作者:李大虾
Cache Manager对于FTL来讲也是非常重要的一个组成部分,所以这里单独一节来叙述。Cache的好处是不言而喻的,首先它的频繁命中可以减少对Nand Flash的访问,并且对WL和如前所述对Hot/Cold Data有指导意义,从而提高了Nand Flash的寿命;其次由于缓存的所用介质的物理访问速度要比Nand Flash快很多,因此频繁命中也能提高IO性能。性能上的具体的表现是:(1)用于填充CPU对不同存储介质访问的差异,避免了每次都对相对低速的Nand操作;(2)优化数据顺序,有效更新数据到Flash中去,避免重复写入和脏数据的快速积累,从而快速产生GC操作影响性能;(3)整合小数据,缩短时间,同样也减少空洞脏数据产生;(4)缓存频繁访问的FTL管理数据,比如Mapping Table,减少Overhead。
对于Cache的概念,在Nand上也有存储系统金字塔的含义,可以用SRAM、DRAM、PCM或者Nand的SLC Mode等等,只要比Nand普通模式快速的设备都可以作为其Cache,这里不是介绍作为Cache的介质,也不会单独介绍SLC Mode作为Cache的使用,而是来叙述这些Cache的管理。在前面Hot/Cold那节已经介绍了Cache管理上的流行方法LRU相关算法,这里将不再大篇幅叙述,这里将介绍一些新奇的Cache Manager方法,当然不能排除是LRU的变种。根据Cache数据的对象,将被分为三种,一种是Read Cache用于存储Read操作对象的数据,另一种是Write Cache用于存储Write操作对象,还有一种是FTL Cache用于存储FTL Meta Data;正常情况下我们是把这些Cache分开处理的。如有讨论,请联系李大虾(mailto:lishizelibin@163.com)或关注微信公众号大虾谈(DaXiaTalking)。由于Nand的Write速度要比Read速度慢很多,这里先介绍一种写密集页保护算法(WIPPA)。
-
WIPPA(Write Intensive Page Preserving Algorithm)
首先要介绍一下FARS(Flash Aware Replacement Strategy),它用四个状态(Write State,Read State,Write Intensive State,Read Intensive State)区分非访问密集页,使访问密集页具有更高的优先级存于Cache。设置一个Ghost List用于存放最近被替换的页索引,目的是用很少的空间来跟踪更多的页状态,也使得密集页的判别更准确。这种方法有个缺点是在3次Read之后,一个Write Intensive(WI)State的页必须经过Read State才可以变成了一个Read Intensive(RI)State页。因此在Cache管理中增加一个Intensive Flag(IF)来判断是否让WI的页在2次Read之后就变成RI。根据下面的状态转换图,请求依次如下Write 3,1,2,1,Read 1,3,1,可以得到Sector 1的状态分别是W->WI->W->RI:
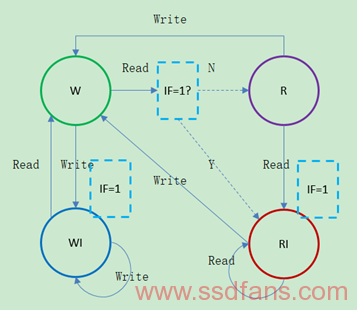
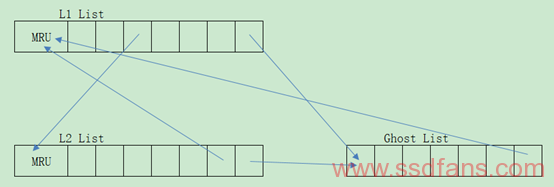
上述状态变化用三个LRU List表示,分别是L1 List(用于存放WI和RI页,并且从Ghost List里面抓取相关页),L2 List(用于存放W和R页)和Ghost List。整个过程如下图所示,当L1转换成L2的时候IF设置成”0″,L2转换成L1时候IF设置成”1″,某个页该存放在哪个List中请根据上图判断。当Cache满的时候就按照R in L2 -> RI in L1 -> W in L2 -> WI in L1优先级顺序置换到Ghost List中,注意Ghost List只存放Index,在查找某个页是否在Cache中需要遍历L1和L2,因此可以采用Hash方法映射页:
-
CLC(Cold and Largest Cluster Policy)
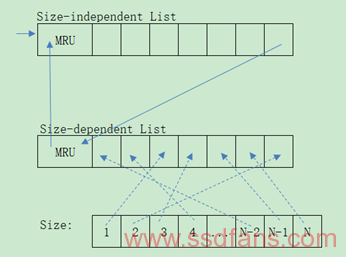
