作者:李大虾
Mapping即Address Translation,居FTL之中乃核心,变化出其他FTL技术。按照表内存放的数据内容可以分为direct map和inverse map:
direct map:将logical address映射到physical address,组织方式可以是Array Lookup,也可以是Tree Search,根据需要可以是几级映射,主要存放于Nand Flash中,部分镜像会存放于RAM,用于快速转换。
inverse map:在physical block/page中存放logical address,主要用于GC时候scan valid data和power loss之后恢复所用,常存放于Nand Flash中。
另一种根据mapping的方式划分为4种level mapping:
page-level mapping:logical page number(LPN)到physical page number(PPN)的映射,这种方式灵活且容易分辨cold和hot data,易于控制write amplification(WA)和提高performance,但是RAM的overhead较大。
block-level mapping:LPN映射到logical block number(LBN)和block内page offset的方式,此外需要LBN映射到physical block number(PBN),显而易见这种方式不易分辨cold/hot data及random行为,同时降低了GC performance,但具有较小RAM overhead。
hybrid-level mapping:结合了上述page和block level mapping,是一种折中的方式。既减少了overhead问题也提高了灵活,又分为三种类型:
- 直接使用两个区域,两个区域类型根据access pattern类型或cold/hot类型来区分,即sequential/random area或cold/hot area。比如sequential和cold的用block-level mapping,而random和hot的用page-level mapping。
- 直接分为page-level mapping的缓存区和block-level mapping的数据区,需要定期从缓存区merge有效数据到数据区。随着Nand技术发展,特别是近年来的MLC/TLC,使得这种方式越来越普遍。
- log-based hybrid mapping,与前两种类型相比较,其实这三者区别并非那么明显,如今已发展成相辅相成的模式。这种类型融合了90年代提出的Log-structure File System思想,采用page-level mapping的Blocks区域叫Log Block Area(LBA),采用block-level mapping的Blocks区域叫Data Block Area(DBA)。
variable length mapping:是一种变长的mapping方式,主要通过利用特殊的查找树结构组织(比如B-Tree),以及根据access pattern来调整mapping单元中指示的数据长度,因此支持压缩功能不在话下。
下面将分别举例说明这4种mapping方式,为了避免人生的重复,尽量抓住典型来叙述,下面的叙述要感谢论文A Survey of Address Translation Technologies for Flash Memories,如有讨论,请联系李大虾(mailto:lishizelibin@163.com)或关注微信公众号大虾谈(DaXiaTalking):
-
page-level mapping
-
DFTL:Demand-based FTL
