作者:斯托瑞吉
今天想跟大家一起看看Memory1的系统应用(all from memory1 whitepaper)。
从大菠萝推荐的典型系统应用上来看,2条Memory1和1条DRAM DIMM并列位于相同的Channel,DRAM DIMM在前,Memroy1在后,典型的容量配比为1:8。为什么要DRAM DIMM?后面有详细分析和介绍。当然容量比可以调整,基于整个性能需求计算,从throughput角度计算出来的total memory1的throughput最好不能低于前端的DRAM DIMM带宽。(DRAM DIMM性能数据有待收集)。 下图中server上有dual socket,3 DPC(DIMMs per channel),with 单条256G memory1,1个socket memory 1总容量为256G * 8=2T, Dual socket总容量可达4T。这里只统计了Memory1的容量,没包括DRAM DIMM的容量,按8:1算,是512G。留下一个问题,对应用软件而言整个系统memory的容量是4T还是4T+512G,应该是4T, 512G的DRAM是4T memory1的”cache”,后面详解。

再仔细分析下3 DPC, 就是上面图的红框,姑且这样称呼,DIMM0 DRAM—>Page 0, DIMM1 memory1 àpage1, DIMM2 memory1 àpage2。对上层的系统应用软件而言,page1/page2可见,操作Memory1和操作标准的DRAM没有任何区别,load/store data然后计算。对CPU的驱动而言,page0/page1/page2可见,为什么这样,page0是page1&page2的cache。试想如果软件直接对page0/page1/page2同等地位按不同地址range读写访问,不加处理,速度必然不一样,DRAM介质的page0极快,Flash介质的page1和page2极慢。按前面cache思路,Diablo设计软件去handle这个问题,简单说做一下数据分层,设计的目标是用page0绕过page1和page2 flash读写慢的特性,尤其是写,和处理Flash写入次数和寿命的问题。这里和SSD不太一样,读写速度和寿命的问题交给了device base的FTL或者host base的FTL之一来解决,Memory1是交给了Memory1 device base FTL和host base的驱动(这里面有一个page0和page1、page2的地址管理和数据换入换出策略)两者一起来解决,缺一不可,这是我个人的理解。
总结下来:系统软件对page1/page2的Memory1的地址空间发出以读写请求,host base的软件转换成从page1/page2到page0的cache操作,对page1/page2的读写请求后转变成对memory1的主控和FTL的请求直到完成,最后host驱动择机把cache刷到page1/page2。
Memory1用的是大容量低价的Flash介质做DRAM,从介质层面可以保证数据非易失,但从Diablo的白皮书上来看,系统不这么用。每次Server reboot时,在Memory1 DIMM的数据会被完全擦除掉,这就是纯把Memory1当DRAM内存条用。跟NVDIMM-N形态的内存条不太一样,其在掉电时把条子上DRAM的数据刷到条子上的Flash中去,reboot时BIOS负责重新从restore data from flash to DRAM,让系统和应用软件看上去掉电重启前后的数据上下文完全一致,就像没发生过掉电一样。这对某些应用省去了数据重建时间和其他软件开销和设计成本,也就是NVDIMM-N的核心技术和卖点。
这里要重申一点,Memory1当前的设计是把Flash当DRAM memory用,主攻替代部分DRAM DIMM市场。技术角度设计上可以在掉电时保存数据,只不过当前没有这样设计。看Diablo如下说:
“This also addresses a critical security concern for applications that rely on memory being non-persistent when a server is offline. In the future, as applications are modified by developers to utilize persistence, Memory1 products may provide persistent capabilities on the DIMMs.”
