作者 唐杰
2017年的AWS re:Invent 无疑是让硬件人员比较激动的,因为人家提供了Bare Metal的虚拟机,简直就是一个完美的螺旋式上升的案例。
其中的两个session,CPM330和CPM332很重要,其中332讲了整个EC2 实例的发展过程。两个Session对照着,把胶片和Youtube上的视频看了之后,的确有不少收获。很遗憾,不管是胶片所在的slideshare和youtube,都是在墙外。就像有位公有云的大咖讲的。 “AWS不是终点,但的确是指路的明灯。”
先上一个总结的表吧。
|
Date |
Type |
Local Instance Storage |
EBS |
Network |
Hypervisor |
|
Jan/2013 |
CR1(No Nitro) |
HBA connected SATA |
iSCSI |
Intel 82599 |
Xen |
|
Nov/2013 |
C3 |
Intel 82599+Accelerator loopback (SRIOV) |
Xen |
||
|
Jan/2015 |
C4 |
Remove Local storage |
Annapurna /10G |
Xen |
|
|
May/2016 |
X1 |
Add local storage back |
Combine EBS+ENA (25G) |
ENA go to 25G with Annapurna (Remove SRIOV) |
Xen |
|
Feb/2017 |
I3 |
Local storage go to NVMe (with encryption) |
Xen |
||
|
AUG/2017 |
I3. metal |
Vmware |
|||
|
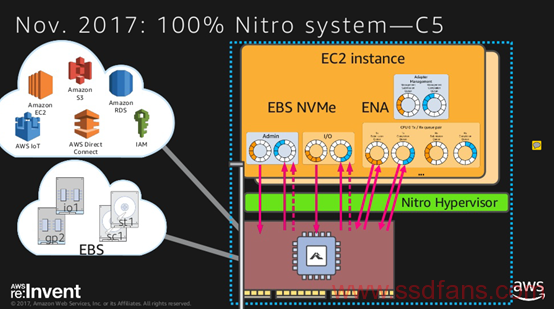
Nov/2017 |
C5 |
No Local storage |
Light KVM, No Qume |
||
对于关注AWS的底层技术的大侠,另一个表也是需要关心的。

Network
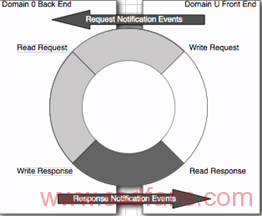
这一切都是从VPC开始,在这个之前,貌似AWS用的都是Xen的半虚拟化技术,大部分的I/O路径如下图, 对应的就是Xen HVM4.0.1 的年代。
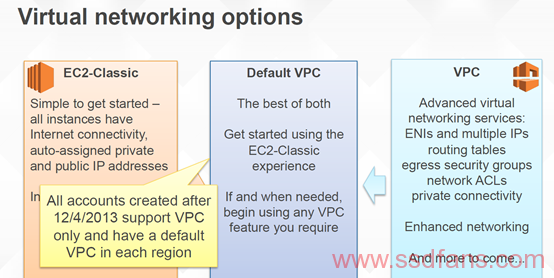
从EC2 Classic转移到VPC的意义很重大,在2014的AWS Re:Invent的讨论很有借鉴意义。
在这一次的变化中,提到了两个关键技术, 一个SRIOV,另一个则是Intel 82599的Flow Director技术。SRIOV是bypass hypervisor的技术,讲的很多了,但是Intel 82599 利用Flow Director做Tx/Rx的队列,和对用的CPU core绑在一起,大部分都是在DPDK的实现。
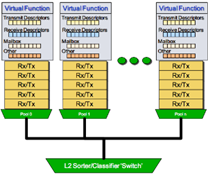
记得很早之前,有人讨论过用Flow Director来替代RSS可能会造成package的乱序,但是在DPDK的大潮下,应该已经解决了这个问题。
这个比较关键的信息,不在slide中,一定要听视频,他们在服务器的LOM的82599前面加了网络加速器,和微软在40G RDMA网卡之前加一个FPGA一样,AWS在自己的82599前面加了一个PCIE 接口的加速器,整个框图如下:
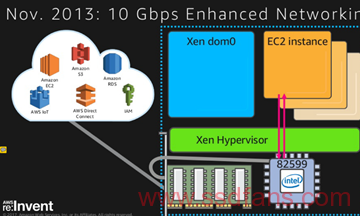
这个图,表明了82599用SRIOV,把自己的queue和VM的CPU进行绑定,VPC实现的类似于vXLAN,GRE之类的网络虚拟的处理功能应该是这个网络加速卡实现,但是这个是啥硬件,真的母鸡呀!
整个网络虚拟化的包,先进这个不知道的网络加速器, 然后完成和虚拟化相关的工作,通过网口到主板上的82599, 82599这时候就像一个简单的SRIOV的网卡,利用L2的FW功能,关注自己在VM上的通道就行,这时候的驱动就是ixgbevf.
