前面我们罗里吧嗦讲了一大堆,想对你灌输的核心理念就是PCIe SSD太快了,IOPS太高了,传统的内核态驱动有太多缺陷,那到底该怎么办?很简单,内核态不行,就放到用户态来!
在用户态完成SSD的IO框架,这样,各种数据密集型的应用,比如NoSQL,数据库,分布式系统等都会从中受益。不过,已经有一家行业巨头这么干了,那就是巨无霸——Intel。Intel发布的SPDK就是在用户态完成NVMe SSD驱动,提供了一整套工具和库,但因为SPDK把所有NVMe驱动都放到用户态,所以只能有一个用户和应用使用它。
SPDK简介
SPDK全称Storage Performance Development Kit,高性能存储开发包,它把驱动程序尽可能都放到用户态,同时采用了轮询模式,这样消除了Kernel进程之间的切换和中断处理,用这种方法达到高性能。先来转载一段引用1翻译自Intel网站的介绍:

“SPDK超高的性能实际上来自于两项核心技术:第一个是用户态运行,第二个是轮询模式驱动。下面,让我们分析一下各自细节。
首先,将设备驱动代码运行在用户态,是和运行在”内核态”相对而言的。把设备驱动移出内核空间避免了内核上下文切换与中断处理,从而节省了大量的CPU负担,允许更多的指令周期用在实际处理数据存储的工作上。无论存储算法复杂还是简单,也无论进行去重(deduplication),加密(encryption),压缩(compression),还是简单的块读写,更少的指令周期浪费意味着更好的整体性能。
其次,传统的中断式IO处理模式,采用的是被动的派发式工作,有IO需要处理时就请求一个中断,CPU收到中断后才进行资源调度来处理IO。举一个出租车的例子做类比,传统磁盘设备的IO任务就像出租车乘客,CPU资源被调度用来处理IO中断就像出租车。当磁盘速度远慢于CPU时,CPU中断处理资源充沛,中断机制是能对这些IO任务应对自如的。这就好比是非高峰时段,出租车供大于求,路上总是有空车在扫马路,乘客随时都能叫到车。然而,在高峰时段,比如周五傍晚在闹市区叫车(不用滴滴或者专车),常常是看到一辆车溜溜的近前来,而后却发现后座已经有乘客了。需要等待多久,往往是不可预知的。相信你一定见过在路边滞留,招手拦车的人群。同样,当硬盘速度上千倍的提高后,将随之产生大量IO中断,Linux内核的中断驱动式IO处理(Interrupt Driven IO Process)就显得效率不高了。
操作系统的世界里,除了中断式IO处理的方式(即上面提到的被动的派发式工作),还有一种IO处理方式叫做定点轮询(polling)。还是用出租车的例子,试想在机场外出租车排队接客是怎么工作的——有一个或者多个专门的出租车道,排着一队队等候的出租车,当乘客从航站楼中一涌而出时,一辆辆出租车能够用少于十来秒的时间高效的接走一位乘客,后面的车紧接着跟上处理下一位客人。
PMD就是按照类似的机制工作的,SPDK中其他所有的组件也是按照这个理念设计的。专门的计算资源(特定的CPU核)用来主导存储设备的轮询式处理——就像专门的出租车道和车流用来处理乘客任务,数据包和块得到迅速派发,等待时间最小化,从而达到低延时、更一致的延时(抖动变少)、更好的吞吐量的效果。
那么,轮询模式驱动是否在所有的情况下都是最高效的处理IO的方式呢?答案是”也不尽然”。设想一下,如果航站楼里没有什么旅客出来,乘车的人稀稀拉拉的时候,我们可以看到出租车候车区等候派工的车辆长龙,这些等待的车子完全可以到市区去扫活儿,做些更有意义的事情。同样的道理,对于低速的SATA HDD,PMD的处理机制不但给IO性能带来的提升不明显,反而浪费了CPU资源。
