mali 起源
arm的GPU虽然起步较晚,但是依赖于arm处理器强大的市场占有率,其GPU迅速占有市场。arm的GPU叫做mali,mali并不是arm原创的,而是1998年由挪威大学的学生创立,最初瞄准的是pc市场,但是在与英伟达和ATI的竞争中失败之后,转而针对移动市场进行IP授权业务;最初的GPU代号为Malaik,为了方便记忆,改名为mali,该名字来自罗马尼亚文,意思是微小(small).2006年arm收购了该团队,组建了自己的GPU业务线。
mali的架构变迁
所有Mali GPU架构都基于基于tile-based的渲染原理,这种技术旨在通过最小化帧缓冲访问所需的外部DDR存储器带宽来提高系统范围的能效。 Mali GPU基于tile的渲染方法的关键原则是:
- 所有图元都是顶点着色,并根据像素覆盖范围分配给屏幕空间tile。
- 片段着色呈现为存储在本地存储器中的中间图块缓冲区,该存储器紧密耦合到每个着色器核心,并且仅在该屏幕区域的渲染结束时写回到主存储器。着色期间的所有帧缓冲区访问(例如深度测试或alpha混合)都是对本地内存而不是外部DDR进行的高效访问。
- 使用本地存储器进行中间存储可以实现节能混合,零带宽瞬态附件以及几乎免费的4x多样本抗锯齿。
随着时间的推移,Mali GPU架构不断发展,以满足最新标准API(如OpenGL ES,OpenCL和Vulkan)的需求,并进一步提高区域效率和能效。
Mali GPU架构提供了一组可配置的图形和GPU计算IP,允许芯片实现者选择着色器核心数和二级缓存大小。 这种可配置性允许每个实现找到满足其要求的性能,功率和硅面积的适当平衡。
如图1是mali GPU的所有架构。
Utgard架构 – 由Mali-2xx,Mali-3xx和Mali-4xx系列产品实现,基于总出货量计算,Utgard架构是历史上最成功的GPU架构。 它是Arm开发的第一个可编程着色器核心架构,使用一对非常节能和面积效率的着色器核心设计支持OpenGL ES 2.0功能集:一个专用顶点处理器和一个专用片段处理器。
Midgard架构 – 由Mali-T6xx,Mali-T7xx和Mali-T8xx系列产品实现,是一个统一的着色器核心架构,首次发布时支持OpenGL ES 3.0和OpenCL 1.1,但是后来的家庭GPU 与更新的驱动程序版本配对时,还支持OpenGL ES 3.2和Vulkan API。
Bifrost架构 – 由Mali-G3x,Mali-G5x和Mali-G7x系列产品实现,是Midgard架构的后续产品。 Bifrost架构的主要设计目标是提高能效和面积效率。 应用程序可见功能集与Midgard架构非常相似; 添加了支持Vulkan 1.1和OpenCL 2.0所需的次要功能。
Valhall架构 – 首次在Mali-G7x系列上实现,是Arm的第二代Arm GPU标量架构,用于高性能,高效率的GPU。 具有创新,简化和编译器友好的指令集。 Valhall改进了前几代人的Bifrost进步。 更好地与最新的API(例如Vulkan)保持一致,允许用户在移动和笔记本电脑设备上体验AAA级游戏,并获得高质量图形,并具有更长电池寿命的所有优势。
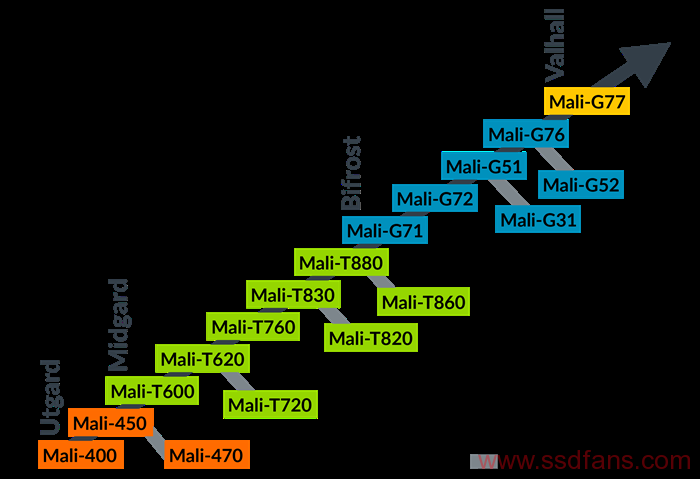
图1 mali GPU架构变迁图
bifrost架构
图2是典型的bifrost GPU的控制总线和数据总线的顶级描述。图中包含:顶点队列和片段队列,L2cache,着色器等部件。
- mali GPU着色器的数量是可配置的,例如G72最高可以扩展到32个着色器核心,芯片厂商可以根据具体的性能需求以及芯片面积等因素选择核心数量。
- 为了提高访存性能,mali GPU设计了L2 cache,L2 大小也是由厂商配置的,但是每个核心一般会有64-128KB的L2 cache;另外bifrost架构旨在每个核心每时钟写一个32位像素,因此有理由相信8核设计在每个时钟拥有256位的存储带宽用于读核写。
- 关于渲染,应用程序完成对渲染的定义之后,驱动程序可以为每个渲染过程,提交一对儿独立的工作负载;一个独立的渲染过程,处理所有几何和计算相关的工作负载;另一个独立的渲染过程处理片段相关的工作负载;由于mali GPU是Tile-based的渲染器,因此,片段着色开始之前,必须完成渲染过程中的所有几何处理。bifrost GPU支持两个并行的队列——Geometry Queue和Fragment Queue,每个队列负责一种类型的负载; 两个队列的几何和片段工作负载可以由GPU同时并行处理。 这种安排允许工作负载分布在GPU中的所有可用着色器核心上。

