作者:李大虾
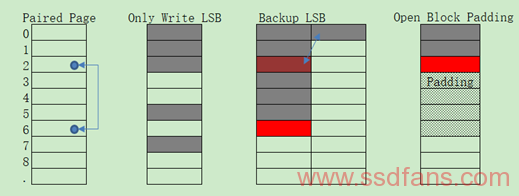
本节主要说明Power off Recovery(POR)的由来和对它的一点点见解。POR基本上可以分为硬件限制导致的POR和软件流程所需要的POR。硬件限制导致的POR,我们暂时叫做HPOR,软件流程所需的POR,我们也暂时叫做SPOR。根据经验来看,HPOR普遍的是突然掉电带来ECC错误,一方面是硬件电路设计上在Nand Power上增加一定容量的电容,或者是检查到电压不足拉低WP,尽量让当前写操作完成,更甚增加类似Nor设备代替RAM来存储需要掉电保护的数据;另一方面是类似MLC Nand带来的Paired Page在掉电中的问题,需要软件上备份加恢复的方式处理,处理方式包括ECC错误Page的丢弃以及最后掉电的Block中好数据的搬移等。如下图示意,在Program操作被恶意中断之后,损坏的不仅仅是当前Program的High Page(MSB),还有可能是它的Paired Low Page(LSB)。目前普遍可能解决方法是(1)只写LSB或MSB;(2)写MSB时候备份LSB,达到Open Block(Block未写满)最小填充条件,之前备份写入的Page就可以变脏回收;(3)一次性写到Open Block所要求的填充条件,有的甚至用Block作为写单位,写满的Block叫做Close Block。后面将通过自适应的Paired Page预备份方法具体介绍这种POR。
SPOR基本上是FTL使用RAM当作Cache来管理的Side Effect。之所以用Cache进行局部缓存的原因是为了加快访问速度,比如缓存频繁更新的Mapping Table等,所以在突然掉电的情况下,Cache里的数据就会丢失,因此就需要软件机制来恢复这种丢失,也属于FTL设计中的一个环节。我称之该过程为”破闭环”。一般情况下,是带FTL格式的用户数据已经写入到Nand中,而此时Mapping Table还可能在RAM中,为了避免下次恢复时间过长,一般会设定一定数目的Block数据可以恢复程序扫描,同时这些将要被扫描的Block尽量不要发生GC操作,否则很可能当做下一个要写入的块,这样就形成了一个闭环,由于恢复过程跟写入时间前后有关,因此很容易引入问题。这时候就有另一个设计叫Commit过程,目的是避免闭环产生,将RAM中的数据写入到Nand中去。Commit条件除了闭环条件以外,还有缓存空间不足导致的置换,设备或文件关闭或者用户强制执行Flush操作带来的动作。实际应用中,Commit FTL Meta Data和User Data Flush是分开的,而Commit动作只针对FTL Meta Data,当然设计是灵活的,也不是一定不可以Flush User Data。以上破闭环过程示意如下,下图说复杂不复杂,说简单也不简单,经验来讲SPOR的过程越纯粹简单带来的问题越少,而往往越简单越有效的流程越难设计。但我觉得”破闭环”是一个值得遵循的方法,这样就不会出错,否则人民群众会仇恨你,你的朋友嘲笑你,你的家人也会唾弃你。
下面将具体针对两种POR方法研究,希望能带来借鉴意义。一种是针对HPOR的MLC Paired Page预备份方法,另一种是针对SPOR的突然掉电恢复设计。虽然MLC的这种Paired Page设计属于早期产品,慢慢地被更高制程,且类似于TLC的pSLC方式所代替,但是历史也可以明智。SPOR的突然掉电设计却具有普适性,其中考虑的运行过程和重启恢复过程时间效率因素,以及RAM中数据的主动和被动同步处理策略,被动同步可能由于RAM的空间不足导致,而主动同步是在一定规则之下,比如配置一定Block写完后进行一次同步。
MLC Paired Page Backup方式带来的一个重要问题就是写延迟,一方面要考虑Write Request中的Pages是否包含了Paired Page,如果包含则LSB Page就无须再Backup;另一方面则考虑LSB Page是否已经变为Invalid,如果变为Invalid则也无须再Backup。下面的预备份方法就是从降低Backup Overhead和写延迟方面解决问题,根据数据大小包括三个技术:
-
Interleaving Prebackup:这是利用提供并行多通道访问的Nand条件下的技术,如果空闲通道可以提供2倍的当前Write Request数据量大小,那么此时就可以Write Request和Backup LSB同时进行,这样增加通道的使用率使得Backup操作没有Overhead,也就是说Write Latency = 0。然后只要MSB Page写入之后就立马将Backup Block中该MSB对应的LSB Page置成Invalid。如下图所示:
-
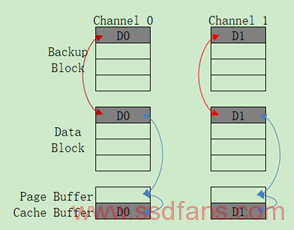
Copyback Prebackup:如果没有上述的空闲通道,且数据量介于所有通道的1/2数据量和所有通道满载之间(包括满载)。Nand Flash的Copyback操作将紧接着这次Write Request之后,将LSB Page拷贝到Backup Block中去,这种方法的Write Latency = LSB Copyback Time。其中的过程如下图所示:
