概述
AMD目前对自家企业级EPYC2 CPU北桥的设计一致三缄其口,只是承认了它只是分为4个节点(quadrant)拼成,每个节点负责自己的内存pcie总线等;如果应用是numa-aware的话可以开启NPS-2或者NPS-4,使得每个(或者每2个)节点只存取各自分配的内存通道而不需要经常跨节点访问远端的内存,从而达到降低延迟提升总带宽的目的。至于具体北桥里面4个节点怎么连接、连接的总线有什么延迟带宽特性等,AMD甚至在开发指南里都从来没详细说明过。按目前已经发布半年了,而且目前关注焦点在zen3 milan的情况看,可能我们永远不会有一个官方答案。

方法1:
将CPU设置成NPS-4,这时CPU会被划分成4个NUMA节点,其中每一个NUMA节点代表北桥中的一个节点。
在这种情况下直接运行intel memory latency checker,我们可以得到2个表格。上面一个表格是每个NUMA节点访问其他节点的内存的空闲延迟,下面一个表格是各节点访问其他节点所属内存的带宽。
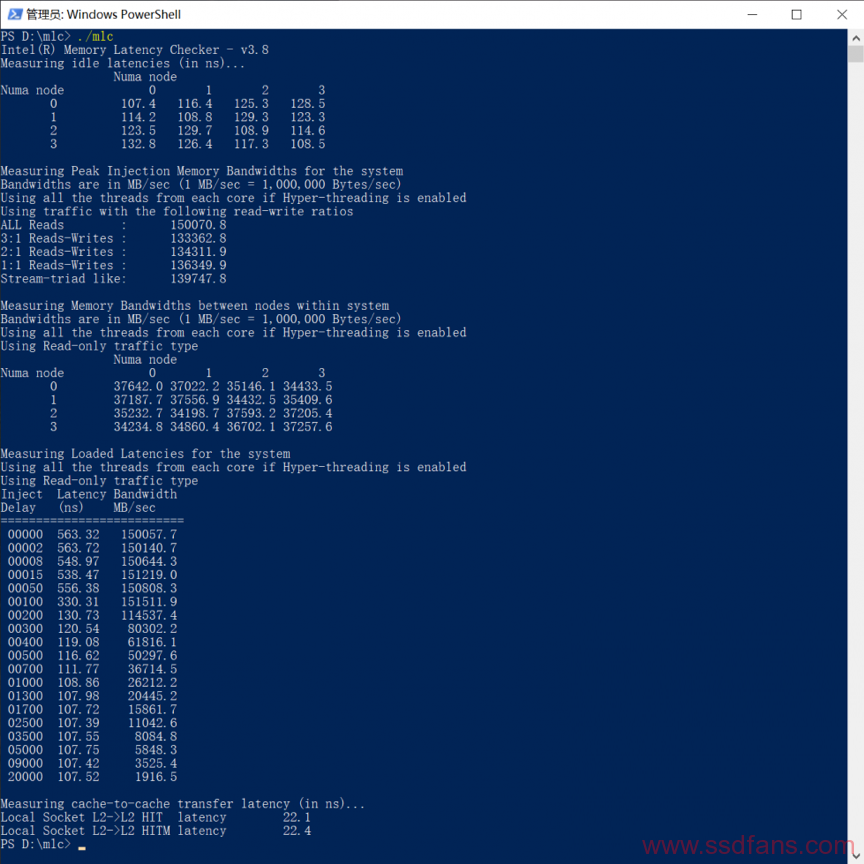
这两个表格可以分析出延迟的信息。同时我们也可以看到远的2个节点到近的2个节点带宽小一些这个现象,不过跨节点带宽本身也差不多够每个节点的双通道内存使用了。这里我们主要关注延迟方面。
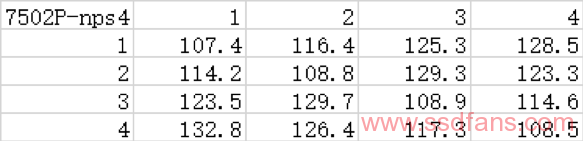
每个数据都包含核心到北桥节点和北桥到内存的延迟,这两个延迟是不需要的。所以我们将每一个数据减去一个节点访问本地内存的延迟(约107.4ns),这样我们就可以得到北桥内部每个节点到每个节点的延迟。
