作者:李大虾
本节主要叙述GC和WL的特性和方法。GC(Garbage Collection)垃圾回收的产生主要由于Nand Flash的Block具有”Erase-Before-Write”特性,对于文件系统的Block更新实际上采用异地更新的做法,也就是说文件系统的Block第一次写在Nand物理Block 0的位置,下一次更新就有可能写在Nand物理Block 1的位置,原来写入的数据就变成脏数据。因此GC的主要目的是Nand Flash空间使用到一定程度之后进行脏数据空间回收的过程,同时要将有效数据搬移到新的位置。因此我们期望GC的候选Block能够全部是脏数据,这样回收起来只要Erase即可,再妥协一下就是包含极少量的有效数据,这样就减少了候选Block和有效数据的选择计算及有效数据搬移而带来的性能下降。
WL(Wear-Leveling)磨损均衡的目的主要是防止Nand某些物理Block被频繁擦写而导致数据保持力很差,进而引发大量Bitflips,甚至是ECC Error或Bad Block的产生,数据因此出现错误而不可以再使用,这将是灾难性的。WL的出现正好解决这类问题,它能使所有的Block擦写处于同一水平,寿命均衡发展,用大家好才是真的好的理念保证数据安全性。WL有两种类型:动态WL和静态WL。简单来说动态WL每次挑选擦写次数最少的Block使用,而静态WL是把长期没有修改的Cold Data从擦写次数较少的Block中搬移出来放到擦写次数较多的Block中去,那么擦写次数较少的Block将被重新使用。一般动态WL发生在Write Request时候,而静态WL发生在空闲阶段定期检查触发条件执行,且具有全局Block的WL效果。对于其他文献来说,还有一种叫全局WL的概念,主要用在多Nand Chip的产品中,如果其中一个Chip磨损较快,则使用另外的Chip进行磨损均衡,磨损很快的Chip将被暂时Lock住,以避免再次频繁操作导致数据损坏错误,一直到所有的Chip达到磨损均衡为止。
根据经验,GC的考量因素有:(1)候选Block的有效选择条件,一般考虑上一章节说的Hot/Cold Data因素,上述的WL因素,以及Block中所包含的有效数据数目因素等;(2)GC发生的时机问题,是后台进程在空闲时间的主动GC,还是Write Request发生时因Nand Flash的直接可写空间不足时的被动GC,再或者将被动GC的整个数据量划分为多个细粒度子数据分布到未来的写操作中执行,以避免某次Write Request时间过长;(3)目标Block的选择条件,同样需要考虑WL因素,这样可以将GC和WL当作一个整体来执行,主动GC对应静态WL,被动GC对应动态WL,浑然一体。GC的效率计算如下:GC效率=GC产生空Page数目/(GC搬移Page数目 *(写时间+读时间)+ GC擦除Block数目 * 擦除时间)。可见GC跟有效数据大小以及Block擦除时间有关,随着SLC、MLC、TLC以及3D Nand的发展,Block Size在追歼增大,GC Latency也随之增加。
