1. 前言
其实万恶之源就是各家渲染工具测出来各个cpu的效率明显不一样。初步分析cpu之间的差距和模型(包括光源和高级贴图等因素)关系最大,和不同渲染器和渲染方式关系不大。但是这个差距是为什么产生的,也就是不同模型的“性能特征”区别,仍然是个疑问。
为了弄清楚这个问题,从而搞清渲染应该用什么样的工具测试才能更好地表现真实渲染性能这个终极问题,我翻了一下手上3d模型的存货,找到一个家装模型。这个模型本身还是有点简单,见过的某些设计光一个吊灯就比这个场景复杂。。。不过也够用了,我可以通过增删一些asset的方法改变场景复杂度。
测试分6个复杂度等级5个模型,使用vtune性能分析工具的“microarchitecture exploration”模式,通过直接均匀取样统计低层CPU硬件事件的方式,记录渲染时各硬件资源需求在实际渲染中的占比,看看渲染负载吃什么方面性能,吃多少。
在开始之前,先简单介绍一下标题的“高模”。什么是高模呢?简单地说:

左边是低模正方体,右边是“高模”正方体(其实根本不“高”,随手建的,看个意思)。简单说,高模的“高”指的是多边形数量等复杂度参数,通过分割倒角挤压乃至导入专用软件雕刻等使模型结构本身变复杂的方式来展现出细节,而低模往往模型本身形状很简单,仅通过贴图来增加细节。所以高模常用于追求图像品质的预渲染的影视图像,低模常用于对性能要求比较高的游戏等应用(也不绝对)。当然也存在介于两者之间号称结合两者优点的的“次世代”模型,不过建起来相对麻烦,往往需要高低2个模型结合匹配,这里就不细说了。
那“高模”和上一篇里的“硬表面模型”有什么关系呢?业界没有明确定义。有些人认为“高模”就是“硬表面模型”,这么理解未尝不可,因为这两个概念的中心思想就是通过“实际模型结构复杂”而不是光靠贴图来表现细节;当然硬表面模型也有不少精度不是那么高,这方面来说两个概念也有区别。我的理解,“硬表面”这个概念与模型描绘的是什么东西没有必然联系,而主要与建模方式、建模目的和模型拓扑有关。比如下面这个硬表面模型描绘的是个软的东西。

