在中国一家初创公司SenseTime的协助下,中国中山大学的研究人员在自己研究的基础上进行了改进,他们试图通过增加一些自我监督训练,改进了计算机识别图像中的人体姿势的方法。这项研究将继续努力减少人工智能对人类和“基本事实”的依赖。
人工智能开始更多地尝试让机器在人类干预最少的情况下自学。所谓的自我监督是一种可以添加到许多机器学习任务中的元素,这样计算机就可以在更少的人工干预下学习,也许有一天甚至完全不需要人工干预。
中国中山大学和香港理工大学的科学家们在一项新的研究中利用自我监督功能,帮助计算机学习视频片段中人体的姿势。
AI丰富的机器学习研究脉络可以帮助它理解一个人在图片中做什么,这对包括视频监控在内的许多事情都有很大用处。但这种方法依赖于“带注释的”数据集,各种标签被应用于身体关节的各个方向。
观看YouTube视频可能会让机器人有一天可以模仿人类
不过这是一个问题,因为越来越大的“深层”神经网络迫切需要大量数据,但并不是一直都有足够的标记数据来满足它。
因此,中山大学的研究人员开始着手证明,神经网络可以通过不断地比较多个网络之间的猜测来完善其对信息的理解,最终减少对标记数据集所提供的“基本事实”的需求。
正如作者所言,之前推断人体姿态的努力已经取得了成功,但代价是“耗时的网络架构(例如ResNet-50)和有限的可伸缩性,因为三维姿态数据不足”。
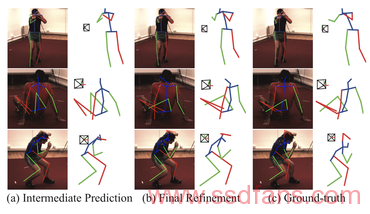
机器学习效果模拟图
在一系列基准测试中,作者证明了这种方法在成功预测一个图形的姿态方面优于其他AI方法。他们甚至在2017年通过增加这种新的自我监督方式超越了自己曾经的业绩。
麻省理工学院开始更加关注用一个AI训练另一个AI
一篇名为《具有自监督学习功能的三维人体姿态机》的论文在arXiv上发表,作者:王克泽、梁林、蒋辰涵、钱晨、魏鹏旭。其中钱晨是SenseTime的员工。SenseTime是一家中国的人工智能初创企业,销售人脸识别等各种应用软件,并发布了一种名为“鹦鹉”的机器学习编程框架。
在他们2017年发布的论文原告中,作者使用了一个带注释的数据集,即2014年由德国Max Planck信息研究院的米卡洛·安德里卢卡(Mykhaylo Andriluka)及其同事编制的“MPII人体姿势”数据集。他们使用标记的数据集从静态图像中提取人体部位的二维图像,基本上是四肢在空间中的简笔画。然后,他们将这些二维图像转换成三维状态,从而更好的表达肢体在三维空间中的方位。
在这篇新论文中,作者通过MPII数据集进行同样的“预处理”,从图像中提取二维信息。就像在2017年,他们使用另一个数据集“人类360万”来提取3D的地面数据。《人类360万》共拍摄了360万张在实验室拍摄的演员执行各种任务的照片,例如跑步、散步、吸烟和吃饭。
谷歌认为所有的软件都可以嵌入AI
这次的新发现是,在神经网络的最后一部分,他们抛弃了2D和3D注释。相反,他们将2D图像转换成的3D模型与第一步生成的2D图像进行比较。初始化后,用2D和3D预测的信息代替2D和3D的ground-truth,以自我监督的方式优化模型。
他们将3D模型投影到平面中,得到投影的2D图像,然后使这个新的2D图像和最初的2D图像之间的差异最小化。
从某种意义上说,神经网络一直在问它生成的人体三维模型是否在三维空间中准确地还原了二维图形所表达的信息。
现在有很多标准的机器学习方法:卷积神经网络(CNN)允许系统提取二维简笔画。这种方法借鉴了卡内基梅隆大学(Carnegie-Mellon)研究人员2014年和2016年的一项后续研究。
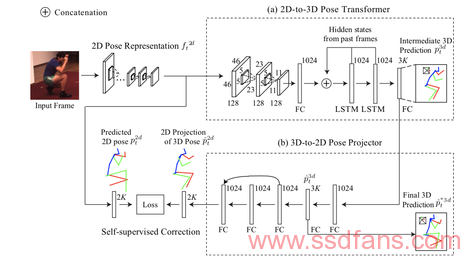
然后,使用长短时记忆(long short-term memory,简称LSTM),即专门保留事件序列记忆的神经网络,从多个连续的视频中提取人体的连续动作,创建三维模型。这项工作是根据2014年亚历克斯·格雷夫斯(Alex Graves)和他在谷歌旗下DeepMind公司的同事所做的工作进行建模的,DeepMind最初是为语音识别而建立的。
它的特别之处在于,强加自我监督,使整个模型保持一致,而不需要贴上基础数据的标签。通过采取这最后一步,能够减少对3D数据的需求,更多的依赖2D图像。他们表示:“这种强加的校正机制使我们能够利用大量二维人体图像数据来提高对三维人体模型估计的准确度。”
原文链接:https://www.zdnet.com/article/chinas-ai-scientists-teach-a-neural-net-to-train-itself/