说到GC/WL,不得不顺带说一下WA(Write Amplification)写放大和OP(Over-provisioning)预留空间。WA的定义是实际写入到Flash中的数据除以被Host写入的数据。也就是说实际上写入的数据要大于Host所给的数据,原因是在写入Host数据的同时还要写入前面所述的Mapping Data,还有FTL管理数据,GC/WL搬移数据等,是影响性能的一个重要参数。而OP的定义是FTL预留不可给Host使用的空间,这些空间可用于GC/WL使用,以及FTL管理数据存放和坏块管理等。使用OP的好处是,OP越大WA越小,GC需要搬移的数据就越小,有助于性能的提升,但这是一个Trade-off的过程,毕竟用户也想使用更多Nand空间。对于帮助GC/WL性能的手段还有Trim的使用、Secure Erase、Hot/Cold Data分离、利用Cache增加顺序写入减少随机写入等,同时也需要对Bitflips严重的块格外关注,必要时候需要搬离这样的Block,该过程也被叫做Scrub。有兴趣的可以查找资料加深理解,如有讨论,请联系李大虾(mailto:lishizelibin@163.com)或关注微信公众号大虾谈(DaXiaTalking)。
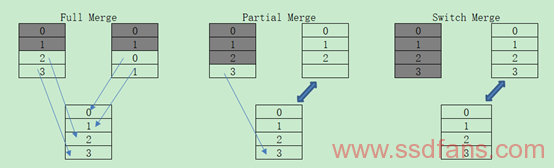
曾经被人研究过的方法有:(1)通过识别过去负载特征来预测未来负载特征的方法,通过Block Age、Utilization、Erase Count、Invalidation Period等特征控制多个候选Block;(2)通过前面所述的识别Hot/Cold/Warm Data的方法,使得GC的效率大大增加;(3)利用Free-Page补给机制,让GC来的更迟一些吧,类似的还有研究者的LazyRTGC,尽可能的推迟GC的发生,将在下面具体介绍这种方法;(4)通过执行Partial GC的方法,代表性的是GFTL和RFTL(Distributed Partial GC Policy),定期的执行Partial GC以挖掘出可用的Block。除此之外还有等等方法,下面篇幅将代表性描述GC/WL的手段。在介绍GC/WL手段之前,先介绍一些GC Merge的三种经典概念:Full Merge,Partial Merge和Switch Merge。如下图所示,明理人都知道Switch Merge的效率最高。
-
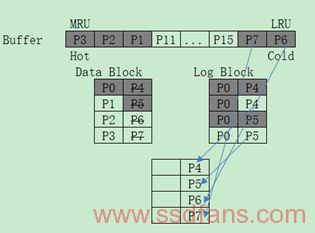
BAGC(Buffer-Aware GC)
这种GC的思想是结合当前的Buffer考虑,该Buffer包含Read Buffer和Write Buffer。跟一般GC步骤一样分为候选块的选择和Block Merge,它的候选块选择除了考虑前面所述的有效数据大小和WL水平,还把Merge过程中的代价作为候选块选择的考量,如果候选块数据在Buffer中更新,并且属于Buffer中的Cold Data,也就是即将在Buffer中被换出的部分,只要上述条件都优秀,便可以选择这样的块作为候选块,然后直接用Buffer中的数据进行Merge操作。示意如下:
-
SAGC(Swap-Aware GC)
基本操作方法是:将用一个区域存放Swap的Pages,在GC过程中,先等待不做任何操作,在这个时间内选择一些最少使用的Block作为候选块,通过从这些候选块中读出Valid Pages写到Free Block的方式估计Valid Pages的换出时间(SOT),将这些Valid Page按照SOT排序,首先拷贝最近最少被换出的Valid Pages做GC,而那些将来可能被换出的Valid Page则暂时不动。这个过程利用最少使用的块作为候选块的贪心策略,而不考虑WL水平和局部性原理差的块;利用公式(a*(1-u)/2u)预估所有Block的成本效能,a是最后一个使该Block某个数据Invalid的时间到当前时间的间隔,u是该Block的包含数据百分比。Free Block则参考erase count(即Block Age),始终选择最少erase的块。
-
LINK-GC