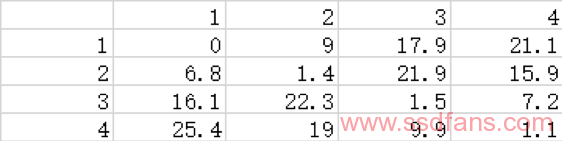
这个测试方法得出的结果很干净,可以有效减轻排除各种snoop机制的干扰。mlc工具各项测试原理的说明很完善,结果也是比较可信的;如果你仍然不想用这个工具,你也可以选择passmark或者微软X-mem之类其他可以测量NUMA节点之间距离的工具进行测试,不过精度不一定有mlc那么高。
https://nanocad-lab.github.io/X-Mem/
方法2:
利用mlc的c2c_latency延迟测试功能。
mlc的说明文档对这个功能的描述如下:
mlc –c2c_latency –c2 –w22 –b200000 –C128
The above command is used to measure the time taken to transfer a modified line from L2 cache to another core on a different socket. Writer thread ‘w’ pinned to cpu 22 modifies 128KB of data (as specified in –C parameter) and transfers control to reader thread ‘c’ on cpu 2. Now, this thread reads the same 128KB of data that is currently resident in L2 of thread 22. Since those lines are in M state, the snoop responses would be Hit-modified (aka HITM) and the line would be transferred from the cache to the requester. Then the control is transferred back to the writer thread and this thread would move the window to another 128KB range in the buffer specified by –b parameter and the process will be repeated.
简单的说,首先发射核心读取并修改一定大小的数据块,这时修改过的数据存在发射核心的L2缓存中。然后接收核心开始读取些数据,这时接收核心就会发现这些数据已经被其他核心改动过(HITM状态),所以读取时会通过核心间互联总线从发射核心处读取。这样,通过测量传输时间,我们就能得到发射和接收核心之间数据传输的延迟。
依此我们可以编写脚本进行测试。脚本一个例子如下,采用全随机存取以避免预取干扰,每次测试数据窗口为默认的2000KB,总测试区间200000KB,测量每个节点中的1个核心到其他ccx和到其他节点中核心的延迟,遍历所有节点并记录每2个节点来回的数据。结果如下,cpu为EPYC2 7702(1333)和3990X(1600)。
