作者:斯托瑞吉
今年的FMS2016刚结束,Storage class memory成为了热门,前段时间刚看了Diablo的Memory1,还没研究完, 这不三星携手Netlist隆重推出了HybriDIMM,实际都叫做NVDIMM,实属于Storage class memory—本质上用Flash介质充当memory,在容量成本和性能三者找一个综合,替代DRAM做CPU和SSD/HDD之间的一层data tier。但架构和设计上还是有很大的不同,本文就想分析下这两种产品和架构的异同点,纯做技术分析对比。分析数据来源于网络文档、产品官方文档加上个人一些推断,因为是推断,不保证100%正确。当然有熟悉这些产品的专家指点一二,先行谢过。
正文之前的题外话,去年三星投资了Netlist进军Storage class memory,今天就推出了HybriDIMM产品的结果来看,速度和意图都值得称赞。三星以前没怎么重视Storage class memory,为什么突然就杀进来了?项庄舞剑,意在沛公(3DX)。不多说了。
查阅网络资料,总结一下Memory1和HybriDIMM产品的几项重要参数对比:
|
Memory1 |
HybriDIMM |
|
|
容量 |
128G/256G |
256G/512G |
|
介质 |
Flash |
Flash+DRAM(8G/16G) |
|
RAM:Flash capacity |
1:8(typical recommend), flexible adjust by instance |
1:32 |
|
主控 |
有 |
有 |
|
NVDMM type |
NVDIMM-F |
NVDIMM-P? |
|
Form factor |
DDR4-DIMM/LRDIMM&RDIMM |
DDR4-DIMM/LRDIMM |
|
软件/驱动 |
DMX |
PreSight |
|
Interface speed |
Up to 2133MT/s |
Up to 1866MT/s |
|
Linux |
Linux 4.5+ AppDirect API |
|
|
Cache |
Separate DIMM slot DRAM as cache |
On board DRAM as cache |
|
架构 |
Separate DIMM |
Hybrid DIMM |
这里的架构称呼(Separate DIMM and Hybrid DIMM)只是直观叫法,非官方名称。从Memory1和HybriDMM产品手册上来,这两者硬件架构区别的关键点是作为Cache的DRAM放在哪里,一个物理上完全隔离,应用模式为传统的Slot0:DDR4 RDIMM/LRDIMM + Slot1:Memory1, 另一种是把DRAM放到自身的DIMM条上来,应用模式为Slot0:HybriDIMM。所以称之为Separate DIMM和Hybrid DIMM架构比较贴切,对应的协议标准为NVDIMM-F和NVDIMM-P类型。再来回忆下JEDEC定义的这两种标准:

Separate DIMM和Hybrid DIMM架构,他们对于数据的读写有什么区别? 比较巧的是在今年的FMS大会上就有某司用图分析了这两种架构,话说这图画的是非常不错,基本概括了两者硬件结构的不同和数据流。
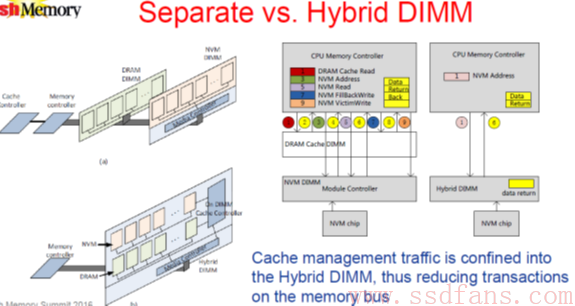
如上所述Separate DIMM架构把DRAM DIMM/NVM(Flash) DIMM物理内存通道上完全分开,cache控制交给了host/CPU和软件,NVM DIMM控制器只负责Flash的读写。
第一步:CPU memory controller发起DRAM cache读操作
第二步:如果命中,直接返回数据,Cache由上层软件来控制,对Diablo来讲就是DMX,如果不命中,进入第三步。Right?
