
上面这个可爱的小伙子名字叫Jens Axboe,他是丹麦哥本哈根大学计算机系没毕业的学生,他还有一个有名的同乡叫Linus,没想到老乡后来也成了他的领导。Jens今年39岁,16岁开始就接触Linux,后来也成了Linux开发者,现在是Linux Kernel大拿了,负责块设备层的维护。这个块设备层就是跟我们SSD关系最紧密的层级,联系了上层文件系统和下层设备驱动程序。他开发了不少有用的程序,比如Linux IO Scheduler里面的Deadline, CFQ Scheduler,还有著名的王牌测试工具FIO。
今天我们来聊的就是他参与的Linux块设备多队列机制。这个是专门为了SSD而开发的,因为以前的IO命令都是放到队列里面,但是1个设备只有1个队列,在机械硬盘时代绰绰有余。自从有了SSD之后,1个队列在多CPU环境中性能有局限,因为SSD只能连到1个CPU上,一个读写命令执行过程一般会分成几个阶段,如果调度到不同的CPU上执行,就得有跨CPU的数据访问,影响Cache的使用,同时数据传输要通过CPU之间的QPI总线,性能赶不上自己CPU的Cache或内存。
故事主要依托是Jens参与写的一篇论文《Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems》,那时候他还在Fusion-IO,如今跳槽去了Facebook,阿呆听说在硅谷Facebook给码农的薪水是最高的,当然阿呆还处于码畜的层级,正在奋斗成为一个码农,而Jens已经跻身码精英了。
块设备层架构
老是听人家讲块设备层,听起来牛逼哄哄的,那到底是个什么东东?其实挺简单的,一般我们用户读写数据都是通过文件的形式,文件的依托就是文件系统。而数据最终存储到磁盘等存储设备中,每个磁盘都有自己的驱动程序,磁盘的访问一般是按照逻辑地址LBA(Logical Block Address)来的。文件系统有各式各样,用户IO形式也各式各样,存储设备也有HDD,SSD,U盘,磁盘阵列等各式各样,所以块设备层就从石头里面蹦出来了:提供一个统一的接口,让用户程序能够不关心底层存储设备是什么,反正就读写呗。存储设备也不用关心上层应用是什么。
如下图,是Linux块设备层(Block Layer)架构。Linux程序分为用户态和内核态,用户态要读写操作,需要通过System Call接口调用内核函数,这个读写被转成了Block IO,简称BIO,里面包括了访问地址LBA,数据大小,内存地址等信息,还包括同步还是异步操作。同步就是发了,线程就什么都不干,一直等到IO结束才回去。异步是发完就完事儿了,留了个回调函数,IO操作完了块设备驱动程序去调用回调函数通知上层。
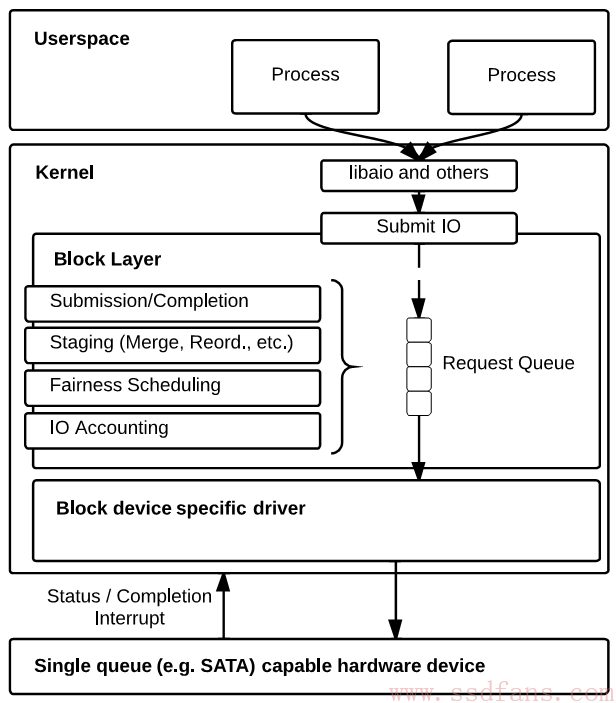
这个BIO发到块设备层之后,就进入了一个队列,叫Request Queue,排队等磁盘接活。不过排队的过程中,块设备层也没闲着,程序员为了显示自己牛逼,会开发各种算法来优化排队顺序。比如以前HDD磁头旋转寻道很慢,一般要几毫秒,所以算法会把连续的LBA排到一起,减少寻道次数。还有各种其它算法,针对不同应用场景。
