作者 中国科技大学 帅师兄
近年来,无论是在学术界还是工业界,机器学习都是炙手可热的一个研究方向。机器学习也得到了广泛的应用,比如在计算机视觉、语音识别、自然语言处理、智能医疗等领域。那么在NAND 闪存相关的领域有没有可能也利用机器学习呢?最近,帅师兄看了一篇利用机器学习来确定TLC 3D NAND闪存耐久度性能分布的学术文章。下面就详细介绍一下这几个意大利科研人员的工作。
背景介绍
大家都知道现在NAND闪存得到了广泛的应用,比如在便携设备、智能手机、固态硬盘等。为了降低位成本(bit cost)和提高存储能力,NAND闪存从2D平面结构转变到3D堆叠结构。这样的转变带来了很多的问题。如何确定闪存可靠性的性能参数就是其中的一个问题。具体地讲,为了找到最优的运行参数组合减小编码错误率,往往需要仔细测试多组可行的参数组合。而闪存结构从二维变为三维后,仅仅通过主观判断来选择最优参数组合已经几乎不可能。而且,不同的纠错码(Error Correction Codes, ECCS)策略还有像重读(Read Retry)这样的二次纠错机制也使得问题变得更加复杂。
在参数组合如此多,问题变得非常复杂的情况下,机器学习算法中的数据聚类(Data Clustering)算法就可以用来按照耐久度性能的差异把TLC 3D NAND闪存的不同部分分为几类。通过实验,论文作者发现利用半监督学习,聚类算法可以识别出闪存内不同部分的性能差异。然后分类结果可以用来优化纠错码的策略,从而找到低密度奇偶校验(LDPC)的最优编码率。
实验设计
作者利用的测试设备如下图所示。该设备装有最先进的支持 PCIe Gen3接口的NVMe 存储控制器ASIC芯片,DRAM 缓存,以及一套SO-DIMM插槽。这个板子最多可以支持8个SO-DIMM 闪存条(可插3D NAND)。每个闪存条包含8个颗粒(die)。外部供电。确定性能参数的系统通过PCIe接口与一个x86个人电脑传输数据。在这台个人电脑上,运行机器学习算法进行数据后处理。
 数据聚类
数据聚类
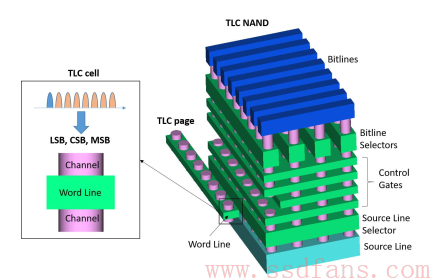
论文作者工作的目标是寻找在不同耐久度实验3D NAND闪存聚类的一个大概的聚类方法,所以,他们在不同的测试条件下(不同的温度、循环时间)对不同的闪存条进行了测试。闪存条是TLC 3D NAND 闪存,结构如下图所示。在一个闪存块(Block)内,按照不同的页类型,对所有层上的字线(Wordline)进行了数据分析。注意这里页类型分为快页(Upper Page),中页(Center Page),慢页(Lower Page)。一页的大小是16KB,分为4个4KB的块(Chunk)。一块(Chunk)是一个最小的数据读取单元。论文作者对800多个不同的闪存块(Block)的数据进行了数据聚类。测试时间持续了几个月。
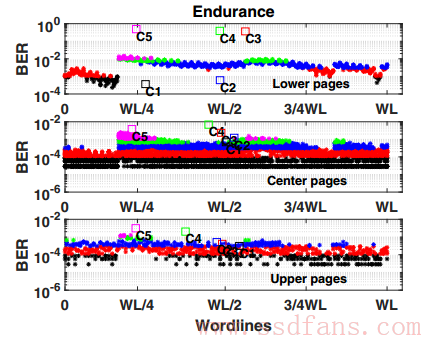
 性能测试的数据是以一种随机的模式反复地对一个闪存块(Block)进行写入和擦除操作,并读出其中的数据以及计算误码率(Bit Error Rate, BER)。作者在每次耐久度实验结束时,即3千次编程/擦除循环结束后,计算得到误码率(BER)。
性能测试的数据是以一种随机的模式反复地对一个闪存块(Block)进行写入和擦除操作,并读出其中的数据以及计算误码率(Bit Error Rate, BER)。作者在每次耐久度实验结束时,即3千次编程/擦除循环结束后,计算得到误码率(BER)。
数据聚类结果
上面一部分讲了怎么得到性能测试的数据。有了这些数据,就可以把这些数据”喂给”k均值聚类算法(k-means data clustering algorithm)。k均值算法把输入数据集分成K个不同的簇(Cluster)。它反复地计算每个球形簇的类中心直到最终形成k个不同的簇。如下图所示,作者把输入数据集分成了5类。从图中可以看出,虽然每个簇之间并没有明确地分割开,但是,该算法还是把不同误码率的区域分开了。为了进一步方便数据分析,论文作者按照页的类型又进行了聚类,因为我们知道不同页类型的耐久度往往是不同的。
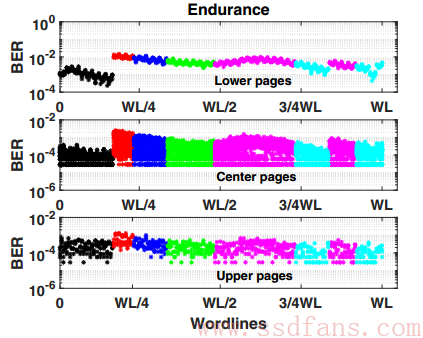