CLC的核心思想是使用块作为单位进行缓存,将含有最冷最大的页簇(Page Cluster)优先置换出缓存。它维护两个链表,一个是LRU的Size-independent List,另一个是按照块大小的Size-dependent List。数据先进入前者链表,当该链表满了,LRU端的节点,再进入后者链表,因此可以认为后者链表里存放的是Cold Data,当需要置换的时候就从后者链表中取出最大的块来置换。前者可以认为是Hot Page Cluster,后者可以认为是Cold Page Cluster,由此可见Hot Data和Small Data将会长期占用Cache,如何正确衡量Hot Data将成为关键,可以参见前面的Hot/Cold Data章节。下面针对CLC来说一说Corner Case,如果Hot Data很多,将会有一部分Hot Data存放于Size-dependent List,且有可能是Page Cluster最大的块,所以这部分Hot Data很可能被置换出去,而有可能把Page Cluster较小的Cold Data保留了下来。针对这种Case,我们也要将Size-dependent List设置成LRU List,在遍历Size-dependent List时候,考虑Page Cluster最大的块和Cold Data之间的距离,以确定置换哪个,如果距离很近则置换Page Cluster最大的块,否则置换最Cold 块。上述数据结构示意如下:
-
MaCACH
MaCACH是一种使用反馈控制自适应缓存感知页映射管理,在Hybrid Mapping系统里面将大块连续的缓存页直接写入到块映射区域将更具有效率,从而提高页映射区域的利用率(换句话说就是使得Page Mapping区域维护在一个很满的填充上,这样该区域可以很高概率找到属于同一个Block的Pages),也进一步减少GC的发生。MaCACH是利用PID(proportional-integral-derivative,比例-积分-微分)技术做到这一点的,当Page Mapping区域较少的时候,PID通过减少阈值控制其填充速度,而将数据填充到Block Mapping区域,相反Page Mapping区域空间很多的时候,PID通过增加阈值提高其填充速度。MaCACH跟前面所述的Cache系统一样,最大化给定Block的Flush Page数目,Flush时空上不经常访问的Cold Data,上述PID控制的阈值正是Flush到Block Mapping区域还是Page Mapping区域的参考值,注意这里不像有些区域设置,Block Mapping区域和Page Mapping区域的大小是固定的。整个过程类似如下:
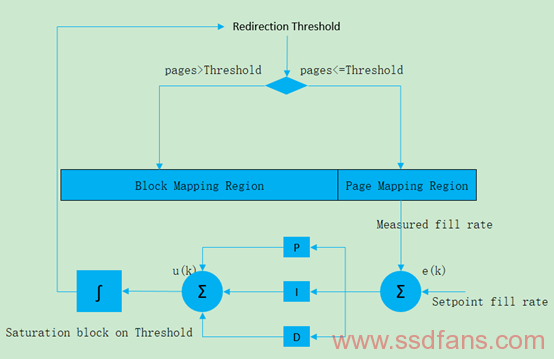
具体采用Ziegler-Nichols方法解决PID方程的过程将不再赘述,请参考论文MaCACH:An Adaptive Cache-Aware Hybrid FTL Mapping Scheme Using Feedback Control for Efficient Page-Mapped Space Management,以及文中提到的多目标优化方法PAES(Pareto Archived Evolution Strategy),为了完整性,下面还是将阈值计算式列出来,u(k)就是重定向后的新阈值(page数目):
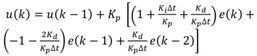
其中e(k)是理想中Page Mapping区域空闲大小和实际空闲大小的差值(page数目),式中Δt是I/O请求到达时间间隔,Kp/Ki/Kd是PID控制的收益值,下面是其计算公式,其中Ku是终极收益决定了性能,Tu是固定的振幅和周期。
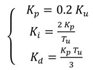
-
RFLRU(Random First LRU)