mlc –c2c_latency -c0 -w16 -e -r ::w为发射核心,c为接受核心
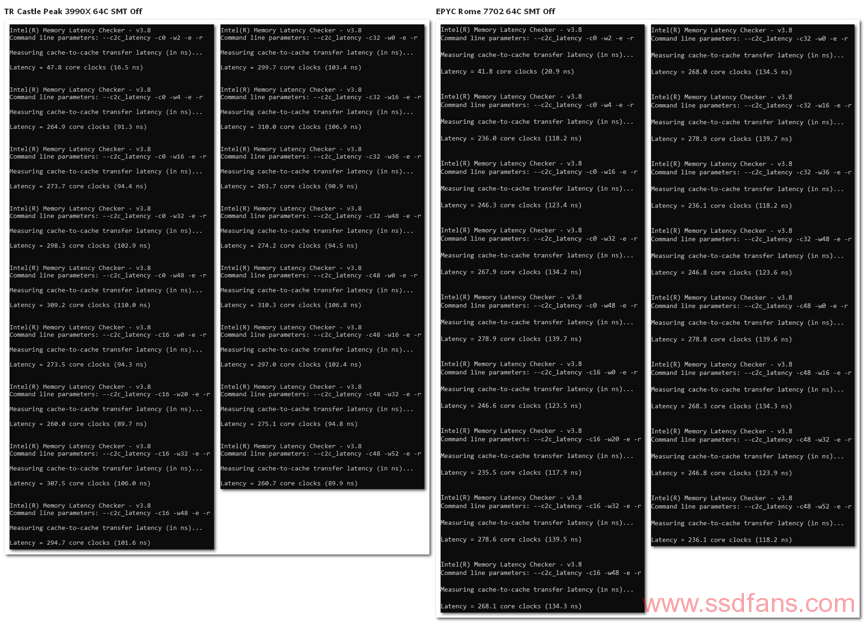
我们将数据进行整理可得下表,表中的数值是每个北桥节点的“代表核心”与其他代表核心之间通讯的延迟。
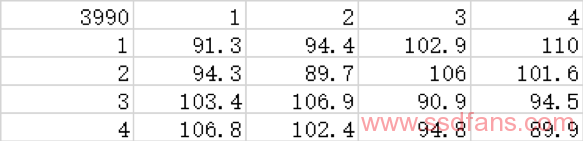
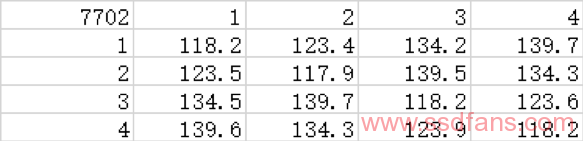
同样,这个数据也包含了核心与北桥节点之间的交流延迟。按照方法1的做法,我们减去这个不必要的本地延迟,可得:
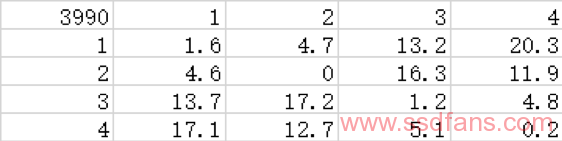
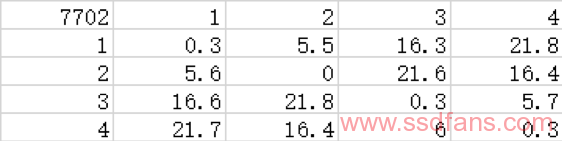
这个结果更加干净,我们据此可以很容易得出北桥内四个节点的互联结构;同时我们可以看到,3990x更高的if频率对节点内和节点1-3、2-4这种“长边”延迟性能的作用比1-2、3-4这种“短边”更大。
方法3:
对于测量核心间延迟,像mlc这样非常正规的工具很难找。如果你不想用这个工具的话,也可以使用cloud(地雷云)的cache_to_cache工具。这个工具的原理是让一个cpu核心的数据传到另一个核心再传回来,从核心0到1开始一直到最后一个核心,然后从头从核心1到2开始到最后一个核心,反复直到跑到倒数第二个核心和最后一个核心为止。
使用EPYC2 7452,测试结果如下(已除以2换算成单程延迟):
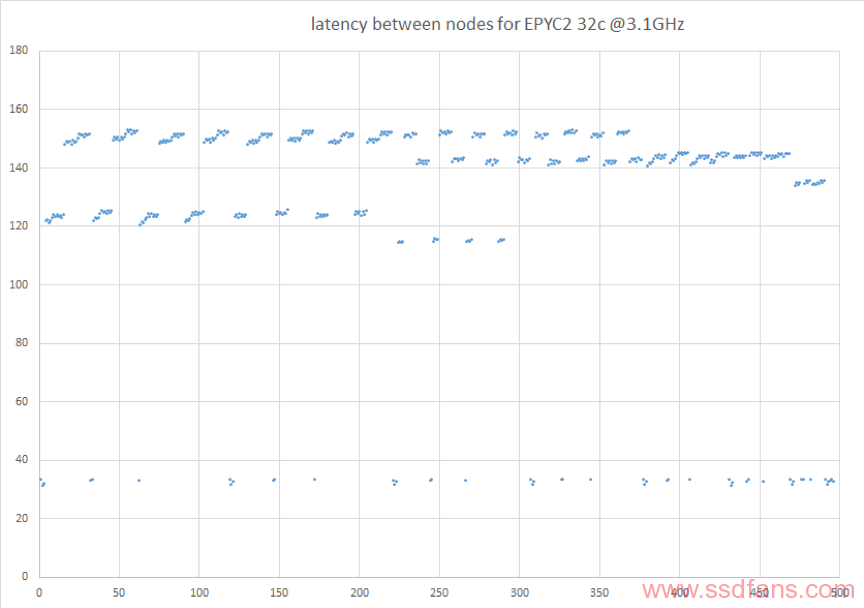