为什么要强调“高模”呢?因为复杂的模型(场景)配合各种复杂的材质系统和光照,其性能特征很可能和简单模型场景不一样。下文将详细测试分析这种区别。
2. 基础场景简介:

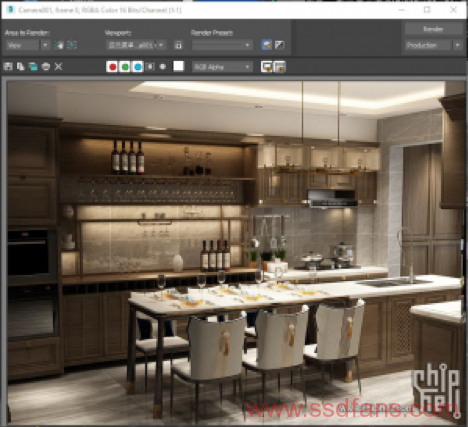
此场景选用vray for 3dsmax构建和渲染。采用全局照明(Global Illumination),这点可以通过光来回反射产生的“染色”现象看出。整个场景具有多种不同材质,但是仅有植物带有normal map,其他材质都相对简单。图中锅和厨具部分可以造成漫反射,大理石和烤箱可以造成反射,玻璃杯和灯具有折射和透射特性。光源方面除了灯光外屋顶和柜台部分设置了一些补光。各个物品互相遮挡可以产生soft shadow。总体来说该有的特性基本都有了。总面数384万,属于比较简单的场景。
测试使用vray for 3dsmax 2019(4.30.00), 分6项5个模型,在不标明的情况下使用800×600分辨率progressive(min_shading_rate=6, render_time(min)=1)渲染,从光源准备结束开始记录到渲染结束为止。后面会测试提高分辨率的情况和bucket(块渲染)模式和progressive(渐进式)模式的对比。
另外此测试模型大部分不是我建的,有知道来源可以回复备注一下。
3. 测试内容:
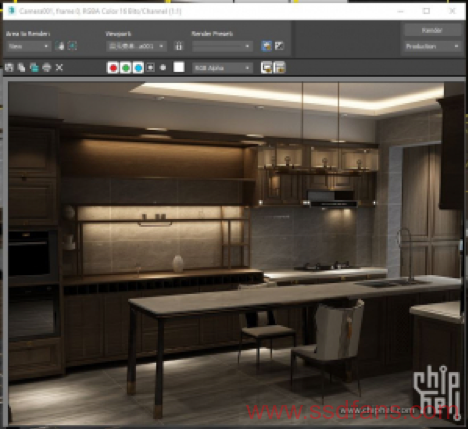
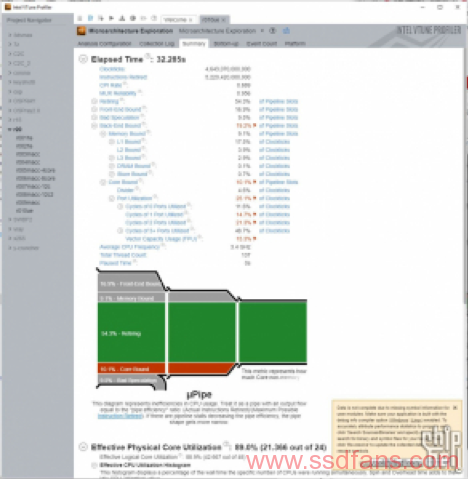
首先测试原始模型的。下图为渲染完成图和vtune抓取的负载情况。
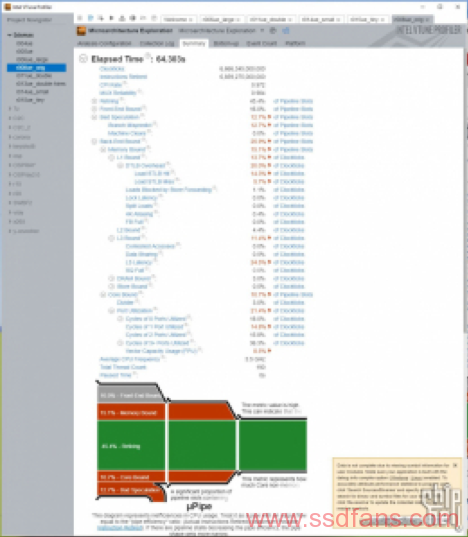
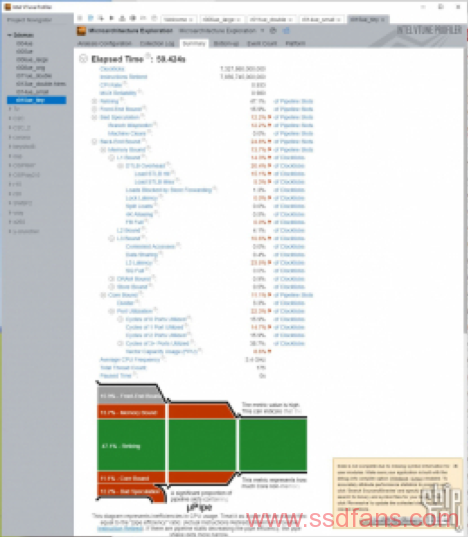
