Pblk: Physical Block Device
物理块设备(pblk)是LightNVM target,实现了完全关联的基于主机的FTL,该FTL公开了传统的块I/O接口。本质上,pblk的主要职责是:
- 处理控制器和特定介质之间的约束 (例如,缓存必要的数据量来对Flash页进行编程)
- 将逻辑地址映射到物理地址(4KB粒度),并确保完整性,最终在面对关联映射表(L2P)崩溃时进行恢复
- 处理错误
- 实现垃圾回收
- 处理flush操作:因为典型的闪存页面大于4KB,flush会强制pblk的运行中数据在完成之前存储在设备上,文件系统或应用程序可能需要它
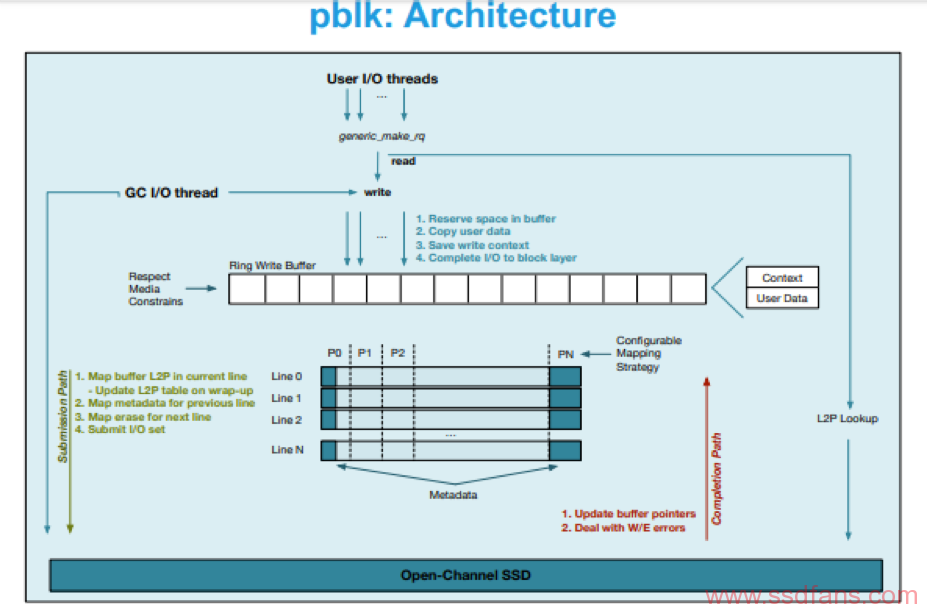
Write Buffering
写缓冲由host进行管理,写缓冲区作为圆环缓冲区进行管理。它在内部分解为两个缓冲区:一个数据缓冲区,用于存储4KB用户数据入口(4KB对应于一个扇区的大小),以及上下文缓冲区,用于存储Perentry元数据。缓冲区的大小是闪存页大小(FPSZ),要写入的闪存页数(下/上页)和PU数(N)的乘积。 例如,如果FPSZ = 64KB,PP = 8,N = 128,则写缓冲区为64MB。写缓冲区由多个产生者和单个使用者访问。
产生者: pblk用户和pblk自己的垃圾收集器都会将I/O作为entry插入写缓冲区。 写入新条目时,将使用条目行更新L2P表,并确认写入。 如果缓冲区已满,则重新安排写入。 如果传递进来的逻辑地址的映射已经存在,则旧条目将无效。
使用者:当有足够的数据填充闪存页面或发出刷新命令时,单个线程将使用缓冲的entries。如果使用multi-plane编程,则还必须考虑plane的数量(例如,具有四个plane编程的16KB页面一次写入需要64KB chunks)。此时,逻辑地址已映射到物理地址(逻辑的chunk->Pus的映射)。 默认情况下,pblk的映射策略针对吞吐量和跨channel和PUs的条带化数据,采用page-mapping。可以使用其他data placement策略。 映射发生后,将形成vector写命令并将其发送到设备上, 需要注意,在刷新的情况下,如果没有足够的数据填充闪存页面,则pblk在发送到设备之前会在写入命令中添加padding(即未映射的数据)。
为了遵守下/上页面对,在映射页面时不修改L2P表。 这样,读取将定向到写入缓冲区,直到所有页对都已保留。 发生这种情况时,将使用物理地址更新L2P表。
用于映射传入的I/O的channel和PUs的数量可以在运行时调整,将它们称为active PUs。
例如,考虑具有4个channel 和8 PUs/Channel的open-channel SSD上有4个active PUs。 首先,PU0,PU8,PU16和PU24处于active状态,page以循环方式(round-robin)写在这些PU上。 当PU0上的一个block填满时,该PU变为inactive状态,PU1接管为active PU。 在任何时间点,只有4个PU处于active状态,但是数据仍以page granularity在所有可用PU上进行条带化。