 对于纠错码或者二次纠错算法等应用的聚类,复杂度要大非常多。论文作者对k均值算法加了一个限制条件,即把无监督学习修改为半监督学习。附加的限制条件是构成一个TLC页的所有闪存块(Block)都必须分到同一簇里面。下图是加了限制条件后的聚类结果。如下图所示,3D NAND闪存的位线(WL)上的所有页分成了6个簇,其中每个簇都包含三种不同类型的页。图中每个不同颜色代表一个不同的簇。
对于纠错码或者二次纠错算法等应用的聚类,复杂度要大非常多。论文作者对k均值算法加了一个限制条件,即把无监督学习修改为半监督学习。附加的限制条件是构成一个TLC页的所有闪存块(Block)都必须分到同一簇里面。下图是加了限制条件后的聚类结果。如下图所示,3D NAND闪存的位线(WL)上的所有页分成了6个簇,其中每个簇都包含三种不同类型的页。图中每个不同颜色代表一个不同的簇。
 低密度奇偶校验码(LDPC)的最优化
低密度奇偶校验码(LDPC)的最优化
下面首先介绍对3D NAND闪存进行迭代低密度奇偶校验码的基础知识(包含背后的数学知识),不感兴趣的读者可以跳过,直接看后面优化后的结果。
1. 3D NAND闪存迭代低密度奇偶校验码(LDPC)的基础知识
低密度奇偶校验码(LDPC)被认为是可以达到逼近香农极限(Shannon Limit)的帧差错率(Frame Error Rate, FER)的一类编码。对于这一类编码,要应用于3D NAND 闪存,要求它必须不仅可以出色地解码而且适合在大规模集成电路(VLSI)上实现。准循环LDPC码(QC-LDPC)就可以满足这两点要求。QC-LDPC的H矩阵含有循环矩阵。QC-LDPC码的检验H矩阵可以写做如下的形式:
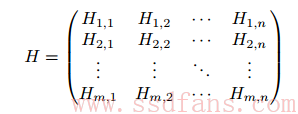 其中,每个子矩阵Hi,j 都是一个循环矩阵。
其中,每个子矩阵Hi,j 都是一个循环矩阵。
闪存往往要求很高的编码率(又叫信息率)(Code Rate)。LDPC码的模块化特点使得它可以迭代地对编码率进行修正。在3D NAND 闪存的使用过程中,误码率(BER)的变化很大程度上受TLC页分布的影响。因此,可以设计一种纠错码策略能够自主地修改编码率而不必去改变硬件的结构。
2. 优化后的结果
LDPC编码率优化后的效果可以用分类后得到的每个簇的最差误码率(BER)来评估。下表为在3千次编程/擦除后每一簇的最差误码率以及保持帧差错率在1e-4以上时的LDPC编码率大小。
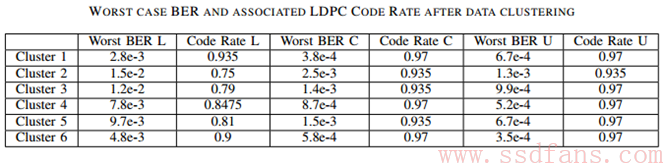 在没有聚类和不分页处理的时候,默认编码率取为0.75。在分不同页类型进行处理时,整体编码率得到了提高,因为慢页可以取最低的编码率,而中页与快页都可以取至少0.935的编码率。平均后的编码率为0.87。这意味着可以额外得到16%的闪存空间用于存储用户的数据。当然,最优的编码率是在进行聚类之后得到的。经过公式计算得到应用聚类和分页处理后的编码率为0.93。这意味着可以额外分配24%的闪存空间用于存储用户的数据。所以,经过数据聚类算法和分页处理后的LDPC码的编码率是最高的,此时,LDPC编码是最优的。
在没有聚类和不分页处理的时候,默认编码率取为0.75。在分不同页类型进行处理时,整体编码率得到了提高,因为慢页可以取最低的编码率,而中页与快页都可以取至少0.935的编码率。平均后的编码率为0.87。这意味着可以额外得到16%的闪存空间用于存储用户的数据。当然,最优的编码率是在进行聚类之后得到的。经过公式计算得到应用聚类和分页处理后的编码率为0.93。这意味着可以额外分配24%的闪存空间用于存储用户的数据。所以,经过数据聚类算法和分页处理后的LDPC码的编码率是最高的,此时,LDPC编码是最优的。
参考文献
C. Zambelli et al., “Characterization of TLC 3D-NAND Flash Endurance through Machine Learning for LDPC Code Rate Optimization,” 2017 IEEE International Memory Workshop (IMW), Monterey, CA, 2017, pp. 1-4.

