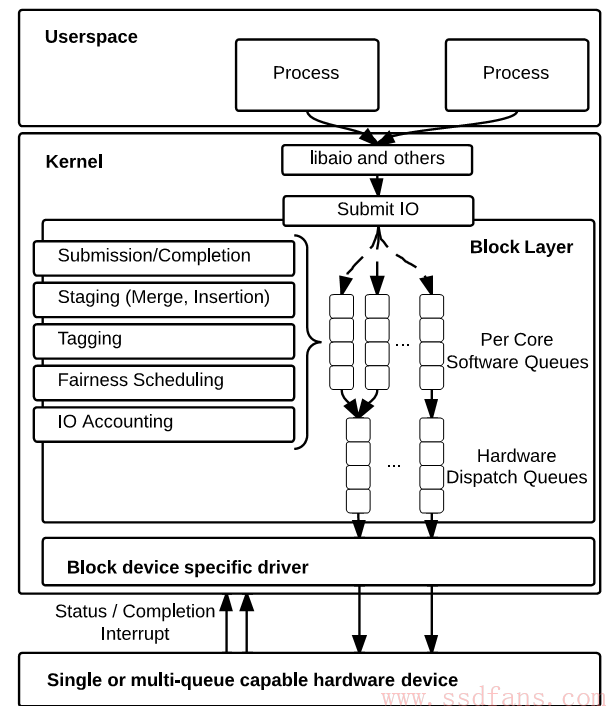
上回说到要想在NUMA架构提升块设备层性能,就得减少跨CPU的内存访问。当然你可以绑定CPU,唐杰在他之前SSD测试的文章中讲过这些技巧,比如SSD插在CPU 0上,那么就只通过CPU 0发命令,中断也只发到CPU 0上。但这些都是块设备层的公公婆婆、儿子儿媳干的活,不是它能够操心的事。从块设备层角度,开发了多队列机制来解决这个问题。
使命
我们做一件事,先要给出个目标。多队列设计的目标有如下几点:
- 公平。访问同一个SSD,所有的核都是公平的,不能歧视谁。
- 跟设备无关。不管是一个还是多个设备,接口都是一样的。
- 有个缓冲层。命令先发到缓冲层,让程序员搞搞排序算法,同时设备那边命令多了,后续命令也能在缓冲层排队休息一下。
新架构
如开头那张图,新架构是个双层队列:
- 上层是软件队列,每个核心一个,或者NUMA上每个CPU一个。再也大家不用抢一个队列了。这个队列的作用是给一堆IO命令排序。
- 下层是硬件队列,硬件驱动自己选择到底是多少个。这其实是个命令缓冲层,防止硬件那边承受不了。
其它的优化:
- 队列里的每个命令都有一个唯一的标签tag,这个tag还传给了驱动程序,当完成的时候驱动和块设备层就能靠这个tag来确定是哪个IO命令。
- 统计信息的优化,为软硬件队列都做了IO统计支持。这个是来计算带宽用的,系统的iostat接口就会用这些信息,很多工具比如IOZone会使用这个接口。
对驱动的新要求
- 注册块设备驱动的时候,要说明硬件队列个数和深度,这样内核会分配内存来放这些队列。