我们可以很清楚的看到,每个核心一般首先访问ccx内的核心,延迟较小;然后访问同北桥节点的其他ccx内的核心,延迟变大;最后访问各其他北桥节点的核心,延迟逐渐增加到最大。这样每个核心的数据基本上就是很明显的一组,里面有5个层次的延迟。对于第一个核心来说,核心到其他节点的延迟依次增加。
然后我们把北桥第一个节点中的8个核心排除,看第二个节点8个核心的数据:
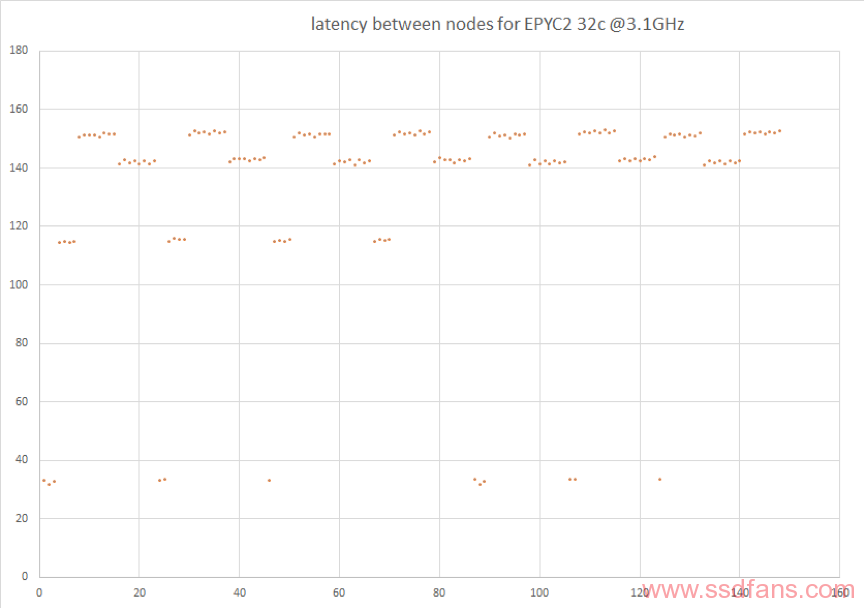
这里就很明显了,除去CCX内极低的和节点内部较低的部分,第二节点到第三节点的距离比到第四个节点更远。结合第一个节点对2、3、4节点的延迟依次增加看出,这4个节点的排列不是线型的,有环存在。这样我们就可以得出大致结果。
这个测试的可信度还是比较高的,其结果和mlc接近,当用于测量intel cpu时结果和官方测试相差很小,而且能明显看出cpu内部的结构。测试结果的稳定性也很好。
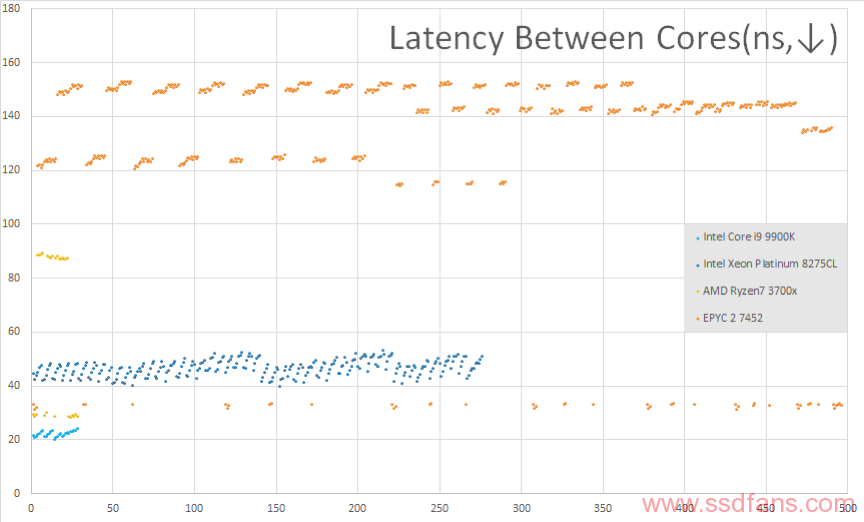
总结:
我们可以通过一个图总结一下上面三个测试的结果。考虑简化表达,有些连接节点的延迟也算在传输延迟内,不过用于进行各组件间延迟的计算也够了。当然这个图并不是官方的,很多延迟上下限由下面列举的软件测试得出,延迟本身也与访问类型、大小、snoop机制等因素有关,请注意。
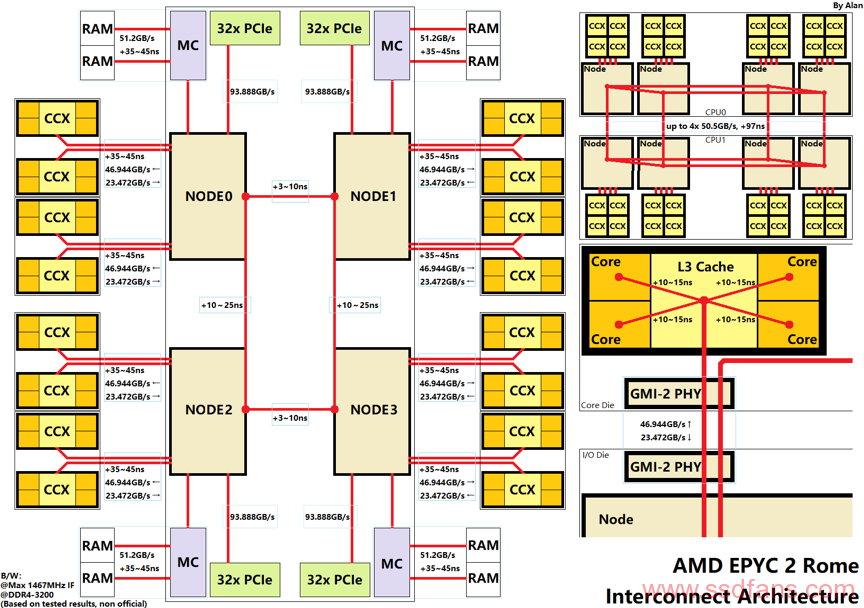
图中数值解释:
1. 各组件的带宽均由官方标称结合IF频率换算,如每个ccd的phy读取速率为32bit/cycle,写入速率为16bit/cycle.
