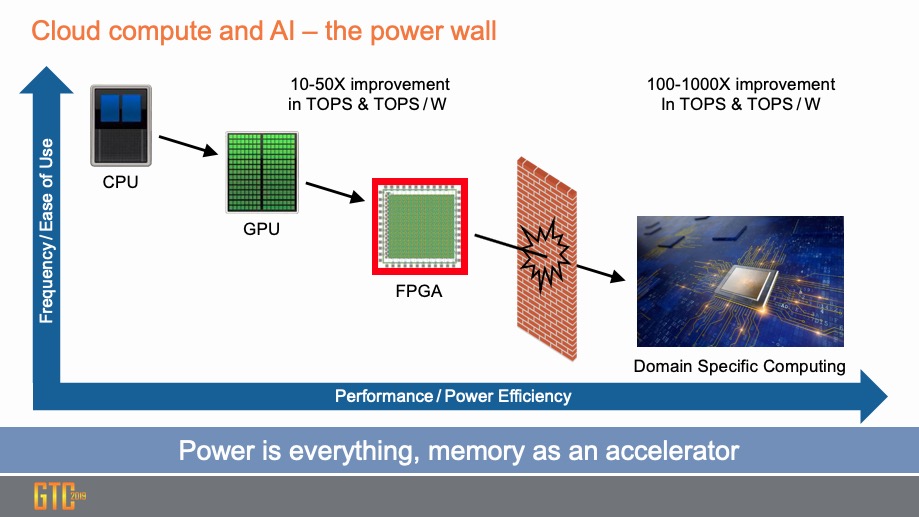
自从机器学习(ML)出现以来,用于解决传统计算无法解决的复杂问题的速度在不断加快。即使在神经网络设计方面取得了进步,机器学习的效率和准确性还是高度依赖于训练过程。用于训练的方法已从基于CPU的软件发展到GPU和FPGA,由于它们的并行性而具有很大的优势。但是,使用专门设计的领域特定计算解决方案具有明显的优势。
因为训练过程的计算密集性极高,所以整体性能和单位性能都非常重要。数据显示,运行训练过程时,领域特定的硬件可以比GPU和FPGA改善几个数量级。
去年12月12日,GLOBALFOUNDRIES(GF)和Enflame Technology宣布了用于数据中心训练的深度学习加速器解决方案。Enflame Cloudblazer T10在GF的12LP FinFET平台上使用2.5D封装的深度思考单元(DTU)。T10拥有超过140亿个晶体管。它使用PCIe 4.0和Enflame Smart Link进行通信。 AI加速器支持多种数据类型,包括FP32,FP16,BF16,Int8,Int16,Int32等。
Enflame DTU核心具有32个可扩展智能处理器(SIP)。每组8个SIP用于在DTU中创建4个可扩展的智能集群(SIC)。HBM2用于为处理元件提供高速存储。DTU和HBM2与2.5D封装集成在一起。
该设计突出了GF的12LP FinFET工艺的一些优势。由于ML训练中的SRAM利用率很高,因此SRAM功耗会在电源效率中起主要作用。GF的12LP低压SRAM大大降低了该设计的功耗。12LP的另一个优点是与28nm或7nm相比,互连效率更高。虽然7nm提供较小的特征尺寸,但对于更高级别的金属,其布线密度没有得到相应的改善。这意味着对于像DTU这样的高度连接的设计,12LP提供了独特高效的过程节点。Enflame T10已被采样,计划于2020年初在位于纽约马耳他的GF 8号工厂生产。
像Enflame这样的公司在设计T10这种加速器时必须走非常好的路线。机器学习的特定要求决定了设计的许多架构决策。片上通信和可重配置性是必不可少的特性。T10的片上重配置算法在该领域表现出色。他们选择12LP,意味着在不需要承担高级节点更高风险和费用情况下可以获得最佳性能。GF能够在集成解决方案中提供HBM2和2.5D封装,从而进一步降低了项目的风险和复杂性。
通常情况下,增加训练数据集可以改善ML应用程序的性能。处理这些不断增加的工作负载的唯一方法是使用专门针对该任务而设计的快速高效的加速器。CloudBlazer T10似乎是解决这一问题的一个完美解决方案。