LINK-GC用很少的管理Overhead管理着一个GC候选块链表,根据排序或快速差算法找到需要GC的候选块,与此同时管理着抢占状态,抢占可以中止正在进行的GC,进行一半GC的Block将返回到候选块链表,以致下一次继续进行GC。整体设计包含三大数据结构:PMT(Page Mapping Table)、BMT(Block Management Table)以及GCT(Garbage Collection Table),如下图所示:
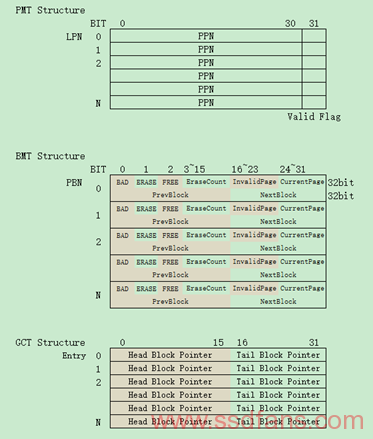
所谓Link的由来便是上图中的Pointer,首先BMT中的PrevBlock和NextBlock是为了构建PBN的双向链表,具有相同Valid Pages数目的放在一个链表中,而链表的Head和Tail指针放在GCT中。这样的数据结构便构建起了基于Link的GC方案。而它的行为却只包含两个子任务:单个Block GC和Link-based管理候选块。
-
单个Block GC
与普通GC不同,不是选择多个GC候选块,而是只选择一个Block作为GC候选Block,也是将Valid Data写入到目标Free Block中去,但是目标Block并未写满,而是留作下一次GC操作去用。上图BMT中CurrentPage指示的正是这个目标Block下一个要写的Page。这就是GC操作可以被抢占的关键组成部分。
-
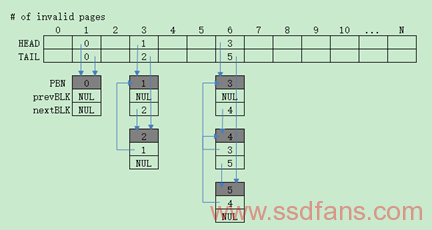
Link-based管理候选块
这里主要讲的是Link-GC算法,参考上述的GCT数据结构,GCT的ENTRY个数和Block内Page数目有关,Entry 0表示有0个Invalid Pages,Entry N表示有N个Invalid Pages,因此我们选择最大的Entry作为GC的候选Block。另外再结合BMT的prevBLK和nextBLK将具有相同Invalid Pages的Block双向链表链接起来,形成有效的查找功能。
-
-
Lazy-RTGC
Lazy-RTGC,全称是Lazy Real-Time GC,通过考量最差和平均系统响应时间来完成GC操作,然后尽可能延时调用GC任务,GC任务会非周期执行部分GC操作直到所有操作完成。部分GC的Valid Pages数目定义为Erase时间/(Read时间+Program时间)取上整。但是在Read请求期间是不会触发GC任务的,因为它是不会带来空间消耗。那么什么时候调度部分GC操作呢?第一步,判断GC任务是否为空,如果不为空则执行此GC任务的局部GC操作,执行完局部GC就退出GC任务;第二步判断Free Pages数目是否小于预设阈值,如果是则获取将要GC的Block,并产生一个新的GC任务,并做新GC任务的局部GC操作,执行完操作就会退出该任务。为了调高效率,这些GC任务也会在系统空闲状态下执行。下图将演示Lazy-RTGC的过程,假设每次部分GC的Valid Pages数目为2,在Tw1写入后达到GC阈值条件,Tr2是读操作不会执行GC任务,在Tw3后第一次插入GC任务,只是部分GC,将拷贝2个Page,依次类推直到G3出现Erase掉GC候选块就算整个GC任务的完成。
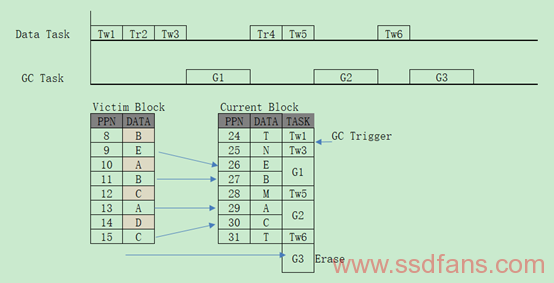
-
Reinforcement Learning-Assisted GC