它是page-level mapping方式在学术界的祖师爷。它暴力地将Nand划分为Mapping Blocks和Data Blocks,前者用于存放mapping table,后者用于存放数据,并将部分mapping table(分为Global Mapping Directory/GMD和Global Mapping Table/GMT)缓存到RAM中更新及条件性写入Nand。如下图所示:
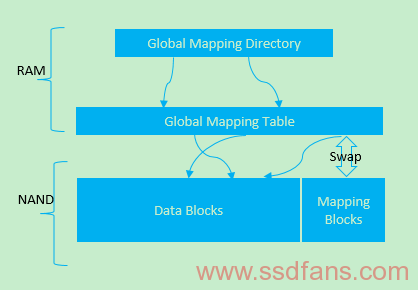
-
lazy FTL
在DFTL的基础上根据数据类型将Nand Blocks做了进一步划分,分为Data Block Area(DBA)、Mapping Block Area(MBA)、Cold Block Area(CBA)和Update Block Area(UBA),这些Block区域的作用顾名思义。一个Write Request直接写入到UBA(涉及表UMT),UBA数据通过merge操作到DBA,DBA可能通过GC将数据搬到CBA,CBA数据可能因为merge操作将数据回归到DBA(涉及表GMT),如下图所示:
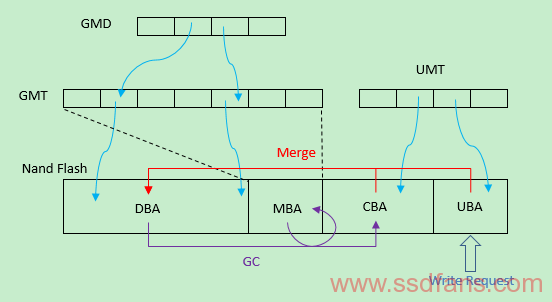
-
CPM:Clustered page-level mapping
这种mapping方式涉及cluster的概念,cluster组织的最小单位可以是两种方式:一种是以block设备的sector大小组织cluster,要求page内可拥有整数倍个sector;另一种是以nand设备的page大小组织cluster。使用cluster的目的是:分开cold和hot data,增加空间局部性,减少因mapping load的overhead。cluster具体大小的选择是一件艺术性的工作,cluster太大会导致cold/hot data容易混合,而太小会导致nand block利用率不高容易发生GC。
名词缩写:
CMT:Cluster Mapping Table
PMT:Page Mapping Table
FMT:Fixed Mapping Table
CIC:Cluster-level Invalid-page Count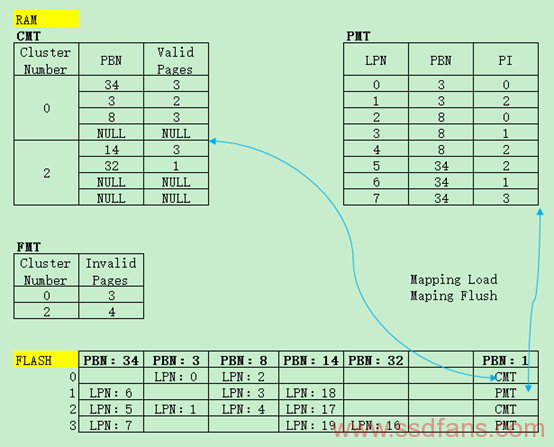
个人认为FMT是个累赘完全可以省略,因为可以实时计算出来,这样可以节省一定RAM空间。同时我也觉得这是个实验室产品,但是其思想还是可以借鉴的。
为了提高Block利用率和延迟GC,采用K-CPM方式,即K-Associative Clustered Page-level Mapping方式,思想是多个Clusters可以共享一个Physical Block,可以想象一下这个思想是可以解决前面所述目的,但是可能增加GC时候Load Mapping Table Overhead。世事总不能尽善尽美,这种堆积设计还会带来POR复杂度。
-
-
block-level mapping
-
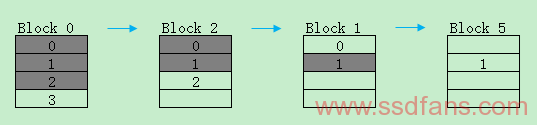
NFTL:
Write:第1次写,写入data block,当page更新时,allocate一个log block写入;
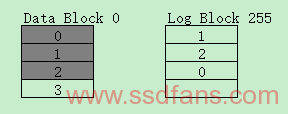
Read:读的时候先查所有log block mapping table,如果数据不在log block再查找data block mapping table;
Merge:log block写满或者GC/WL条件发生,就会从log block和data block中将valid data搬到新的block中,然后这个block被擦除放到free block pool,如果log block从头到尾是顺序的则可以直接将这个log block变为data block,该种方式叫Switch Merge,效率最高,具体将在GC/WL章节叙述。
Mapping Table:可以用Nand Spare区域装载,如果某些原因不方便,也可以用Data Block装载,或使用Replacement Block List:
-