这就是为什么我们在学习计算机课程时,老师会讲所谓”中断驱动IO处理”是比其他大部分IO处理机制更好的调度方式。因为在那个年代,CPU的速度远大于磁盘等存储设备,CPU也没有很多核或线程交给操作系统用来做更特殊的事情。无论如何,是终端驱动处理还是轮询驱动处理,取决于系统硬件的搭配方式,不同的条件会匹配不同的优化策略。
SPDK中包含了多个子组件,通过用户态处理机制和轮询驱动模式相互联系。每个子组件都是为了解决整个存储系统中的某一部分瓶颈问题而存在的。当然,用户可以选择只将这些子组件单独拆出来,用到非SPDK的框架中,去优化他们自己的存储处理堆栈。举例来说,SPDK中有个组件叫用户态网络服务(UNS,UserSpace Network Services)库,这是一个Linux内核TCP/IP协议栈的替代品,能够突破通用TCP/IP协议栈的种种性能限制瓶颈。通过使用用户态的,轮询方式的TCP/IP协议栈,SPDK能够在更少的CPU指令周期条件下处理TCP/IP数据包排序和计算,达到极高的IOPS性能。
SPDK中大概有三类子组件:网络前端、处理框架、后端。
网络前端子组件包括DPDK网卡驱动和上面提到的用户态网络服务(UNS)。DPDK在网卡侧提供了一个高性能的发包收包处理框架,在数据从网卡到操作系统用户态之间提供了一条快速通道。UNS代码则接续这一部分处理,”crack”了TCP/IP数据包的标准处理方式,并形成iSCSI命令。
从这个环节开始,”处理框架”部分拿到了数据包内容,将iSCSI命令转换为SCSI块级命令。然而,在它将这些命令发到”后端”驱动之前,SPDK提供了一套API框架,让厂商能够插入自己定义的处理逻辑(架构图中绿色的方框)。通过这种机制,存储厂商可在这里实现例如缓存、去重、压缩、加密、RAID计算,或擦除码(Erasure Coding)计算等功能,使这些功能包含在SPDK的处理流程中。在SPDK的开源软件包里,会有这些功能的实现样例——虽然不建议用户直接在为生产环境准备的产品代码里照搬。
最后,数据到达了”后端”驱动层,在这里SPDK和物理块设备交互(读和写操作)。如前所述,SPDK提供了用户态的PMD,支持NVMe设备、Linux AIO设备(传统spinning硬盘)、RAMDISK设备,以及利用到英特尔I/O加速技术的新设备(CBDMA=3D XPoint?)。这一系列后端设备驱动涵盖了不同性能的存储分层,保证SPDK几乎与每种存储应用形成关联。”
SPDK接口探秘
理论转载完了,我们再来看看实践。看完你就发现接口很简单,到底好不好用就不知道了。毕竟,任何东西都有很多坑,微软的大牛说职业程序员开发的1000行代码平均有10个bug。阿呆总是用这个结论来安慰自己。
怎么把自己的驱动集成进去?
在nvme_impl.h文件里面注册一下自己的callback函数,内容包括内存申请,内存映射,PCI参数和空间配置。
NVMe初始化
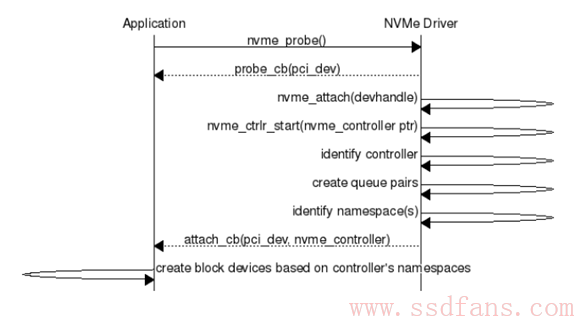
如下图,看起来是用户调用nvme_probe函数,相当于注册了驱动。NVMe驱动自动完成加载,Identify,创建队列等,通过Callback函数回调告诉用户结果。最后,用户根据namespace情况创建块设备。
IO怎么操作?
很简单,用户只要调用nvme_ns_cmd_xxx系列函数就能把读写命令放到队列里面,后面只需要轮询调用spdk_nvme_qpair_process_completions读取队列的结果,NVMe驱动看到这个函数后,就去看命令CQ是不是回来了,如果回来,就调用这个命令注册的Callback。
下一篇我们来赶赶时髦,看看SPDK怎么实现NVMe Over Fabric。
引用:

