Dual-pool算法是比较经典的磨损平衡算法,目的是为了延长闪存的使用寿命。它实现了两方面解决:第一是存储冷数据来防止块被磨损,因为频繁更新的热数据会是磨损增加;第二是直到磨损平衡生效时,先不要去管这些被处理的块。
基本原则:
闪存块的磨损不均匀是由于workload的空间局部性导致的。把page分为三类:free page,表示可以写入数据的页,live page 表示有效页,dead page 表示无效页。因为冷数据能够较稳定的保存在块中的有效页上,而热数据更新的快,不断地更新会使原位的有效页变为无效页,就是会留下很多的 dead pages在块中,在做垃圾回收的时候倾向于回收这些dead page多的块,所以总是从那些存储热数据较多的块中回收free page。写入热数据比写入冷数据发生的频率高,所以把这些热数据存在特定的块里面。但是这样的现象会逐渐使得磨损的块出现失衡。
Young block & Old block:前者是擦除次数少的年轻的块,后者是擦出次数多的年老的块,双池算法核心实现下面的操作:
Cold-data migration:把冷数据从young blocks 迁移到old blocks
Hot-cold regulation: 发生冷数据迁移后,涉及到的块,要防止老的块被擦除,还要开始擦除年轻的块。
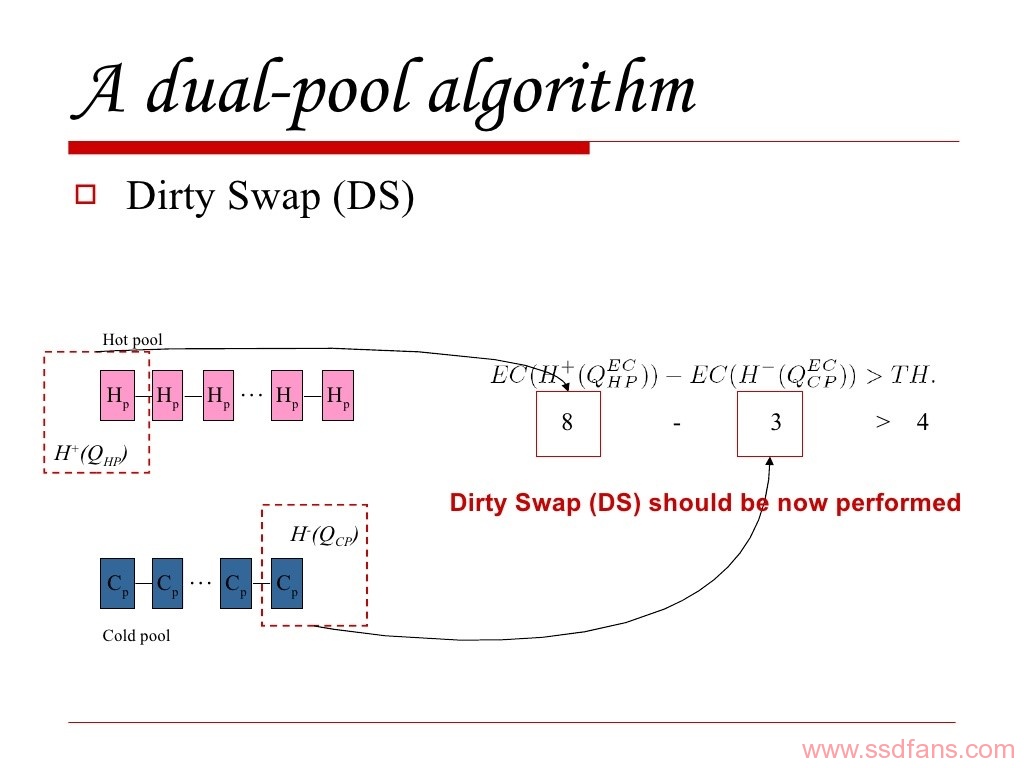
从逻辑上把闪存块分为两组:热池(hot pool)专门来存储热数据的块和冷池(cold pool)专门来存储冷数据的块。在热池中设置队列![]() 在冷池中设置队列
在冷池中设置队列![]() 队列根据每个块的擦除周期优先排序。关于优先的队列Q,函数H+(Q)返回的是最大队列头块,相反,函数H-(Q)返回的是最小队列头块。关于块B,函数EC(B),返回的是该块的擦除周期。开始的时候,一个块可以任意加入两个池,用阈值TH来进行后续判定,TH值越小,磨损平衡效果越好。
