作者 GCM
目前,百万甚至千万级别的IOPS数据访问量已成为一个大趋势,并且当前的SSD展现着越来越高效的性能表现。在这种趋势下linux的块设备层渐渐成为了整体系统性能提升的主要瓶颈。本文主要讨论的是在多核系统下,如何利用Multi-queue减小块设备层对整体性能的影响。
传统的块设备层针对于千/万级别的IOPS数据访问量是有所余力的,但是面对与日俱增的大数据访问,特别是在底层SSD提供更高速的访问性能以及上层系统多核化的情况下,传统快设备层将会严重影响整体系统的性能。
针对快设备层的优化,有人曾提出通过绕过快设备层的方式来实现上层系统与底层SSD的性能匹配。显然,该方法存在较大的复杂性,同时也将快设备层中的请求调度等功能移除了。然而,从linux 3.13版本的内核开始,Multi-queue已经被添加到代码中用以减小快设备层对系统性能的影响。其主要思想是为每个核配置一个请求队列,从而均衡多核之间的负载,并减少对请求队列的锁竞争。
首先,针对于传统的快设备层,如图1所示,假设底层仅有一个硬件存储设备,那么块设备层将实例化一个请求队列。所有应用程序发送的IO请求将全部提交至该队列中,然后交由该队列进行相应的处理,例如合并,调度等。现在,从这个角度出发,我们可以发现多个并行的应用程序在请求队列上存在锁竞争的问题,从而严重影响了SSD处理请求的效率。
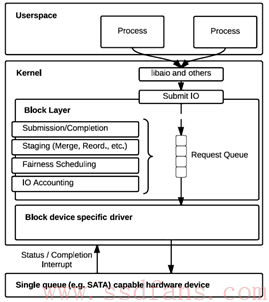
图 1 传统快设备层结构
其次,针对于目前的多核系统,将会存在更多的中断,上下文切换以及远程访问的问题。因此,传统的单个请求队列将成为主要竞争资源,从而进一步限制了底层SSD的处理效率。
因此,Multi-queue应运而生,结构图如图2所示。其主要思想在于将单个请求队列上的资源竞争分散至多队列上。该多队列主要分为以下两种:软件队列以及硬件分配队列。
软件队列:软件队列原则上可为每个核或者每个socket配置一个处理队列。假设一个NUMA系统有4个sockets,每个socket有6个核,那么最少可配置4个软件队列,最多配置24个软件队列。在对应的每个软件队列中可进行请求调度,添加标记以及计数等功能。在此基础上,每个socket或者核直接将请求发送至其对应的软件队列中, 从而可避免单请求队列造成的锁竞争问题。
硬件队列:硬件队列主要负责与底层设备驱动的匹配,即存在多少个设备驱动,则配置对应数量的硬件队列。其将负责将来自软件队列的请求发送至驱动层。
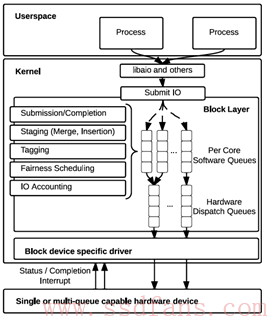
图 2 Multi-queue块设备层结构
Multi-queue中的调度问题:目前Multi-queue在设计过程中寄希望于底层SSD已经能够提供足够的性能使得随机访问与顺序访问呈现类似的访问性能,并且,其同样希望当前插入到各个软件队列中的数据具有强局部性,因此,当前linux内核代码中的软件队列没有提供相关的调度设计。但是,若底层存储设备是机械硬盘时,那么在软件队列中的请求调度是十分有必要的。另外,在Multi-queue的环境下,公平性调度的意义已经不大,因为每个核或者socket都配有一个软件队列,那么来自于多个核的请求将能够被均衡负载。
当请求加入到硬件队列后,其会被打上一个唯一标签,该标签会随后传入驱动层,主要用于判断此请求是否已被处理完成。
除了上述工作之外,Multi-queue的作者还对应地提供了计数功能以及修改了blktrace的相关机制代码,从而能够提供一定的统计功能以及请求纪录功能。
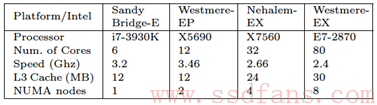
在实际测试中,基于Multi-queue的快设备层能够取得接近最优话的性能。如下图所示,其中MQ表示Multi-queue块设备层,SQ表示传统的单队列情况, Raw表示最优化的情况。其实验平台信息如表1所示,分别取1,2,4,8 sockets系统。底层设备采取空设备模拟来消除SSD的性能对测试的干扰。在软件队列和硬件队列配置上,每个core配置一个软件队列,每个socket配置一个硬件队列。
从实验结果中,我们可以发现,MQ能够取得极大的性能提升。

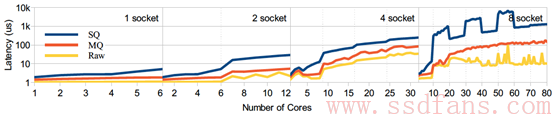
图 3 IOPS和时延测试
表格 1 实验平台参数
若要开启Multi-queue功能,则按以下命令操作:
在/etc/default/grub中修改
GRUB_CMDLINE_LINUX=”scsi_mod.use_blk_mq=1″
Sudo update-grub
参考文献:
M. Bjorling, J. Axboe, D. Nellans, and P. Bonnet. Linux block IO: Introducing multi-queue SSD access on multi-core systems.
Multi-queue 代码分析
源码结构如下图:
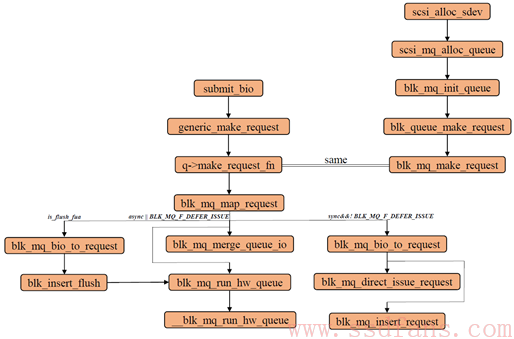