NUMA架构
单队列看起来还行,但是当SSD和NUMA架构服务器凑在一起,单队列就有先天缺陷了。什么是NUMA?阿呆只知道祖玛。不过我们可以先来看看祖玛,前几关往往是这样的。
后来就变成了下面这样,明显,吃弹珠的大嘴多了一个。
NUMA也是类似的,我们一般的CPU架构叫UMA(Unified Memory Architecture),就是尽管有很多核,但是大家都访问同一块内存。而NUMA就不一样,多了个N(Non),NUMA架构其实很简单,就是买几个CPU,每个CPU配自己的内存,CPU之间通过QPI等高速总线连起来,访问别的CPU内存。如下图。
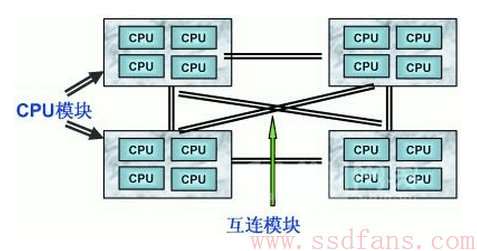
NUMA架构是当前服务器和超算领域通用的架构了,一般的服务器都是配两个CPU的,超级计算机就更多了。
块设备层在NUMA架构的缺陷
块设备层用在SSD上,假如是NUMA架构或者多核CPU,那存在如下缺点:
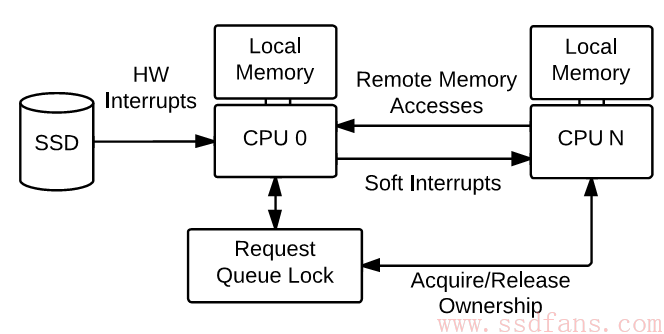
- 队列锁。不管是从队列取命令,还是往里放命令,或者重新排序,都是要上锁的。这样就会在几个线程竞争队列的时候发生等待。
- 硬件中断。SSD只能连到一个CPU上,IO命令都通过中断通知它。所以这个CPU处理中断,再通过软中断通知其他CPU去完成后续的任务,比如调用回调函数。根本不关心哪个CPU发起了这个IO。这样,为了完成1个IO,需要有两次中断,还有进程切换,同时原来CPU的Cache中相关数据也作废了,因为转给了别的CPU执行。
-
跨CPU访问内存。这个就要涉及到Cache的机制,现在的CPU都配有Cache,有的多核CPU每个核有自己的Cache,比如L1 Cache独享,L2 Cache大家共享。当然NUMA的话每个CPU必然从Cache到内存都是独享的。假如IO命令是一个核 A发下来的,完成由另一个核 B执行,那么B就要从A的Cache读命令队列的锁状态,那么这段Cache数据段就被标为”共享”:只能被读,不能被写。队列只有一个,锁也只有一个,如果很多核并发做IO,那么大家就不能修改锁的状态,性能受到影响。
理论说了一堆,还是来看看现实吧。如下图,socket指的是主板上CPU的槽位,几个socket就意味着NUMA架构的几个独立CPU。可见,CPU多的时候,IOPS反而下降了。因为在NUMA架构中,通过QPI总线去访问别的CPU Cache成本很高。
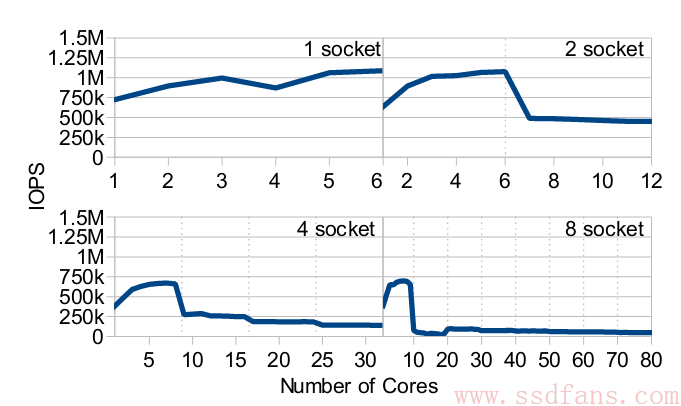
那该怎么办呢?我们常见的NUMA 服务器是两个CPU,从图中看IOPS只有500K,现在不少PCIe SSD IOPS都到1M了,明显,CPU成了bottleneck。下一篇阿呆就告诉你Linux内核的开发者想出的新方案。