数据可靠性为0.984,测试没有问题。这里我们可以看到vray硬件利用率的一些信息,比如CPI(IPC的倒数)在1附近比较高,有效物理核心利用率72%,整体性能并不能完全利用CPU流水线,还有很多核心以外的部分影响性能。其实这也是目前测过大部分软件的一个常态,毕竟不是啥软件都能像HPC应用一样具有那么高的优化投入和优化潜力。内存缓存方面我们重点关注这几个参数:L1、L2、L3、DRAM bound,代表CPU等待缓存和内存操作而无法工作的情况占总时间(时钟周期数量)的百分比。
接下来,通过复制很多物件并增加视野内物件种类的方式增加模型和渲染过程的复杂度。结果如下:
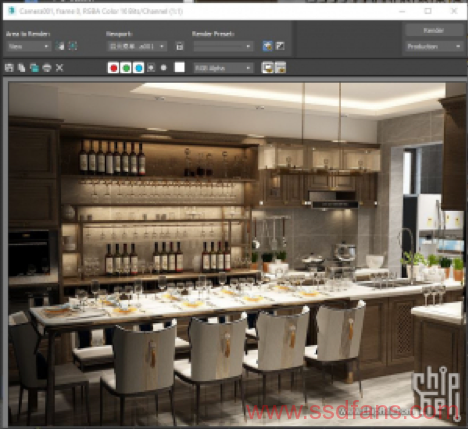
此时面数为581万,仍然属于比较小的模型。但是场景本身就比较小,不太好继续添加物件了。
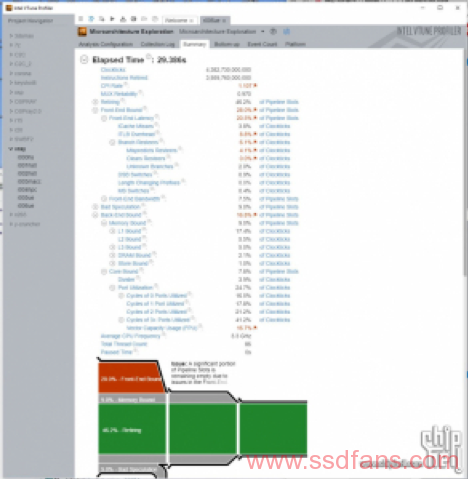
此时的性能指标如下:
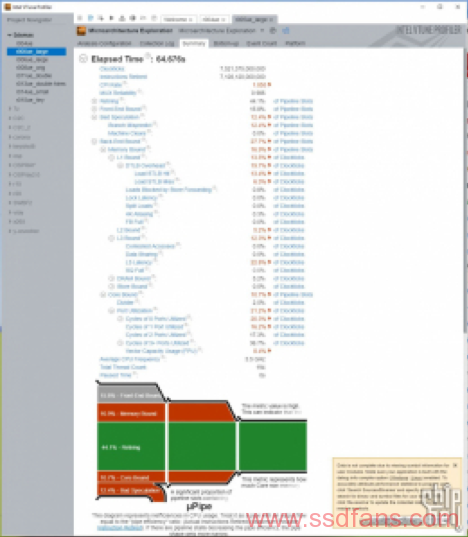
这时DRAM bound的数值上升到5.2%,CPU缓存部分倒是没有什么明显变化。有效核心利用率76%。
此场景规模还是比较小,所以我复制了2个场景拼接成一个大的。这时场景的面数刚过千万(1021万)。虽然对于一般的室内设计工程模型还是很低,但是这个场景应该没有太大修改的潜力了。毕竟不能把一个小的房间场景做成一个菜市场。。。另外下面还会有更高分辨率的测试。
此时的性能信息如下:
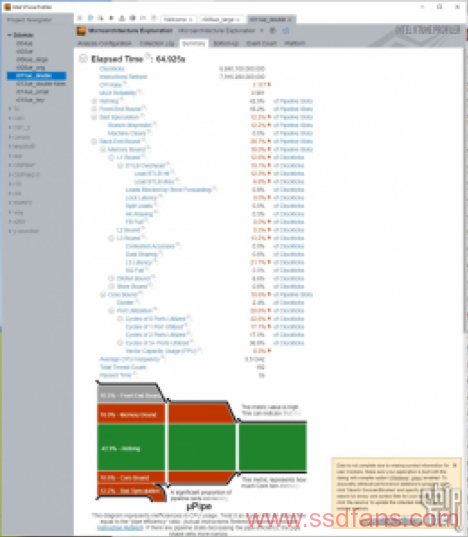
DRAM bound上升到6.6%,已经比原来的小模型高了一倍多,但是考虑很多材质模型重复利用,这个6.6%的数值仍然偏低。有效核心利用率也上升到86.4%。当然这只是800×600下的结果,接下来我们将分辨率设置成1920×1080,渲染时间设置成5分钟看看。虽然模型还是偏简单,但是这种条件下已经比较接近实际了。
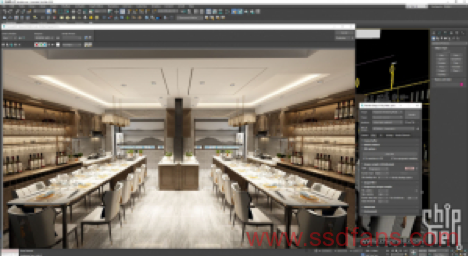
性能指标:
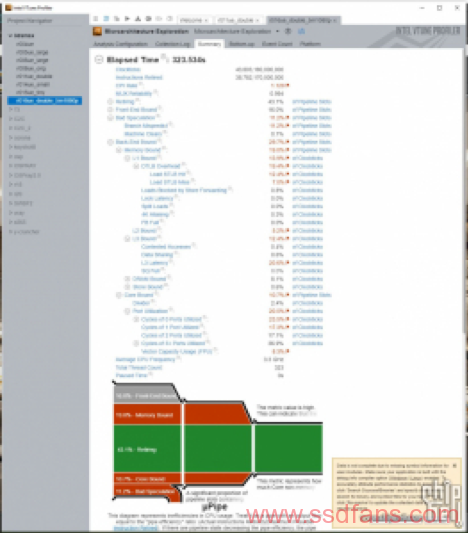
此时dram bound继续上升到8.1%,已经不是一个可以忽视的数值了。核心利用率也上升到90%。CPU缓存的占比反而并没有多少增加,相对于默认情况L2只增加了0.8%,L3占比提升幅度则为1%。这一套下来反倒其他方面性能占比都没有太大变化。