当应用程序或文件系统发出刷新命令时,pblk确保将所有未完成的数据写入介质。使用者线程清空写缓冲区,并在必要时使用padding来填充最后一个闪存page。 随着数据的保留,最后的写命令将保留一个额外的注释,该注释指示必须在刷新成功之前完成它。
Pblk: Data Placement
- 完全关联的L2P表
- 映射粒度4KB(1GB per 1TB)
- 预填充的bitmap encoding map
- bitmap编码不良块和元数据
- 在快速路径上节省昂贵的计算(division/modulus)
- L2P映射与I/O scheduling分离
- 轻松添加新的映射策略
- 简化错误的处理
- 不一定会影响磁盘格式
- 默认:
- 跨channels和LUNs进行条带化以优化吞吐量
- 元数据在每个line的开头和结尾
Pblk: I/O Scheduling
- 目标
- 充分利用介质带宽
- 例如:1 core (E5-2620, 2.4GHz) can move ~3.7GB/s
- 最小化达到稳态的影响
- 根据设备的容量对用户和GC I/O进行速率限制
- 充分利用介质带宽
- 单个写线程
- 在映射缓冲区entries时提交用户写的I/O
- 提交前一line元数据的写入I/O
- 与用户数据保持一致,以最大程度地减少干扰
- 提交擦除I/O用于下一line
- 与用户数据保持一致,以最大程度地减少干扰
- 在所有lines上分配擦除价格
Pblk: Mapping Table Recovery
Pblk: Error Handling
Pblk: Garbage Collection
- 基于有效sector数的基于成本的回收模式
- 在一line中将X LUNs专用于GC
- 速率限制用户I/O是设备容量的函数
- GC专用写缓冲区(共享缓冲区容量的百分比)
- 在line上分开热/冷数据
- 两种可用的GC模式
- 使用host的CPU来搬移数据
- 几个GC读取线程
- 将数据复制到GC缓冲区
- 在写线程中提交GC I/O
- 可选:使用vector复制命令
- 使用host的CPU来搬移数据
任何log-structured的FTL,pblk必须实现垃圾收集。通过垃圾回收任何有效页并返回块以进行新写入来重新利用块。假定在设备上或在LightNVM内核中发生了Wear-leveling。 因此,pblk只需为每个块维护一个有效页数,然后选择有效扇区数最少的块进行回收。
逻辑到物理映射表的逆序未存储在host内存中。 为了找到反向映射,利用了一个事实,即块在完全写入后首先被回收。 因此,可以使用存储的部分L2P表在块的最后一页上进行恢复。 如果该块中的页面仍然有效,则将其排队等待重写。 安全地重写了所有页面后,原始块将被回收。
为了防止用户I/Os干扰垃圾回收,pblk实现了PID控制的速率限制器,其反馈循环基于可用空闲块的总数。当可用块的数量低于可配置的阈值时,GC将启动。 注意也可以从sysfs管理GC。刚开始,GC和用户I/O都在争夺写缓冲区。 但是,随着可用块数量的减少,GC会被优先排序,以确保已经持久保存的数据的一致性。反馈循环可确保传入的I/O和GC I/O趋于稳定状态,在此状态下,给定用户I/O工作负载,将应用足够的垃圾回收。速率限制器使用写缓冲区entry作为控制传入I/O的方法。 根据反馈回路保留条目。 如果设备达到其容量,则用户I/O将被完全禁用,直到有足够的可用块可用。