不过Memory1真要这么干(加入数据非易失特性),硬件上要加电容和控制器FW上的掉电处理(和NVDIMM-N一样)。个人观点:加入数据非易失特性,一种做法是做成NVDIMM-P(NVDIMM-F+NVDIMM-N的结合体),控制器DRAM和Flash都集成到一根条子上, DRAM和Flash对系统全部可见,跟当前的NVDIMM-F不一样了(系统只看见Flash,条子上也没集成DRAM),其配合的上层驱动和软件对待数据分层设计也会大改。另一种做法是保持Memory1 NVDIMM-F的特性不变,掉电时要处理的是DIMM0上的Page0如何刷到Page1和Page2中去,以及正在写入page1和page2的数据遭遇掉电还能继续完成成功写入。电容和系统备电支持的对象是DIMM0/DIMM1/DIMM2三个Slots。个人认为第二种作为更靠谱,对Memory1的NVDIMM-F和系统软件和系统应用场景都做了向前保留,而不会像第一种一样会大变。NVDIMM-F才是其核心的商业定位,卖点和目标。任何新加功能都是有代价的:成本和复杂度,新增功能是否会增加商业利益。这样分析下来Memory1当下不做掉电数据保存是有道理的,我大菠萝就是要用大容量Flash取代部分特定应用场合DRAM的创新者,纯NVDIMM-F特性,简单直接特点突出,能卖钱,over。各位读者关于此点有新的想法或更正,请交流。
再来看看读写数据流在Memory1上的流动,白皮书中的原文如下,大家可自行阅读。CPU/host发起写,都会首先写到Page0(DRAM)的地址空间,做wirte或read-modify-write,当page0中特定的region数据变成”dirty”数据并且不再写,数据会被从page0 DRAM中搬到page1或page2的memory1中的flash中。以region为单位来标记数据的clean或dirty,似乎region大小以Flash的并行virtual block(n parallel的物理blocks)大小合适,满足写入到flash的后端速度和寿命管理,减少memory1 FTL设计的复杂度,同时对page0而言又不至于太大(几十M大小),当然这只是个人猜想。
对于CPU/host读,下层处理逻辑也是首先从page1/page2中搬到page0的DRAM中,然后送给CPU/host。
一张图high level解释下读写数据流:
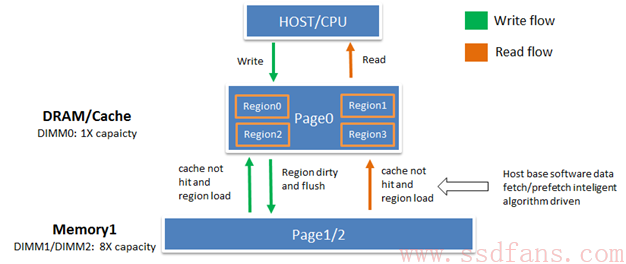
大菠萝host驱动(或软件)有这么一段话:In most cases, intelligent Memory1 algorithms will proactively move data (pre-fetch) into DRAM, before the data is requested by the application,再智能的算法也不能做到100% cache hit,吹吹牛也无妨。
根据描述,所以这里有一个恶劣case,就是如果host/cpu发random读写pattern,必然导致momory1和DRAM cache频繁的数据换入换出。当然如果host驱动能优化random pattern为seq pattern,改小size读写合并为大size的读写,对于整体性能有极大帮助的,我相信Diablo的驱动软件是加入此部分的。
“To achieve the necessary application performance levels, several specially designed Diablo Technologies algorithms manage access to all memory in the server, including both the DRAM and the Memory1 DIMMs. The software leverages the performance and endurance advantages of DRAM and the capacity advantages provided by Memory1. Incoming data is written to DRAM and outgoing data is read from DRAM, enabling high performance and endurance. In most cases, intelligent Memory1 algorithms will proactively move data (pre-fetch) into DRAM, before the data is requested by the application.
All memory writes by the application are first written to DRAM and then asynchronously moved to the Memory1 DIMMs. While an application is continuously writing to the same region of memory, that data will remain in DRAM. The data will only be moved to the Memory1 DIMMs when the writing of data to that specific memory region stops and the pages become ‘old’ or ‘dirty’. Therefore, if pages are modified frequently and indefinitely, those pages may never be written to the Memory1 DIMMs, ensuring both optimal performance and endurance. Alternatively, any data continuously written randomly by the application to all pages in the memory map will flow through the DRAM to the Memory1 DIMMs to make room for new, incoming writes.”
最后我想说的是Memory1核心技术不只是这根Flash条子还有host base的驱动算法(软件)
后面谈谈Memory1的性能,未完待续….
参考:
Diablo白皮书