2. 北桥中4个节点的通讯延迟最小值由cache_to_cache(短边)和LambdaDelta的新测试给出,最大值长边为mlc和cache-to-cache的结果给出,短边由sisoft sandra的测试得出。
3. 核心通过L3与北桥连接,核心到L3的延迟和核心频率有关;L3以外的部分与IF频率和内存频率有关。
4. imc+内存延迟由NPS1下的C2C延迟和空闲内存延迟(idle_latency)换算得出,内存有负载时延迟会增大。
5. 跨cpu的延迟和带宽由HPE的ppt和技嘉的RD给出:

于是,AMD EPYC2 Rome的拓扑大致分为3级:
1. 内部4个节点(quadrant)组成一个长方形。和传统环形总线cpu不太相同,其传输过程的延迟(而不是连接到总线的延迟)占主导。
2. 每个节点到4个CCX为星型总线(节点内部为全互联)。
3. CCX内L3内部也为全互联。
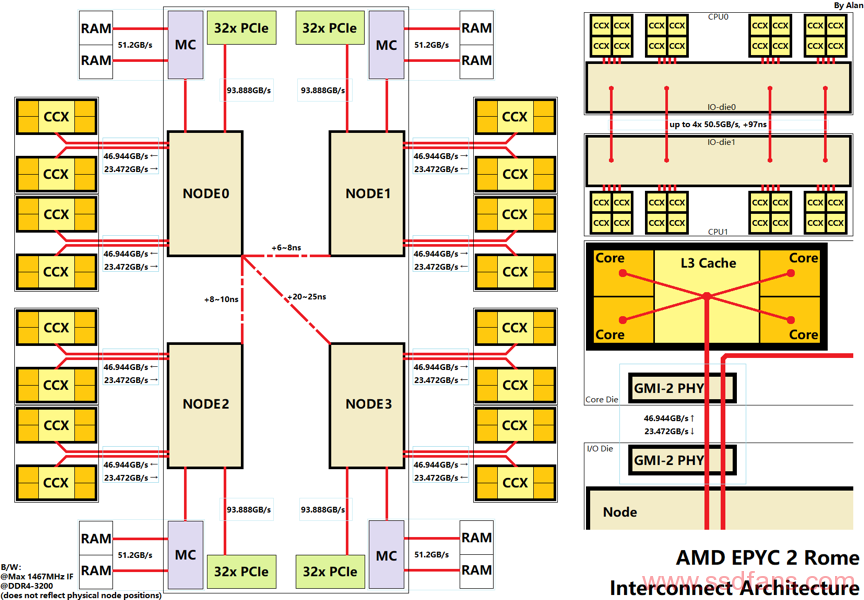
至于这个总线设计的性能相对于其他已有拓扑好不好,请自行评价。下面是仅包含官方公布数值的图:
其他:
1. 参考文献:
cloud – AMD銳龍第三代處理器+ROG C8H首測:尋根Zen 2性能本源
LambdaDelta – 3900X个人详细测试
HPE – 第二世代 EPYCプロセッサ “ROME” のご紹介
Patrick Kennedy – AMD EPYC 7002 Rome CPUs with Half Memory Bandwidth
2. Threadripper 3990x的内存结构:
也写了一个脚本来测试这方面问题。结果是4个节点的核心到内存的延迟基本相同。可能3990x真的走线走成每个节点一条内存通道,而不是2990那样2个节点有2个没有。
Intel(R) Memory Latency Checker – v3.8
Command line parameters: –idle_latency -c0 -i0 -e -r
Using buffer size of 600.000MiB
Each iteration took 284.5 core clocks ( 98.1 ns)
Intel(R) Memory Latency Checker – v3.8
Command line parameters: –idle_latency -c16 -i16 -e -r
Using buffer size of 600.000MiB
Each iteration took 279.5 core clocks ( 96.4 ns)
Intel(R) Memory Latency Checker – v3.8
Command line parameters: –idle_latency -c32 -i32 -e -r
Using buffer size of 600.000MiB
Each iteration took 281.2 core clocks ( 97.0 ns)
Intel(R) Memory Latency Checker – v3.8
Command line parameters: –idle_latency -c48 -i48 -e -r
Using buffer size of 600.000MiB
Each iteration took 283.8 core clocks ( 97.9 ns)
- 另外,如果要自行改动或者想编写新的测试软件,请注意总buffer和每一次测试的window大小不能太小,否则可能会测出不符合常理的低数值。