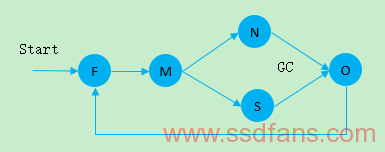
STAFF:State Transition Applied Fast FTL
名词缩写:
F State:空闲Block
M State:按顺序有自己偏移的Log Block,未被填满
N State:不按顺序的Log Block
S State:填满的M State Block
O State:包含Invalid Data,再次分配是会被擦除
状态机如下:
-
Zone-Block FTL:
随着物联网的发展,SLC迎来了第二春,在这种Block Size比较小的情况下,将几个物理块映射为一个Zone,以此进行cache操作和管理。类似前面所述的Clustered page-level mapping操作。
-
-
hybrid-level mapping
这是一种可变幻莫测的映射方式,大概有以下三种类别:
-
直接划分两个区域方式:Adaptive FTL
小块区域用Page Mapping方式,Mapping Table放在RAM中,如果访问就要先找Page Mapping;
大块区域用Block Mapping,类似NFTL方式管理,如果Page Mapping区域空间不足,最久最少使用的Page将复制到NFTL区域。
-
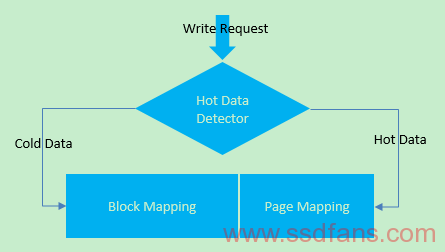
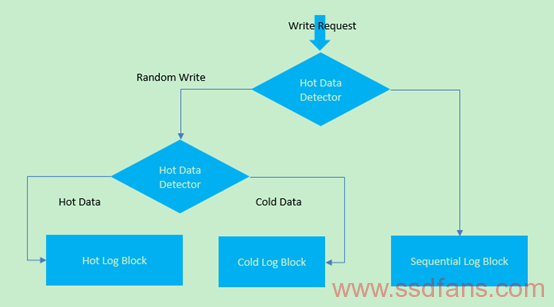
根据数据流类型划分方式:HFTL
HFTL的核心技术是hash-based hot data identification technique,这是一种考虑上层应用(尤其是文件系统)的方法,比如文件系统的中小且频繁更新的Meta Data将被作为Hot Data存放在Page Mapping区域,将减轻GC和WA的恶性发展。如下图所示:
-
Log Based Hybrid Mapping:
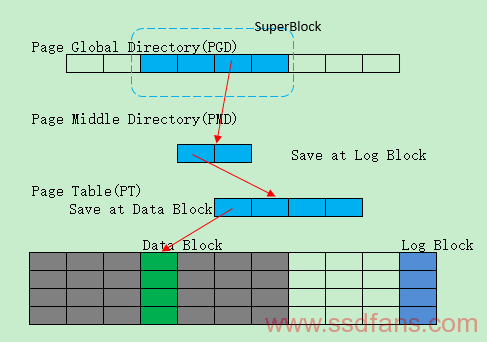
这个是认为最具发展潜力和研究Paper的Mapping方法。目前看来主要有SuperBlock系列,*AST(Associative Sector Translation)系列,大杂烩系列。
SuperBlock FTL:利用空间局部性原理,平衡Log Block的利用率和关联性,由N个逻辑相邻的Data Blocks共享最多K个Log Blocks,分为三级映射:
BAST FTL:Block-Associative Sector Translation,使用较少的Log Block,并且一个Log Block对应于一个Data Block,Log Block是Page Mapping的方式,Data Block则使用类似于NFTL的管理方式。
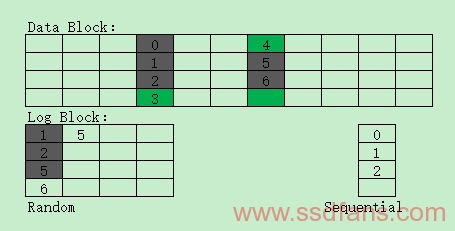
FAST FTL:Fully-Associative Sector Translation,类似于SuperBlock思想,一个Log Block可以被几个Data Block共享。为了增加Partial/Merge操作的机会,保留一个Sequential Log Block进行顺序更新,其他的为随机更新的Log block。如下图所示:
SAST FTL:Set-Associative Sector Translation,也与SuperBlock思想类似,N个逻辑连续的Data Block组成Data Block Group(DBG),然K个Log Block组成Log Block Group(LBG)。这种方法就是一个参数调整的过程,要求平衡N和K的数目,以减少GC的Overhead。在此基础上发展了A-SAST,Adaptive SAST,它不限制LBG大小,并且自适应DBG大小,如果频繁进行Random操作,则会拆分DBG大小,也就是DBG大小变小,随之LBG也跟着变小,以增强空间局部性效果。类似调参数的方法还有KAST(K-Associative Sector Translation),主要是调整Data Block可以关联的Log Block数目K,K的选择据定了走向BAST(小k)还是走向FAST(大K)。调参数最大的痛处就是找到合适的值,发发论文还可以。