随着人工智能的火热,感觉不介绍一点人工智能的东西都跟不上时代的步伐。AlphaGo正是用强化学习(Reinforcement Learning)战胜了世界围棋冠军李世石。Reinforcement Learning-Assisted GC是一个较新的观点,融合了人工智能的强化学习技术来解决Nand Flash的GC问题。强化学习主要用来挖掘空闲时间,在变化的空闲时间里分配合适的GC操作数目。之所以用强化学习,是因为强化学习已经广泛用于数据中心的资源分配问题,因此有人将它应用在DRAM的自我优化程序中、接近最优的电源管理策略中、以及背景信息预取等。所谓强化学习是指智能系统从环境到行为的映射学习,以使奖励(强化)信号函数值最大,强化信号对产生动作的好坏作出一种评价,通过这种评价不断自我学习和强大。从前面介绍知道,极大的利用空闲时间进行GC具有非常好的性能,既充分利用了系统资源,也极大减少了Write时候进行GC带来的性能问题。但有一个问题是空闲的周期长度是怎么样的却很难预测,也很难给一个合适的GC操作数量,因此通过强化学习来在线学习存储访问行为来动态调整GC操作。
强化学习包含四个要素:环境(Environment)、奖赏(Reward)、动作(Action)和状态(State)。强化学习要解决的问题是,针对一个具体问题得到一个最优策略,使得该策略下奖赏最大,这里的策略就是一系列动作。在这里动作被定义为部分GC操作,例如2个Page拷贝或者Erase操作,策略是选择一个极可能的部分GC操作执行,环境有两个状态,分别是活动(Active)状态和空闲(Idle)状态。在当前状态,Agent尽可能获得最大的奖赏,比如这个动作可以减少Long-Tail Latency。执行一个动作之后,环境就进入了一个新的状态。因此可以根据当前策略获得一个建议的动作,再根据奖赏更新策略获得新的建议动作。奖赏定义通过响应时间来确定,响应时间越大奖赏可能变成惩罚,响应时间越小,奖赏越大,如下图所示。具体相关奖赏算式还请移步论文:Reinforcement Learning-Assisted Garbage Collection to Mitigate Long-Tail Latency in SSD。
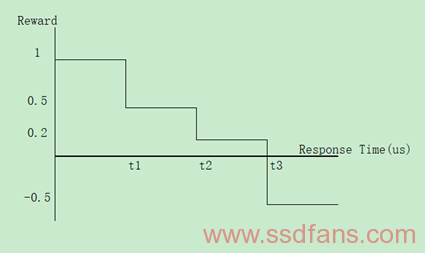
既然知道GC操作中对应于强化学习的四要素是什么了,接下来就看具体步骤了。
第一步是根据GC条件调度GC程序,首先设置最大部分GC操作数目限制,根据实验最大部分GC操作数目为2时效果最佳;其次设置两个GC条件阈值(当剩余空闲Block数目小于等于这个值时触发GC)Ta和Tb,其中Tb(比如100个Block)大于Ta(比如10个Block),这样就可以尽早的触发GC操作,但是为了避免增加Erase Count,当剩余空闲Block数目在Tb和Ta之间的时候,只选择Invalid Pages数目在Block中占60%以上的才进行GC;最后设置只要GC条件满足,Read操作也可以触发GC,但是不会影响Read操作,这是因为做了只在Read请求之后触发的设定。
第二步是计算动作,首先设定状态条件是先前的inter-request间隔(反映最近历史信息,如果间隔很大GC可以执行更多的动作)、当前的inter-request间隔和先前的动作,实验中可以设定先前的inter-request间隔有2档,当前的inter-request间隔有17档,先前的动作有2档,这样总共有2*17*2=68档,如下图所示是强化学习的一个数据结构叫Q-Table,具体见上述论文叙述的策略学习方式Q-Learning计算式;其次是根据上述三个条件计算出当前动作,使用的叫Ɛ-greedy强化学习技术,在一开始1000笔GC操作中使用大的Ɛ值(80%),然后再使用小的Ɛ值(1%)。如果当前的inter-request间隔为0,也就是说是连续的请求操作,就不要触发GC了。如果空闲Block将要被用完,就增加部分GC操作的数目,比如5~7个Valid Pages拷贝。