RFLRU采用写顺序检测机制,然后利用空间局部性缓存、预先随机写和不同写放大技术来区分随机写和顺序写,优先向Flash中Flush顺序有效的数据,不仅能提高写的性能,也能提高读的性能。这里使用区分写顺序的过程使用一种叫PWC(Pre-write Context)的对象,每个PWC对象包含重要的参数识别局部顺序性,根据经验往往小笔数据写入具有时间局部性特性,而大笔数据写入具有空间局部性特性,因此可以选择时间和空间参数当作PWC对象参数,并使用平衡树和PWC队列来管理它们。首先,它对比相邻Write Request地址并合并顺序的Write Request;其次,如果这个Write Request不在这个PWC对象则新建一个;其局部性的类型根据Write Request大小是否大于预设阈值来判断,大于则放到Sequential Buffer,小于则放到Random Buffer,如果含有确定顺序的Write Request序列也可以放入到Sequential Buffer中。前面说了管理用的平衡树,主要用来管理PWC对象数据结构,便于插入查找和删除,而PWC队列是两个LRU链表,分为包含顺序特征的Active队列和不包含顺序特征的Passive队列,如果Active队列满了就按照LRU规则转移到Passive队列中去,而新Write Request查找到PWC在Passive队列则将其转移到Active队列,这样Active队列相对来说是顺序度很大的,这种有点类似上述CLC方法。
这里特别想说明其预先随机写技术,它不像以前提到的将顺序的数据先写入到Flash中去的观点,而是先将Random Buffer的数据具有高优先级写到Flash的Log区域,而Sequential Buffer写入到Flash Data区域的条件是Block满了或者是过期数据。这种方法的目的是阻止局部连续导致的Partial Merge的发生,比如Write Request 27,0,1,33,44,再来2,3,30,40,49,4,21,69,5,6两组,其过程如下图所示:

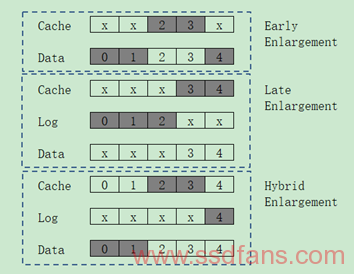
所谓不同写放大,其实是包含提前放大、延迟放大和混合放大三种:提前放大是把Sequential Buffer里Block的中间部分和Flash里面Data Block的另一部分组合成一个新的Block,这是因为这是一个含有部分数据的Sequential Buffer,而Buffer的资源是有限的,并阻止了GC占用部分Write Block数据;延迟放大则是将Sequential Buffer里Block的后半部分和Flash里面Log Block的另一部分组合成新的Block,减少了Log Block GC操作的有效Pages数目;混合放大是Merge的数据分布在Cache、Log Block和Data Block中,比如Log Block提供Cache里Block的后半部,而Data Block提供其前半部。三种不同写放大示意如下:
-
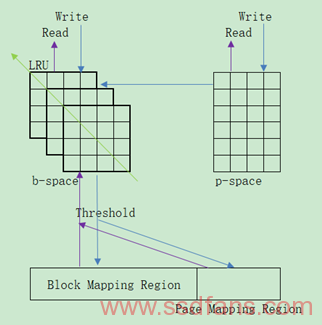
C-lash Cache System
C-lash是建立在FTL偏上的缓存系统,将Cache划分为两个部分,一个是p-space更倾向于Page Buffer(来自于不同Block的Page),另一个是b-space更倾向于Block Buffer(包含多个Block,每个Block包含其完整的Page Buffer),前面曾提到过将Buffer划分为Page和Block关系。其中Page可以从p-space置换到b-space,而b-space的Block置换到Flash中去,因此系统经常Flush Block中的一组Pages到Flash中去。p-space和b-space可以包含Valid或者Free的Pages或Blocks。当一个读请求到达,首先查找p-space和b-space,如果没有找到再经过FTL去查找Flash。值得注意的是读操作不会带来Cache的改变。当一个写操作到达时候,先写到Cache中,具体写到p-space还是b-space中去则根据下列条件:如果Cache中不存在,则写到p-space的Free Pages中去;如果p-space空间不足,则将最大连续Pages的组Flush到b-space中去;如果b-space从p-space获得数据时候发现空间不足,则从b-space中Flush一个Block到Flash中去,Block的选择条件则根据LRU规则;当然如果来到的Write Request达到一个或多个Blocks时候,可直接写入到b-space,如果b-space空间不足亦会执行相同的Flush操作。Flush操作则会根据阈值进一步筛选是写入Block Mapping区域还是Page Mapping区域。整个过程示意如下: