如OpenCL的local memory,OpenGL的share memory。它也用于存储对象句柄,例如图像,纹理和采样器状态等。
Common Store被分配在4个存储体中,每个存储体可看作是一个128位宽的数列,如下图所示。
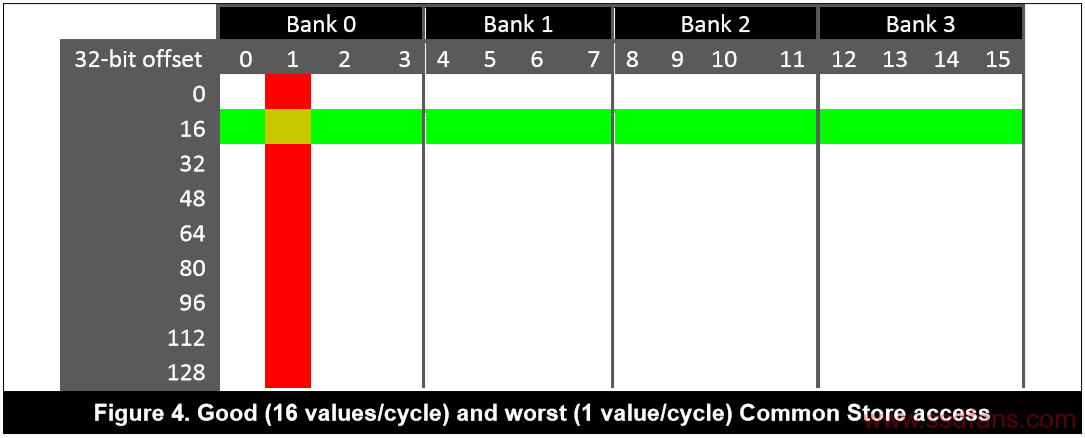
在Common Store中,可以同时从4个存储体中获取数据,整个数据行可以在单周期内读取,例如一个任务中的16个线程从同一行获取连续数据(绿色部分),那么每个线程可以在一个周期内获取32位值。但是,如果多于一个线程试图从同一列访问数据(红色部分),则会导致存储体冲突,因为每个周期,存储体只能提供一次访问请求,因此请求将被序列化,大大降低访问性能。为了避免存储体冲突,Common Store中的数据应该跨行访问,每周期访问不同存储体中的4个128位寄存器。
ALU Pipelines是USC中的计算单元,结构图如下图所示。这是Series7XT ALUs示意图。Rogue架构中每个USC包含16个ALU Pipelines,每个ALU中包含有FP16,FP32等核心用于计算。不同型号的GPU包含的ALU core类型不同,数量也不同。例如在Series7XT Plus GPU中增加了Integer Pipelines,能够支持Int8和Int16等整数类型,可以大幅度提升GPU性能,在Series7XT GPU中增加了FP64。FP16核心也不是Rogue架构的标配,早期型号也是没有的。
根据ALU core的数量和时钟频率,可以很方便的计算出GPU的理论峰值。可采用如下公式:
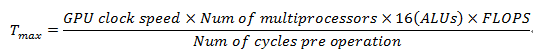
例如Series7XT系列中的GT7600包含6个USC,一共有192个FP32 core or 384个FP16 core。时钟频率有三种可定制,分别为650MHz, 800MHz和1GHz。以650MHz为例,其峰值性能为: