前面写了那么多铺垫,其实是为了引出阿呆的老关系户韩国科学家提出的一个用户态NVMe架构:NVMeDirect,你终于明白标题的意思了吧?论文标题和作者如下,没兴趣看英文原文的人就看阿呆慢慢给你讲吧。

特点
相比SPDK,NVMeDIrect有以下特点,按作者的说法是优点:
- 和传统内核态驱动共存,比如内核驱动使用SSD的一个分区,用户态驱动使用别的分区,反正大家划分地盘,自己种自己的地。
- 在命令队列,IO回调,IO调度,缓存等方面进行了优化。IO可以根据自己的特点选择不同的策略,比如对延迟要求高,就自己搞一个队列,发完命令一直轮询读结果。还可以搞一个高优先级队列,数据库的日志就可以放到这个队列,提升性能。
架构
如下图,Admin Tool是管理工具。当一个用户线程发起IO命令,命令就传到内核态,内核驱动为它建立发送队列和完成队列以及Doorbell,并把内存地址用dma common mmap()函数映射到用户态地址空间,完成这些初始化工作后,用户态程序后面就能跳过内核直接往自己的地址读写来发送命令,接收结果。
IO结果使用轮询方式读取。
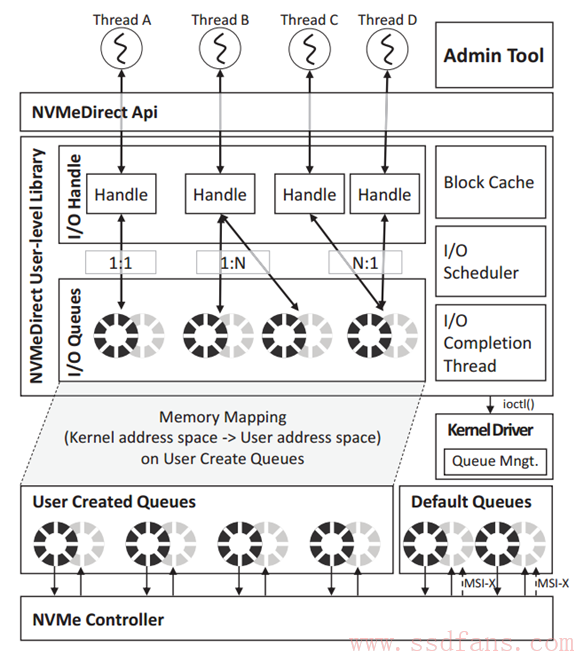
还提供了各种接口,如下图。

发送命令的工具叫做Handle,每个handle可以有不同的特性,比如Cache,IO调度和完成等,这样就可以根据Handle对IO进行分组。1个Handle可以分到不同队列,比如读写分开。也可以多个线程都绑到1个队列上。
性能测试
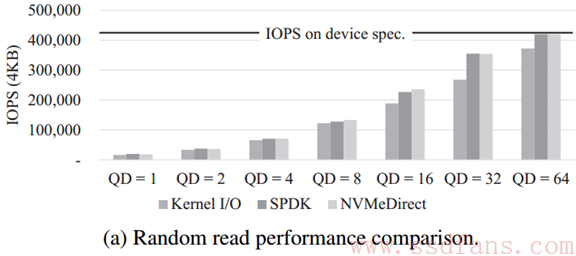
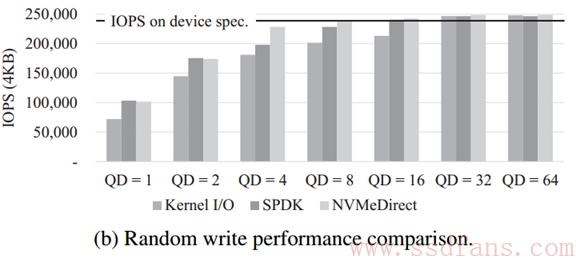
如下图,看得出来,SPDK和NVMeDirect其实差不多,因为都是用户态的,内核态多了一个内核层的消耗。
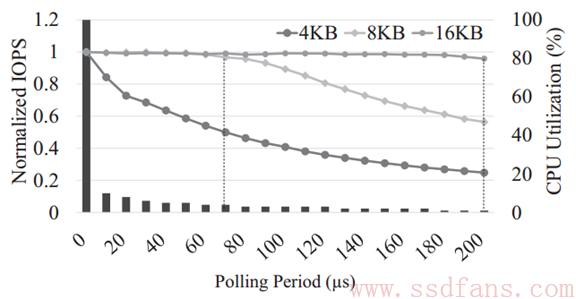
再来看看轮询周期与IOPS的关系,如下图,明显,IO数据块越小,需要的轮询周期越短,数据块大了之后,轮训周期可以长一点,节省CPU。
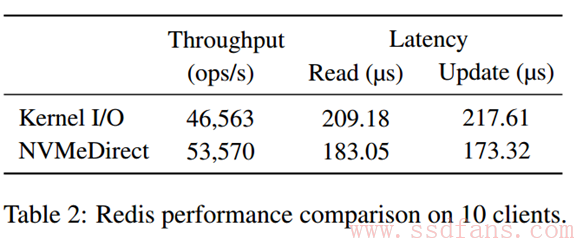
延迟也是个重要的指标。NVMeDirect是用户态的,所以节省了内核态的消耗,延迟照理说会好很多,下面的表格也证实了这个想法。
阿呆的思考:优缺点
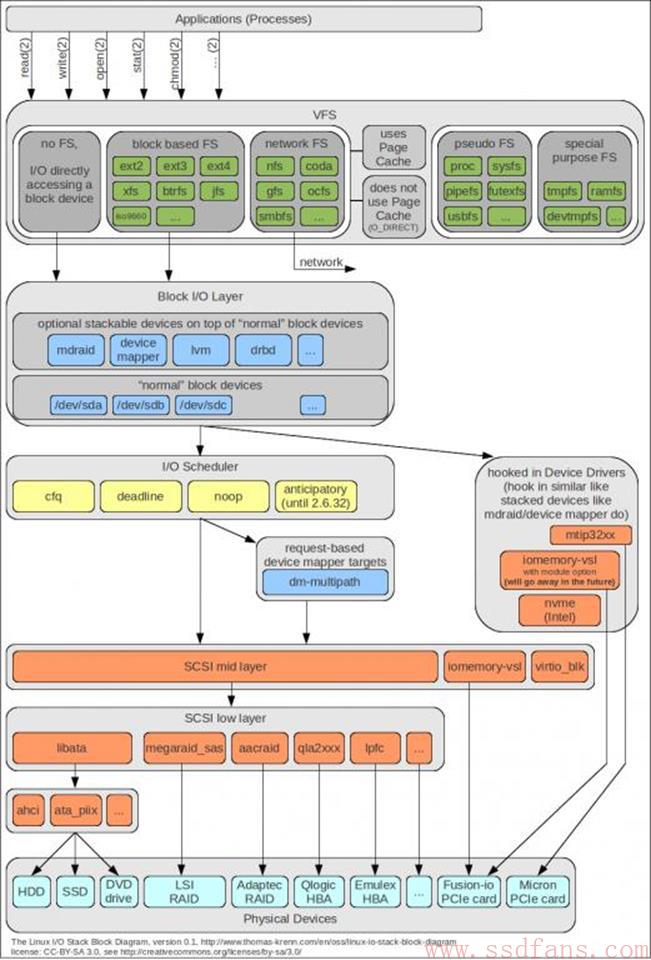
其实用户态NVMe SSD驱动优势挺明显的,就是性能好,延迟短,为什么,因为省掉了Linux IO Stack的一层层消耗。如下图,传统用户态程序要读写,要基于文件,然后到内核态,通过文件系统,块设备驱动,再发到物理设备。NVMeDirect或者SPDK是用户态程序直接发IO到物理设备,延迟大为缩短。
但是缺点也很明显,就是不通用。以前的架构用不了了,以前是基于文件系统的,而文件系统位于内核态,全放到用户态后文件系统就没用了。需要自己开发一套程序,所以适合有开发能力,又愿意花时间去测试,慢慢搞稳定的项目。
引用