当要写一个page页到底层设备时,需要通过submit_bh进行提交。该函数主要负责对初始化一个bio以及对其进行相关的封装处理。其函数调用主要的流程为:submit_bh -> submit_bh_wbc -> submit_io ->generic_make_request。一旦bio进入generic_make_request则说明其将在块设备层中被进行相关处理工作。
generic_make_request函数如下:
*****************************************************************
blk_qc_t generic_make_request(struct bio *bio)
{
struct bio_list bio_list_on_stack;
blk_qc_t ret = BLK_QC_T_NONE;
if (!generic_make_request_checks(bio)) //判断当前bio是否有效
goto out;
if (current->bio_list) {
bio_list_add(current->bio_list, bio);
goto out;
}
//上述过程要求当前的make_request_fn每次只能被触发一次,因此,通过current->bio_list判断当前是否有bio在其中,若有则将当前这个加入到尾部等待被处理,若没有则可直接处理该bio
//还有一个值得注意的地方是,通常情况下,current->bio_list是为NULL的,因此,上述if语句将会在进行递归调用generic_make_request时候会执行。而该递归调用的地方即后面的q->make_request_fn函数里面,该函数会判断当前的bio是否超过了最大能处理能力范围,若是则将其拆分,拆分后的剩余bio将会再次被加入到generic_make_request函数中,而此时,current->bio_list中已经包含了原始的超过最大处理能力的bio,为了避免再次出发q->make_request_fn函数,则在上述if语句中先退出,完成拆分后满足处理能力大小的bio
BUG_ON(bio->bi_next);
bio_list_init(&bio_list_on_stack); //初始化该双向链表
current->bio_list = &bio_list_on_stack; //当前为NULL
do {
struct request_queue *q = bdev_get_queue(bio->bi_bdev); //获得bio对应的设备队列
if (likely(blk_queue_enter(q, false) == 0)) { //判断当前的设备队列是否有效能够响应该请求
ret = q->make_request_fn(q, bio); //将bio进行进一步处理,放入块设备层的处理队列中
blk_queue_exit(q);
bio = bio_list_pop(current->bio_list);
} else {
struct bio *bio_next = bio_list_pop(current->bio_list);
bio_io_error(bio);
bio = bio_next;
}
} while (bio);
current->bio_list = NULL; /* deactivate */ //clear this bio list and make_request function is avalible again
out:
return ret;
}
*************************************************************
若当前的设备队列有效,则会调用q->make_request_fn函数处理该bio,将其放入块设备层处理队列中。
q->make_request_fn函数在一开始在blk_queue_make_request函数中被注册为blk_mq_make_request函数或者blk_sq_make_request,其判断标准是当前块设备层支持多个hardware queue还是单个hardware queue。
为了说明该注册q->make_request_fn函数的过程,我们从队列初始化源头开始解释起:
1. 首先在driver\scsi文件夹下的scsi_scan.c文件中,scsi_alloc_sdev函数会判断当前scsi支持的块设备是否支持multiqueue:
***********************************************************
if (shost_use_blk_mq(shost)) // multiple queue is enabled
sdev->request_queue = scsi_mq_alloc_queue(sdev); //scsi定义的MQ队列
else
sdev->request_queue = scsi_alloc_queue(sdev);