第三四步:数据在NVM(Flash) DIMM上,获取NVM(Flash) address为NVM read做准备。
第五六步:对NVM address发起NVM读操作,数据返回到DRAM cache中,然后返回给CPU。这时候这个地址所代表的region的数据在DRAM cache有一份copy了。
第七八九步:有写操作时,对DRAM cache保持写,按Diablo话说,只要region是”dirty”状态,这段region的数据会一直驻存在DRAM cache中,减少Flash的频繁写操作带来的寿命损伤和写性能问题。直到region为”clean”时,才会写入数据到Flash,也就是这里的第九步。数据何时为dirty何时为clean,如何管理,就是上层软件算法要处理的问题。个人浅显的认为算法设计为统计这段数据区间的最近一段访问频率和预测未来可能的访问,来标注这个region的”dirty”或”clean”状态。
所以这里可以看出Separate DIMM架构的一个数据块请求(多大?)会在Memory bus产生平均6 cycles地址和命令数据的交互,Cache管理交上层对Diablo而言就是DMX软件(没有资料深入介绍软件的算法和流控,或许这是核心IP保护)。好处是灵活,根据应用场景RAM和Flash容量比例可自由分配,全局调配,DMX算法设计可灵活。坏处是bus读写效率低,需要较多的cycles来完成一个数据块的请求,在重workload下影响性能。
看下Hybrid DIMM架构,也就是上图中的最右图,一次读写请求操作简化为2个cycles的bus请求,效率提高,读写速度加快。实际上相比较Separate DIMM架构一到九步一步也没有少,只不过把中间的操作交由Hybrid DIMM的控制器来完成,这里控制器做了更多的工作(cache管理,NVM read/write…) prefetch data算法的实际操作交由控制器和FW来完成,理论上会快些。PreSight软件如何和HybriDIMM的控制器和FW交互和分工,这里面的细节不得而知,有兴趣可自行研究推断画个流程图来。总结这种架构,DRAM和Flash容量比例固定,控制器和FW接管更多工作(也是设计考验),一次数据请求bus交互cycles少性能好,整体模块独立不依赖于DDR4 DIMM,可向后扩展为NVDIMM-P。
最后聊点性能的问题,无论Memory1还是HybriDIMM,都十分强调其Prefetch data到DRAM的重要性。明显地影响到性能主要有两点,其一是DRAM cache和Flash capacity的比例,其二是Prefetch data算法设计和实现。
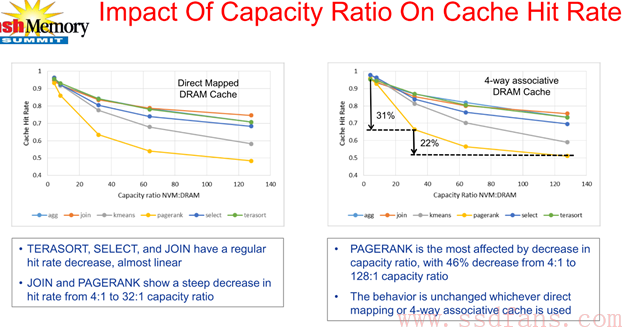
用大数据benchmark来评价和实测这两点设计比较合适,下图有一些数据评估,Pagerank/Kmeans对ratio比较敏感,DRAM比Flash容量比越低,性能下降严重(rand pattern多?)。agg/kmeans…寻址pattern是怎么样的,本人不得而知,大数据应用专家们来评估下这份报告的真实和正确性。最好性能表现的比例是1:4。1:64是兼具性能和成本的(DRAM越少成本越低)
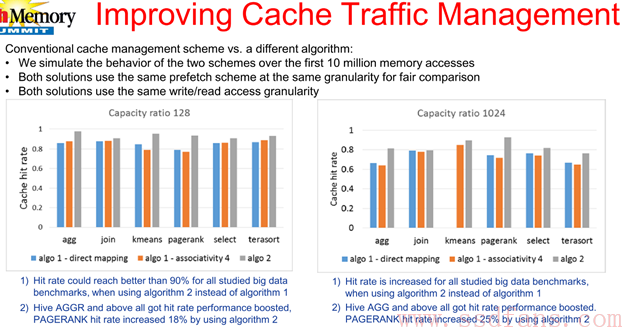
另外一个比较有趣的现象是,Cache管理用了algo2算法可显著的提高studied big data benchmarks cache hit rate 25%。不了解algo2,也是软工的核心工作。
最后对Hybrid DIMM留下问题思考:
- BIOS和Linux如何支持HybriDIMM?
- NVDIMM-P的DRAM map的模式是否支持如何使用?
- 什么应用场景选择多少RAM:Flash ratio?HybriDIMM的ratio可否动态可调?
- Flash介质属性,FW FTL如何管理
- 控制器架构?
- 功耗?
- HybriDIMM每GB价格?
- 软件I/O stack?
参考:
DDR4 DIMM Devices With Hybrid DRAM & NVM For Big Data Performances At Low Cost
http://www.tmcnet.com/usubmit/2016/08/09/8403015.htm