第三步是处理当前请求操作,并计算响应时间;处理完后执行部分GC操作,再用前面计算出的响应时间来计算Reward值,再依此更新策略学习Q-Learning。如此在线循环学习得到最优的策略。
说了这么多GC,根据本文的主题,接下来谈一谈WL。如前面所述,动态WL也就没什么好继续深谈了,一方面是由于动态WL的算法简单且没有Overhead,另一方面是因为一个Device大概75%的数据是静态的。现在举个例子说明WL的重要性,假设某个Nand的PE Cycle在3000次,用户每次写1个文件要更新10个Block,每小时要写30个文件,主控根据这些文件会频繁更新100个Block,那么没有WL的100个Block产生的寿命是:3000 * 100 / (10 * 30 *24) = 41.7天;如果静态WL到2000个Block,则产生的寿命大约是目前的20倍,约833.3天。即使WL导致Block内数据搬移带来的额外PE开销,也远大于没有WL的寿命。对于静态WL,需要解决的就是Overhead问题,并且能平衡WL水平以不至于达到Block寿命终点。如有讨论,还可以联系李大虾(mailto:lishizelibin@163.com)或关注微信公众号大虾谈(DaXiaTalking)。
下面先介绍一种类似Link-GC的WL方法,很多成熟的静态WL方法都与此类似。根据全局EC(Erase Count)最大值和最小值限制范围将Block划分为不同的Cluster,将Hot Data放到低EC值的Cluster中去,将Cold Data放到高EC值的Cluster中去,很多WL算法思想都是离不开Hot/Cold Data的划分,还有就是WL在搬移的过程中都借助GC动作。如下图所示,总共t个链表的滑动窗口,尽量将Block EC都维持在这个滑动窗口内。对于高级一点的程序t值的选取是自适应的,但是原则是随着EC均值的增加t值在逐渐减小,一种是线性减少(比如逐渐10%的递减),另一种是非线性减少(EC小的时候减小的慢,随着EC增大逐渐变快)。而m值反映的是存放Hot Data的Block数目水平,初始时设置为t值的50%,然后根据负载增加或减少。根据下图所示,可见如果EC增加集中在min_ec+t-1那头,那么m就相应减少;如果EC增加集中在min_ec那头,那么m就相应增加,变化的m将减少未来的数据搬移操作。除此之外,还可以加上将物理块映射到虚拟块上,通过判断虚拟块的访问状况来选择合适的物理块进行映射。
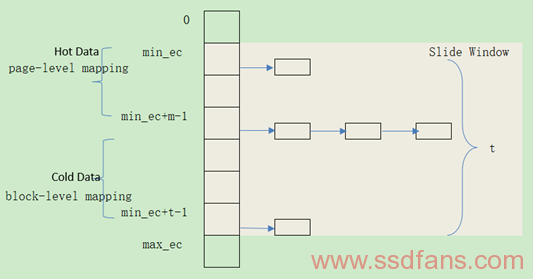
目前大多数静态WL算法都与上述做法类似,虽然有些手段不同,比如利用Hash来进行分布均匀化处理,但是概念上是差不多的。下面第一张图展示的是用户写入数据量(横轴)和均值EC(纵轴)之间的关系,说明某一段时间经过静态WL后,EC均值保持在某一水平上,均值上升速度与窗口大小有关,这是一张示意图,左边的窗口值很小,右边的窗口值很大;第二张展示的是用户写入数据量(横轴)和Wear Count(纵轴)关系图,不同颜色的线代表的是不同的WL窗口大小,有的前期长的快,有的后期长的快,实际上我们更希望后期(也就是较大PE Cycle时候)走势平缓一些,最右边两条线代表最大的窗口,最先平缓的是最小窗口值。因此综合均值EC和Wear Count走势选择一个合适的窗口值对一个静态WL算法还是蛮重要的。