*****************************************************************
2.若上述设备支持mq则进入scsi_mq_alloc_queue函数,该函数中主要进行设备队列的初始化,blk_mq_init_queue,在blk_mq_init_queue 函数中根据set信息进行与该设备队列相关的信息参数初始化,过程如下:
***********************************************************
/* mark the queue as mq asap */
q->mq_ops = set->ops; //标记为MQ队列
q->queue_ctx = alloc_percpu(struct blk_mq_ctx); //获得percpu的地址
建立software queue环境
if (!q->queue_ctx)
goto err_exit;
q->queue_hw_ctx=kzalloc_node(nr_cpu_ids* sizeof(*(q->queue_hw_ctx)), GFP_KERNEL, set->numa_node); //获得hardware queue上下文环境
if (!q->queue_hw_ctx)
goto err_percpu;
q->mq_map = blk_mq_make_queue_map(set); // 建立software queue和hardware queue之间的映射关系
if (!q->mq_map)
goto err_map;
blk_mq_realloc_hw_ctxs(set, q);
if (!q->nr_hw_queues)
goto err_hctxs;
INIT_WORK(&q->timeout_work, blk_mq_timeout_work);
blk_queue_rq_timeout(q, set->timeout ? set->timeout : 30 * HZ); //定义scsi设备队列超时设定
q->nr_queues = nr_cpu_ids;
q->queue_flags |= QUEUE_FLAG_MQ_DEFAULT;
if (!(set->flags & BLK_MQ_F_SG_MERGE))
q->queue_flags |= 1 << QUEUE_FLAG_NO_SG_MERGE;
q->sg_reserved_size = INT_MAX;
INIT_WORK(&q->requeue_work, blk_mq_requeue_work);
INIT_LIST_HEAD(&q->requeue_list);
spin_lock_init(&q->requeue_lock);
if (q->nr_hw_queues > 1)
blk_queue_make_request(q,blk_mq_make_request); //注册q->make_request_fn函数
else
blk_queue_make_request(q, blk_sq_make_request);
/*
* Do this after blk_queue_make_request() overrides it…
*/
q->nr_requests = set->queue_depth;
if (set->ops->complete)
blk_queue_softirq_done(q, set->ops->complete);
blk_mq_init_cpu_queues(q, set->nr_hw_queues);
get_online_cpus();
mutex_lock(&all_q_mutex);
list_add_tail(&q->all_q_node, &all_q_list);
blk_mq_add_queue_tag_set(set, q);
blk_mq_map_swqueue(q, cpu_online_mask);
mutex_unlock(&all_q_mutex);
put_online_cpus();
return q;
err_hctxs:
kfree(q->mq_map);
err_map:
kfree(q->queue_hw_ctx);
err_percpu:
free_percpu(q->queue_ctx);
err_exit:
q->mq_ops = NULL;
return ERR_PTR(-ENOMEM);
}
***********************************************************
通过上述函数我们可以发现,当目前支持多个hardware queue时,则在blk_queue_make_request中将q->make_request_fn注册为blk_mq_make_request。(本文先仅讨论多hardware queue情况)
现在我们回到blk_mq_make_request函数,其过程如下:
***********************************************************
//多hardware queue的情况下不采用plug queue