- 提供一个函数,把软件队列映射到硬件队列。
- 使用块设备提供的tag,别再自己重新生成了,浪费资源。
跑个实验看看
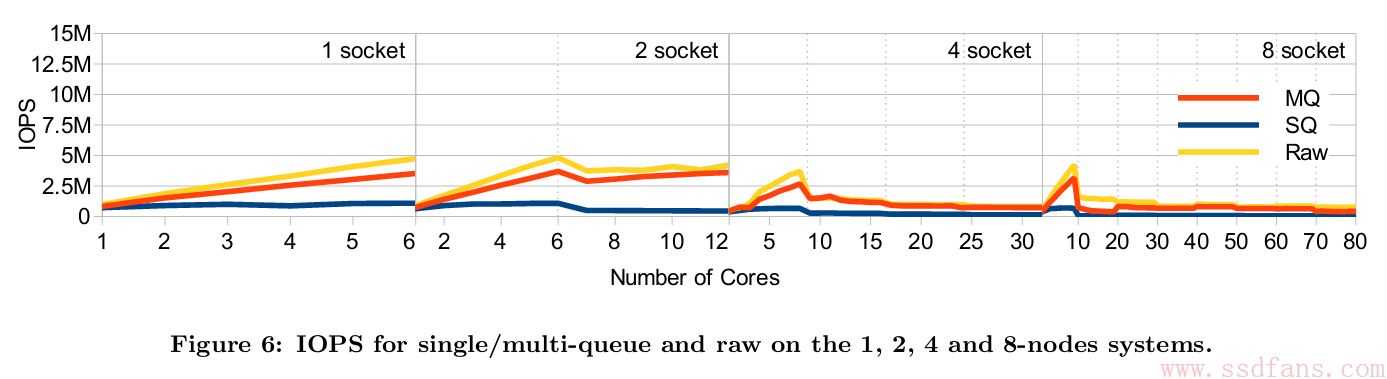
理论说了一堆,到底行不行?还是跑个测试看看吧。多队列,单队列,和跳过块设备层的Raw设备三者对比,毫无疑问,Raw设备肯定性能最好,因为是上层软件直接操作硬件,这个作为基准。测试方法就是不使用硬件,用一个软件设备NULL来模拟,NULL收到上层命令就立刻返回,这样就能脱离硬件影响,直接观察上层块设备性能。
如下图,1个CPU的时候,随着并发线程增加,单队列IOPS不超过1百万,而对多队列能到3.5百万。单队列的性能在多核和多CPU情况下扩展性很差,而多队列性能和基准Raw设备接近。
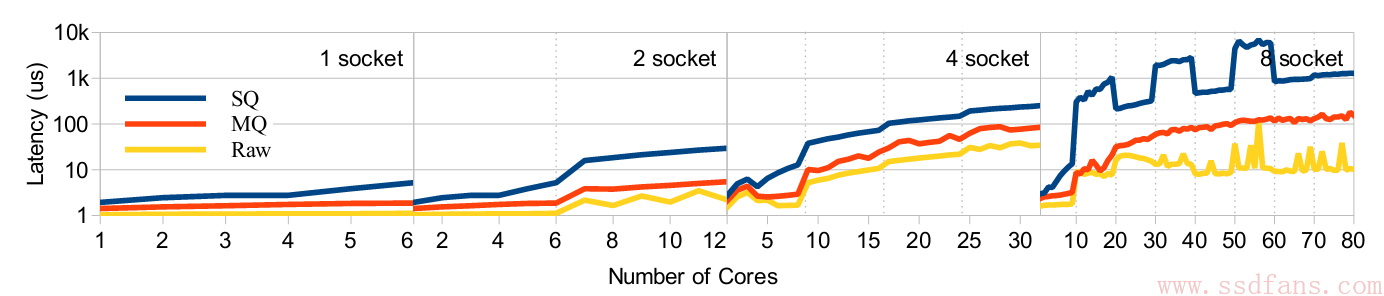
再来看看延迟。可以看出,单队列IO延迟随着并发线程增加,会从2us到8us,因为要访问其他核的Cache,而多队列一直都在2-3us之间。到多个CPU的时候,多队列也没办法避免跨CPU访问硬件队列,所以延迟会增加,但是2个CPU也在7us左右,8个CPU,80个线程时会到100us,而单队列竟然会到1ms,比SSD的读延迟还长了好几倍。
不过请记住这个实验结果,挺有用的:
- 单队列:单线程的时候,IO Linux软件层延迟在3us左右,多线程会达到8us。双CPU,多线程最高达40us。
- 多队列:单线程的时候,IO Linux软件层延迟在2us左右,多线程会达到3us。双CPU,多线程最高达8us。