LAST FTL:Locality-Aware Sector Translation,该思想发展于FAST和SuperBlock,将Log Block划分为Sequential和Random两个区域,每个区域包含若干个Log Block,但是每个Sequential Log Block只对应于一个Data Block;Random区域再划分为Hot和Cold两个区域,Hot区域使用Cluster概念以加强空间局部性。
进一步说明LAST,如果Sequential Log Block满了,最近最少使用的Block
将被拿来做GC操作,如果Random Log Block满了,且Hot区域不存在任何Valid Data则执行Erase操作,如果Hot区域每个Block都有Valid Data则从Cold区域选择要GC的Block,如果Cold Block数据错误地存放在Hot区域,时间太久的数据就被强制回收。
-
-
variable length mapping
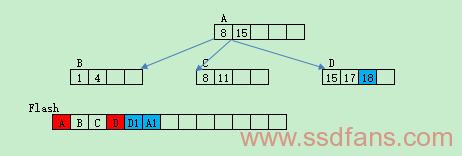
最先接触树状FTL是在UBIFS的Wandering Tree的概念,如下图所示,按照Page顺序操作,从Root A开始依次存放Node,若要在Node D里加入18,则要更新D到新的Page D1中,由于D已经改变位置到D1,因此父节点也要更新到A1。
-
Variable FTL:
将若干个逻辑连续的物理Page设为Cluster,拥有Free&Clean(FC,能被分配给Write Data)状态,Free&Dirty(FD,只包含Invalid Data及可被Erase)状态,Live&Clean(LC,所有Page包含Valid Data)状态,Live&Clean(LD,部分Page包含Valid Data)状态。因此分为Clean树和Dirty树,Dirty树根可以作为回收利用的候选者,举例说明:
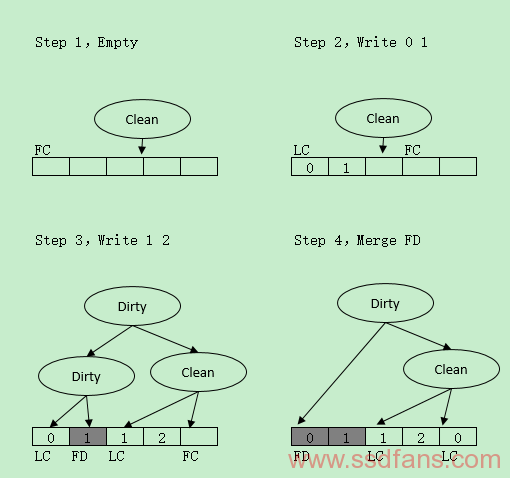
还有一种SAFTL(Self-Adjusting FTL,比那些调固定参数的靠谱),有一个思想不得不说,具有借鉴意义:按照Segement(或者叫Cluster)来进行映射,每个Segment包含Data Area、Free Area和Swap Area,Free Area和Swap Area共享一块Area,前者向后增长,后者向前增长,Swap Area主要用来存放RAM缓存的该Segment里的Page数据。
-
最为广泛应用的B-Tree及其变体FTL,根据以往经验可以划分如下三种类型:
Buffer-Based B-Trees:代表有BFTL,IBSF,WOBF,LA-Tree;
Structure-Modified B-Trees:代表有Wandering Tree,u-Tree,u*-Tree,IPLtree,d-IPLtree,FD-tree;
Hybrid B-Trees:强强联合了Buffer-Based B-Trees和Structure-Modified B-Trees优势,代表有MB-tree,RBFTL,AS B-tree;
下面将分别抓典型叙述这三类B-Trees,在此要感谢论文A Survey of the-State-of-the-Art B-tree Index on Flash Memory:
-
Buffer-Based B-Trees:
主要特点是老生常谈的使用有一些RAM资源来提高FTL性能。对于下面一颗B-Tree的插入操作:

BFTL的操作如下:
对照上图,向Node C中插入Sector 14,插入15时候发现C已满,则删除12(为什么删除12而不是11,因为该Node最大存储量为4),并将12插入到父Node A,同时将12插入到新Node D中,删除C中大于12的14,并将14插入到Node D中,再在Node D中分别插入15和18。