那么用相反的思路,降低模型复杂度是否可以降低DRAM bound呢?答案是肯定的。缩减复杂和透明物体数量并减少补光光源后,模型如下:
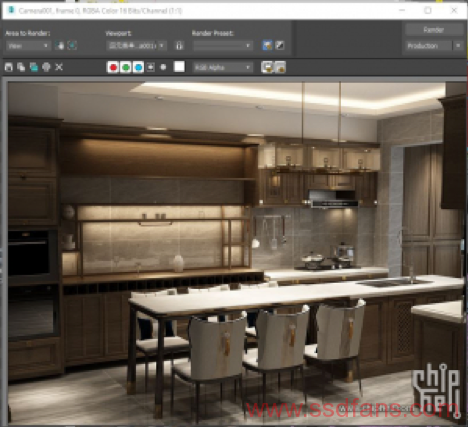
性能指标:
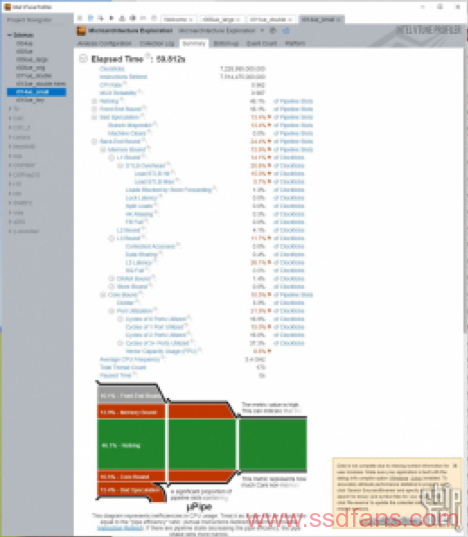
简单的模型中DRAM bound有效降低到1.4%。此时有效核心利用率为84.6%。我试图继续减小模型复杂度看能不能做到cinebench的1%以内,虽然比较困难,但是通过削减掉几乎所有的补光光源和多余的asset以后,我们得到这张图。这时DRAM bound可以达到0.9%,其他性能指标变化不大。
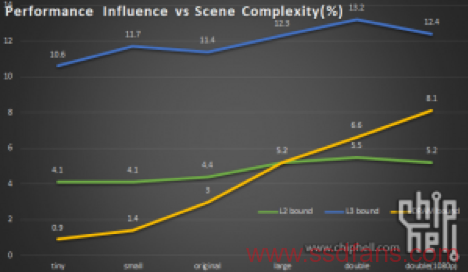
我们把所有图总结一下。可以看到,随着模型本身越来越复杂以及渲染分辨率增加,渲染性能中取用内存缓存的开支占比呈总体上升趋势。特别是内存方面,由一个1%以内的数值上升到8.1%。如果场景继续变复杂的话这个数值仍然有加大的可能。这也是需要强调“模型跑在内存还是缓存里”的原因。
总结:
1. 模型复杂度与渲染跑在内存里的“量”(操作内存占用的时钟周期数量)直接相关,越复杂的模型缓存越“不够用”,读写内存的频率会越高。复杂度和模型体积大小有关系但是不是绝对的,毕竟光源、各种折射反射和normal map之类并没有算在内。不过仍然推荐在不知情的情况下尽量选用模型较大(或者系统资源占用较大)的测试软件,因为很多跑分软件都有体积很小跑在缓存里的问题,并不能全面衡量性能。这和小白选电源一个道理:越重的电源越好显然是错误的,但是砸脑袋上都不疼的货,除非他是特殊设计或者别的标准,否则一般不会是什么好东西。。。
当然能够直接分析测试场景更好了。另外似乎vray之类渲染器申请的内存不一定都会使用,所以不要被任务管理器吓到。。。