队列根据每个块的擦除周期优先排序。关于优先的队列Q,函数H+(Q)返回的是最大队列头块,相反,函数H-(Q)返回的是最小队列头块。关于块B,函数EC(B),返回的是该块的擦除周期。开始的时候,一个块可以任意加入两个池,用阈值TH来进行后续判定,TH值越小,磨损平衡效果越好。
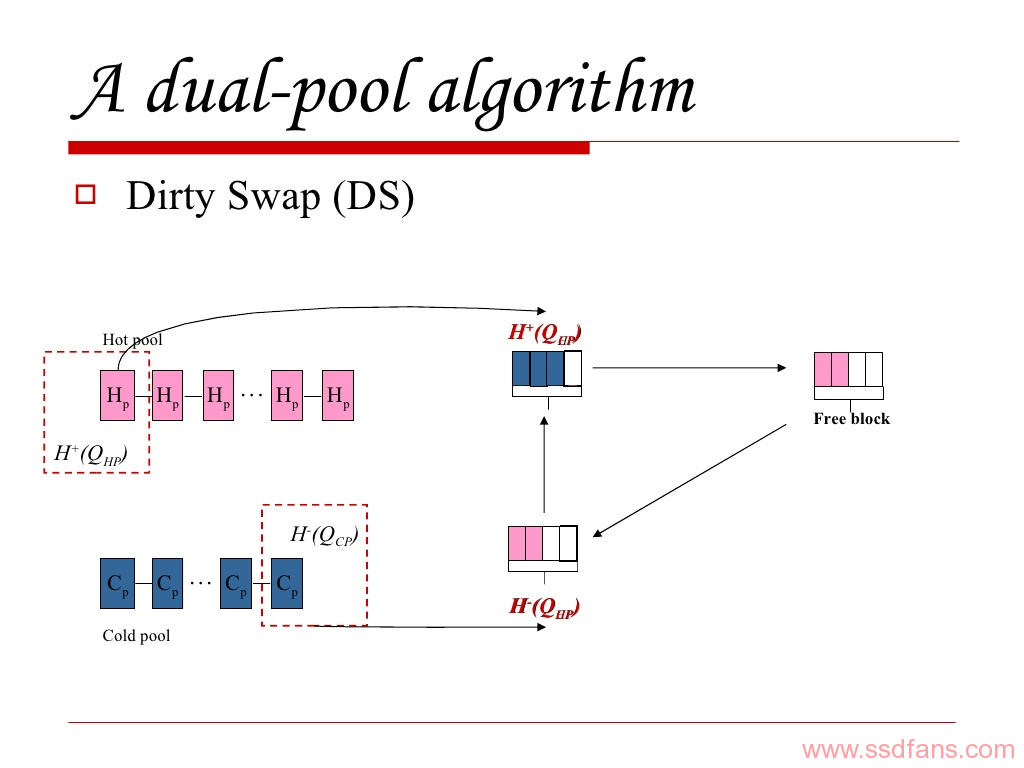
Dirty Swap(DS)操作实现了上述的Cold-data migration和Hot-cold regulation,每次完成一个写入操作的时候,要做一步检查,是否该热池的热数据块和冷池中的冷数据块的擦除周期差异大于阈值,过程如下:
![]()
如果满足以上条件,执行如下步骤:


Adaptive Pool Resizing:这部分是处理空间局部性的动态变化,对上面的基础概念进行扩充。如果访问模式一直不变化,上面的执行结果会带来很好的效果。但是在实际的workload中,很难实现。冷热数据的访问不是一成不变的,仅仅使用DS是不行的。考虑到一个块刚刚从冷池中迁移到热池中,并不再存储冷数据,假设块中的热数据恰巧变冷,随着这个块不再被擦除磨损,这个块就在热池中变得“沉默”,因为存储冷数据使它的擦除周期变得相对较小,这个块又开始不再被磨损擦除。所以,为了改进,定义了一种新的操作在热池中:


考虑到有DS迁移至冷池中的块,这个块具有大的擦除周期,而有效擦除周期为0,DS把冷数据放置在块里停止它被磨损擦除。一方面,如果冷数据一直保持,那么这个块的有效擦除周期值就会维持在低值。另一方面,如果这个块不再存储冷数据,那么有效擦除周期就会增长的很快。通过引入的有效擦除周期的检验,这两种情况能被明显区分。
所以在完成一次写入操作时,先进行DS操作,然后执行CPR,最后执行HPR。

对于超大规模闪存存储系统而言, 这一提出的算法为磨损均衡问题提供了非常有力的解决。