与网络相关的另一个大变化就是25G的兴起,AWS和MS 两个是25G的主力, 在2016年的时候,ENA的出现表明了原来那种两个PCIE 板卡loopback的方案退役。
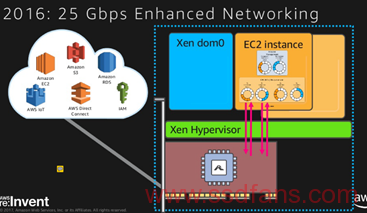
可以看到,两个卡合体,使用ENA的驱动,这个驱动已经非常流行,进入了upstream,而且支持DPDK。
使用2015年初收购的Annapurna的技术。这里面比较牛的地方应该是这公司的芯片从10G升级到25G了,不仅提升了EBS,同时顺带做了网络加速。这个合体,真心牛逼。可以看到,网络的确是主业。
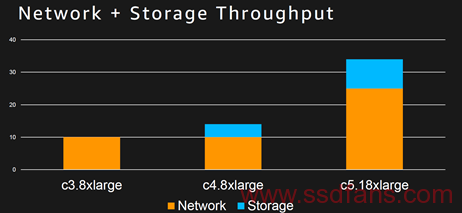
对于ENA来讲,可以拎出来的讲的有:
1. 支持10G/25G/40G,因此应该是多种部署。82599+AFU,710+AFU,和定制的网卡。
2. 网络的流量在物理上和EBS分离。
3. 规格上,ENA网卡可以UP To 400Gb/s
4. 在PCIE接口上,ENA应该是使用多个PF的技术进行功能隔离,但是在ENA卡上,如何使用PF或者VF, 目前还不知道。
5. 在C5之前的实例中,AWS总是对CPU有保留,在C5中号称可以直接使用所有的72core。因此,不太可能使用Intel DPDK了。
6. AWS 现在不用RDMA,也不用SRIOV和DPDK。好牛逼的说。
Storage
这个是笔者老本行,而且在国内是真正接触了Annapurna的人之一,就从这个开始吧。基于他们的技术的产品是C4,
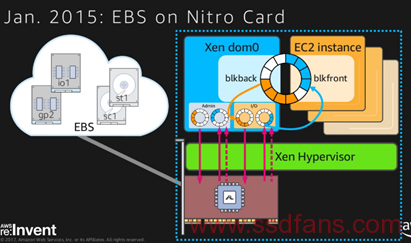
A司的网卡提供两个10G的接口跑EBS存储,还有一个管理网口。
比较先进的是,在2013年,NVMe的协议刚刚出来的时候,A司在他们的卡和AWS的hypervisor的接口就是用NVMe,然后dom0和VM之间走block device,具体应该就是类似VFIO的接口。
AWS在2015年年初花了350M收购这个公司的原因,主要是AWS的每一台服务器上要部署这样的网卡,他们的量已经足以支持一个ASIC公司的产量了,也就是说至少是1M以上的PCs。
之后的进展,就是把由A司产品仿真的NVMe设备,换成真正的NVMe设备。这里就是lcoal storage的演进。要知道,C4是没有本地存储,貌似都可以用EBS的。NVMe 的规模部署的门槛很高,Intel自己说一个NVMe 设备需要4个CPU Core,他们的SPDK可以做到一个1CPU core支持4 个设备。还有,很多SDS的客户也在讲,一个E5的服务器安装超过6个NVMe设备都会明显的瓶颈。
因此,在作为以卖CPU为主业的AWS enable NVMe的时候,走了一条和国内大厂不同的路:
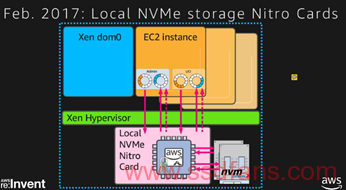
NVMe直连VM了,这里肯定用了SRIOV的技术,因为2017年初支持SRIOV的NVMe基本上没有。I3的一台物理服务器挂了8个NVMe
本地的Nitro降低了对CPU的使用,同时又提供了AES级别的加密,毕竟AES加密的盘还是要多收钱的。
在这里要多说几句,在2016年底的时候,有一个宇宙大厂找我们商量NVMe Host Adapter的事, 我当时的反馈是我们的FPGA做PCIE SW肯定干不过专业厂商。现在来看,真的是图羊图形破。
至于国内大厂的NVMe使用,可以参考这个。
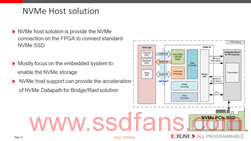
如何来实现一个NVMe的host,同时支持SRIOV以及加密功能的方案,如果大家对FPGA有兴趣,这个是一个很好的start point。

在支持本地的NVMe SSD之后,EBS的后端估计也换成了NVMe,在2017年的发布中,和Nitro相关的发布有nitro加密,nitro ENA,nitro EBS, 对于这三个东西如何工作在一起,下图可能比较明确的表现出来。
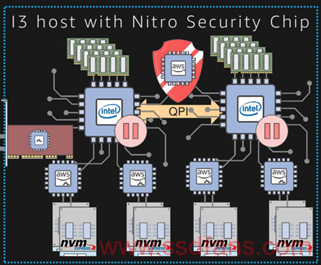
1. 主板上专用的加密芯片。
2. 本地的芯片来连接NVMe SSD,降低对于本地CPU的使用。
3. 基于网络的nitro卡,分两个端口,分别处理ENA和EBS。
这里面,可以做一个大胆的预测,在AWS 用nitro第一代加强了EBS之后,大家可以看到有VM不再需要本地存储了,因此有了存储和计算解构的方案。本地只放一个SATA SSD做hypervisor OS。
在全面enable的NVMe SSD之后,特别是I3的机型可以提供3M 的IOPS,而且因为计算和存储解耦合带来的收益不大,大家可以参考OCP那些奇奇怪怪的机型,真心没省啥。因此AWS,很有可能再次使用本地存储,本地存储一部给本地的VM使用,一部分通过nitro卡变成EBS给其他节点使用。当然,这里面的混布的挑战更大。
最后说一下,自己的感受,AWS在公布nitro的方案时候,也提出了他们有两个选择,FPGA和定制的ASIC,作为FPGA公司来讲,当然希望AWS的跟随者这来用FPGA做copycat了,反正没有专利。
FPGA如何做,个人觉得这张图可以作为出发点。在VFIO的定义中,支持的7种设备, 本质上没有差别,都是各种queue,作为在通讯业混了10年的FPGA,最擅长的地方就是用FIFO来做queue。各位亲,真诚欢迎来讨论。