-
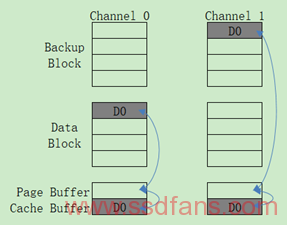
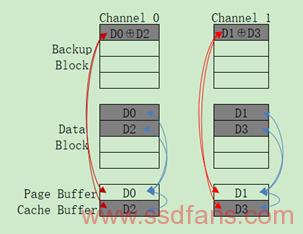
Parity Page Prebackup:如果写入数据量大于通道满载时候的数据量。这时候上面两种方式都不可行了,使用第(1)种方式没有多余的通道,使用第(2)种方式是因为这笔Write Request还没写完,强制使用也会导致写延迟。因此有了第(3)种方式Parity Page Prebackup,也就是每两个LSB Page产生一个Parity Data Page进行Backup。如下图所示,FTL的这笔Write Request包含D0、D1、D2、D3四个Page数据,首先写入D0和D1,紧接着写入D2和D3,这时候Cache Buffer里面是D2和D3,再把D0和D1读回到Page Buffer中,利用Nand Flash的XOR电路生成Parity Backup Page,这种方法的Write Latency = LSB Read + Write Time。其中的过程如下图所示:
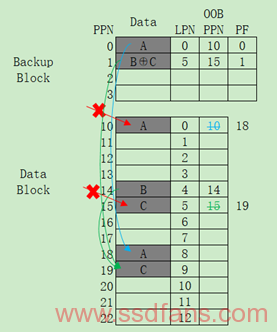
为了掉电导致数据出错并且降低Write Latency的方法介绍完了,接下来说一说该如何恢复?如下图所示,假设LSB A和C在掉电过程中导致损坏,那么查找Backup Block,找到A和C,其中C是是Parity Backup Page,理由是PF(Parity Flag)标志为1。然后找到A在Page 0,并将数据拷贝到新的Block,即Page 18的位置,更新Mapping Table;然后C通过读取Page 1和B所在的Page 14的数据进行XOR后写入到Page 19,更新Mapping Table。到此以例说明HPOR结束,如有讨论,请联系李大虾(mailto:lishizelibin@163.com)或关注微信公众号大虾谈(DaXiaTalking)。
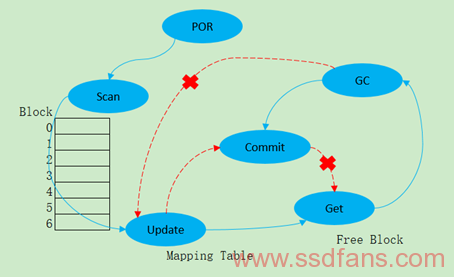
针对SPOR下面将先介绍一种叫确定性崩溃恢复(DCR)方案,它包含三种数据崩溃类型:阶段1叫正常崩溃,阶段2叫GC崩溃,阶段3叫WL崩溃。所谓正常崩溃就是在正常的Nand Driver和Nand Chip之间读写擦操作中掉电导致,在Commit点(也叫检查点)之后去读每个Block的每个Page,从Spare区或者定义的Header上找到对应的逻辑映射的Cluster/Block/Page/Sector(具体是哪一种根据Mapping定义) Number,如果某个Block没有有效数据该块可以置为空闲块,如果某个Block读到ECC Error,则将前面的数据搬移到好的块中,该块同样置为空闲块,然后就根据Mapping表的定义规则更新Mapping表。GC崩溃发生在GC操作中,一种简单暴力避免GC操作恢复的方法是每笔GC结束就进行Commit,另一种则是保留一定Block给GC掉电恢复用,Block用完再Commit,因此掉电恢复过程中也要重演GC操作,恢复方法和正常崩溃一样。下面有一个问题,在掉电恢复过程中再次掉电会发生什么样的故事呢?一般故事都是这样发展,先不要去动这次恢复的Block,当恢复完成后再去真正置为空闲块的信息写入到Flash中去。最后WL崩溃基本上和GC崩溃处理方法是一样的,在GC/WL章节也曾叙述过二者合一的做法。综上所述,如果能对掉电点做到确定性,掉电恢复的设计便能做到正确性。
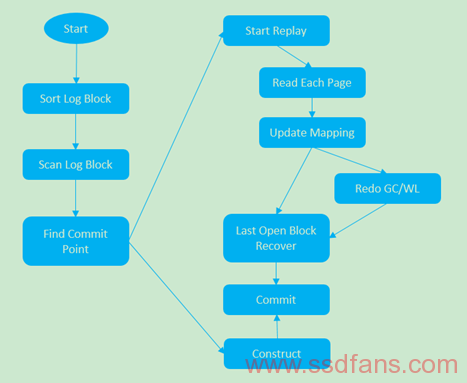
基本上SPOR的方法都是如此类似,接下来请准备记知识点,流程总结如下:首先我们定义将要做POR的Block叫做Log Block,根据Erase Sequence或者叫Timestamp来对这些Log Block按时间排序,然后通过Scan找到最后一个Commit Point或者叫Check Point,如果没有找到则认为这是一个空Flash,或者还没来得及Commit就掉电了,前者需要Construct一个空的Commit Point,后者则Construct这些没来得及做Commit Point的数据,Construct结束后直接Commit即可;如果找到Commit Point则对Commit Point之后的Block/Page做Replay(这个词来源于UBIFS,重演的意思,很是贴切)动作,也就是读取每个Page然后更新Mapping Table,如果需要Redo GC/WL也可以做,做法同前面正常Block Replay,最后一步是Last Open Block检查,这点很重要,因为这个Block很可能是掉电的点,变得很不稳定,也可能某个Page正在写时掉电,这次读检查很可能会发生ECC Error,因此需要将它前面有效的数据搬离到其他Good Block中去,避免多次POR后,这个ECC Error Page前面的Page也变成了ECC Error Page,那是很糟糕的,千万不要这样。