图2 Bifrost架构GPU的顶级描述
bifrost的shader Core架构
图3是mali GPU的bifrost的shader core的架构;shader core架构输入包含前文提到的两个队列,几何渲染和片段渲染队列。由 spawn queue把任务分配到不同的引擎上执行(execution engine);例如 G71包含3个execution engine。另外包含多个数据共享单元,引擎和数据处理单元是由消息传递结构(message fabric)链接起来的。引擎负责执行渲染指令,每一个引擎包含一条复合算术单元流水线,以及其他线程需要处理线程的状态。
为了提高功能单元的利用率,Bifrost中的算术单元实现了四向量化。线程被分组成四个包,称为quad,每个quad填充一个128位数据处理单元的宽度。从单线程的角度来看,这种体系结构看起来像一个32位标量操作流,这使得对着色器编译器来说,实现硬件的高利用率是一个相对简单的任务。
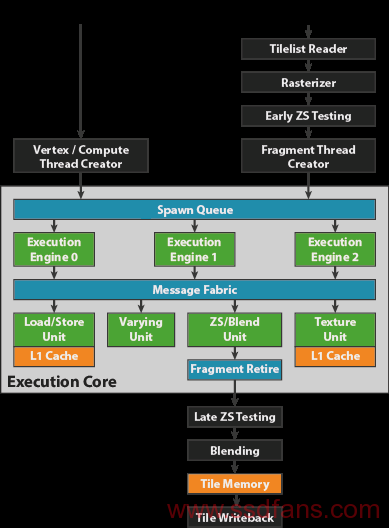
图3 shader core架构图
图4展示了一个vec3向量如何映射到SIMD单元上。对于vec3向量的处理是通过填充空数据,映射到宽度为4的SIMD单元上的,所以其硬件利用率相对于vec4会低。

图4 vec3向量映射图
图5展示了vec4的处理方式:
同样是12个数据的处理,vec4只需要3个时钟周期就可以处理结束,而vec3则需要4个时钟周期。在移动设备上,考虑到电能及效率等因素,小于32位数据类型的支持是非常有益的。bifrost架构维持了对int8,fp16,int16等数据类型的支持。对于这些数据类型,可以打包来填充128位的数据位宽,因此,数据处理单元在一个时钟周期拥有16倍的int8,8倍的fp16处理能力。为了提高复杂程序的性能,和程序的可伸缩性,bifrost架构提供了64x32bit的寄存器文件,同时仍然允许GPU的最大线程占用率。

图5 vec4向量映射图
load/store Unit
load/store单元处理所有通用(非纹理)内存访问,包括顶点属性获取、变化获取、缓冲区访问和线程堆栈访问。每个核心包含16KB的L1数据缓存,它由共享的L2缓存支持。load/store缓存可以在每个时钟周期中访问一个64字节的缓存行,并且跨线程quad的访问经过优化,以减少所需的惟一缓存访问请求的数量。例如,如果quad中的所有四个线程都访问同一高速缓存线路中的数据,则可以在一个周期内返回该数据。
请注意,这种加载/存储合并功能可以显著加快在常见OpenCL计算内核中发现的许多数据访问模式,这些模式通常是内存访问受限的,因此在算法设计中最大化其效用是一个关键的优化目标。同样值得注意的是,即使Mali算术单元是标量,数据访问模式仍然会受益于良好编写的向量加载,所以我们仍然建议尽可能编写向量化着色器和内核代码。
Varying Unit
varying unit是是一种专用的固定函数插值器。实现了与可编程运算器相似的优化策略;他对thread quad的插值进行了矢量化优化,以确保良好的功能单元利用率,并支持更快的fp16优化。该处理单元每个quad每个时钟可以处理128位的插值,vec4的fp16插值,需要一个quad两个时钟周期处理结束,优化以最小化变值向量长度,并积极使用fp16而不是fp32,因此可以提高应用程序性能。
texture unit
纹理单元实现所有纹理内存访问。每个核心包含16KB的L1数据缓存,它由共享的L2缓存支持。该块在malig – g71中的架构性能与早期的Midgard gpu相同;它每个时钟可以返回一个双线性过滤(GL_LINEAR_MIPMAP_NEAREST) texel。例如,为一个四线程quad中的每个线程插入一个双线性纹理查找将需要四个周期。
一些纹理访问模式需要多个周期来生成数据:
- 三线性滤波(GL_LINEAR_MIPMAP_LINEAR)每个texel需要两个双线性样本,因此每个texel需要两个周期。
- 体积三维纹理需要的周期数是二维纹理的两倍;例如,三线性滤波的3D纹理需要4个周期,双线性滤波的3D纹理需要2个周期。
- 宽类型纹理格式(每个颜色通道16位或更多)可能需要每个像素多个周期。
宽格式规则的一个例外是深度纹理采样,这是Bifrost中一个新的优化。来自DEPTH_COMPONENT16或DEPTH_COMPONENT24纹理的采样(阴影映射技术和延迟光照算法通常都需要这些纹理)已经优化,现在是一个单周期查找,与Midgard系列中的gpu相比,性能提高了一倍。
以上是关于bifrost架构的简单介绍,主要介绍了该架构中计算相关的处理单元,关于渲染相关的,这里不做介绍。