可以明显看出,因为操作顺序可能导致每个Node包含的Sector内容在不同的Block/Page里,因此需要Node Translation Table来关联这些Page,会增加Read的延迟。为此引入了IBSF,核心思想是保留一个Buffer,将这些Sector暂存在Buffer中,然后将属于同一个Node的Sector放在一起,写入到相同Block/Page中,因此也可减少Node Translation Table的大小。
WOBF(Write-optimized B-tree layer),发挥BFTL和IBSF的优势,进一步减少缺点,在Buffer的时候将Sector排个序然后写入到Flash中去,然后再用Node Translation Table去关联这些Page,目的是减少IBSF中Buffer的使用量。
LA-Tree(Lazy Adaptive Tree):主要是为了减少Update Tree Node的开销问题,先将一部分Tree存放在Flash中划分的Buffer里,等Buffer满了再做Merge操作生成完整树存放起来。
-
Structure-Modified B-Trees:
u-Tree,目的是为了解决开头所说的Wandering Tree异地更新的Flash存储空间问题。巧妙的设计如下:
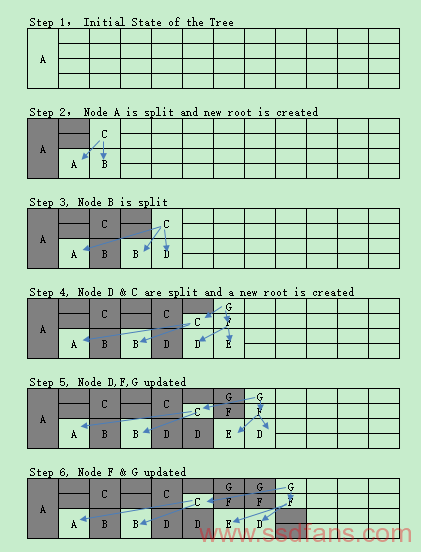
u*-Tree是u-Tree的加强版,根据树的状态,动态调整叶子节点的大小,然后指定Page里的Layout,最小化Tree所占的Page数目和尽可能延迟树的高度增长。
IPLtree核心在于固定划分为Data区域和Log区域,前者存放正常Node,后者存放已经更新的Node。类似LA-Tree的做法,当Log区域满了,就会执行两个区域的Merge操作,这样做的好处无非是延迟整个Node的更新操作。
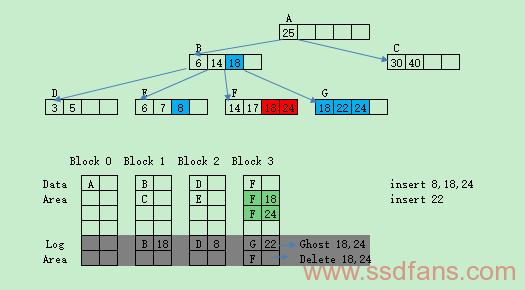
IPLtree的加强版是d-IPLtree,与IPLtree区别在于Log区域的大小不是固定的,原先绿色部分F18,F24在insert 8,18,24时候还在Log区域,而在insert 22时候被Merge到了data区域,如下图所示:
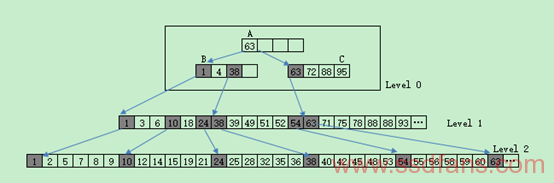
FD-tree核心思想是将Tree划分若干level,每个level存放在1个page里,当插入一个元素时候,先插入到Level 0(Root Node所在的level),如果Level 0满了,再执行Merge Level 0和Level 1操作,依次类推,这将预示着该树扇出很大,高度很小,如下图所示:
-
Hybrid B-Trees
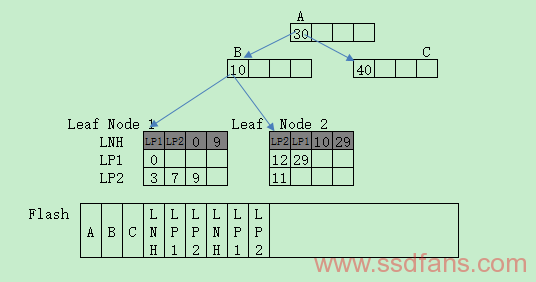
Hybrid B-Trees这里也就是个概念,比如MB-tree有两个概念,一个是BPB(Batch Process Buffer),另一个是LNHs(Leaf Node Headers),前者驻存在RAM中,缓存Flash操作用的,后者占用Flash空间,每个LNH占一个Page,用于顺序存放叶子节点的Key信息,紧接着的是LP(Leaf Page)。数据结构类似下图:
RBFTL(Reliable B-tree)类似于BFTL操作,所谓可靠,只是不知道咋想来将Index放入到Nor Flash中去,以防止掉电,这是一件多么让人揪心的做法,我们可以Replay或叫Rebuild的,具体将在Power off Recovery章节介绍。还有一种AS B-tree(Always Sequential B-tree),顾名思义是为了发挥顺序写的优势,思想是用一个Buffer缓存Node的更新,Buffer满了再将缓存的Node写到Flash中去,简单地用未来的时间整容。