2. vray的progressive渲染在默认设置下,时间似乎没有可对比性,有时候复杂的多的模型渲染时间不会增加多少,还有降低的可能。实际上设置里有一项就是大致渲染时间,默认为1(min),实际渲染时间可能长可能短,出来的精度也不太一样。可能他会按照实际硬件预估精度吧。
3. 分享几个现成渲染跑分的性能指标(按次序:新版vray,旧版vray,CB R20,corona):
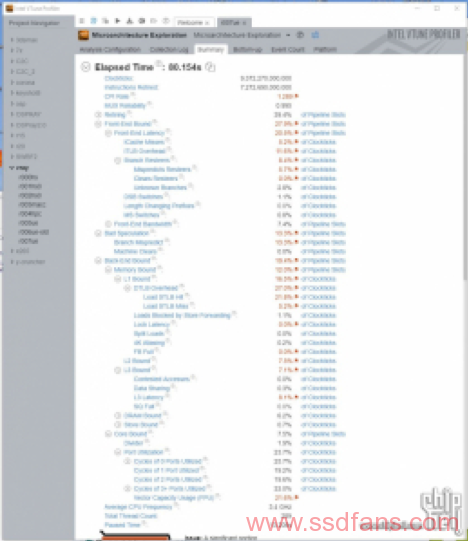

考虑到性能特性是否接近实际渲染,以及成绩的稳定性因素,我认为corona和新版vray可信度高一些。至少相对于这个实际的复杂模型和之前跑的另一个工业模型来说,CB系列有点跑偏了。一个渲染测试的制作者当然会考虑到测试里包含哪些材质、哪些渲染器特性等渲染器本身的内容,但是他们不一定会考虑到不同cpu具有不同的特点。
当然最好是拿自己的实际模型跑,毕竟这些跑分和你的实际模型可能还有点区别,而且它们跑的结果一般不包括准备光源之类的时间。纠结AMD还是intel的话,都买就不会出错,大不了跑完卖。。。
4. 选用progressive(渐近式)还是bucket(块渲染)渲染模式?参考一下默认设置下两个的渲染时间和出图精度:
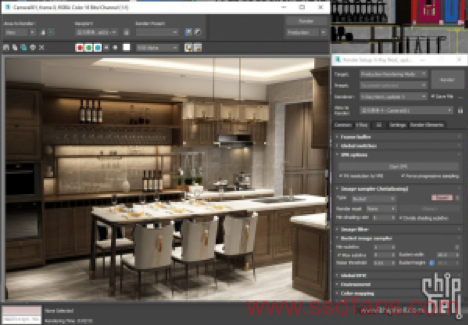
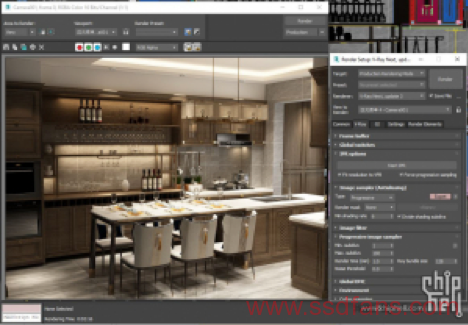
以及时间接近的两种渲染模式的画质(原图见网盘):


按照这个个例来说,建议建模调试过程中用progressive,因为很快就能看到质量相对较高的结果方便调整;最终出图可以根据调试过程的经验选择,按我目前的了解不同的图两者渲染速度不一样。
哪个是“未来”?谁都说不准,但是我看好progressive一些,因为它的并行度更好可操控性更佳。GPU光线追踪渲染已经开始搅局了,如果GPU那么高的并行处理能力能发挥全力的话恐怕就算128核的cpu也并不是对手。。。
然而我们并不是活在未来,所以建议脚踏实地一些。
5. 本测试开源,提供所有测试模型和数据截图可以自己重演,如模型不给再配布请联系删除。