const int is_sync = rw_is_sync(bio->bi_rw); //判断是否为同步
const int is_flush_fua = bio->bi_rw & (REQ_FLUSH | REQ_FUA);//判断是否为屏障IO
struct blk_map_ctx data;
struct request *rq;
unsigned int request_count = 0;
struct blk_plug *plug;
struct request *same_queue_rq = NULL;
blk_qc_t cookie;
blk_queue_bounce(q, &bio); //做DMA时的相关地址限制,可能该bio只能访问低端内存,因此需要将高端内存中的bio数据拷贝到低端内存中
if(bio_integrity_enabled(bio) && bio_integrity_prep(bio)) { //bio完整性判断
bio_io_error(bio);
return BLK_QC_T_NONE;
}
blk_queue_split(q, &bio, q->bio_split); //判断当前的bio是否超过了预设最大处理大小,若是则进行拆分,拆分后会进行generic_make_request函数调用
if (!is_flush_fua && !blk_queue_nomerges(q) &&
blk_attempt_plug_merge(q, bio, &request_count, &same_queue_rq)) //若非屏障IO并且设备队列支持合并且plug队列中可进行合并则进行合并工作
return BLK_QC_T_NONE;
rq = blk_mq_map_request(q, bio, &data); //在mq中注册一个request
if (unlikely(!rq))
return BLK_QC_T_NONE;
cookie = blk_tag_to_qc_t(rq->tag, data.hctx->queue_num);
if (unlikely(is_flush_fua)) {
blk_mq_bio_to_request(rq, bio); //将bio转换为request
blk_insert_flush(rq); //若是屏障IO则将其加入到flush队列中,该队列直接发送至driver
goto run_queue;
}
plug = current->plug;
/*
* If the driver supports defer issued based on ‘last’, then
* queue it up like normal since we can potentially save some
* CPU this way.
*/
if (((plug && !blk_queue_nomerges(q)) || is_sync) && /*有plug队列,且设备队列支持合并或者改请求是同步请求。。。*/
!(data.hctx->flags & BLK_MQ_F_DEFER_ISSUE)) { //延迟发送
struct request *old_rq = NULL;
blk_mq_bio_to_request(rq, bio); //转化为request
/*
* We do limited pluging. If the bio can be merged, do that.
* Otherwise the existing request in the plug list will be
* issued. So the plug list will have one request at most
*/
if (plug) {
/*
* The plug list might get flushed before this. If that
* happens, same_queue_rq is invalid and plug list is
* empty
*/
if (same_queue_rq && !list_empty(&plug->mq_list)) {
old_rq = same_queue_rq;
list_del_init(&old_rq->queuelist); //判断之前是否有能合并或者一样的请求,若有则删除之前的请求
}
list_add_tail(&rq->queuelist, &plug->mq_list); //将该请求加入到plug队列中
} else /* is_sync */
old_rq = rq;
blk_mq_put_ctx(data.ctx);
if (!old_rq) //无为处理请求
goto done;
if (!blk_mq_direct_issue_request(old_rq, &cookie)) //直接加入到底层scsi层队列中,并发往driver
goto done;
blk_mq_insert_request(old_rq, false, true, true); //加入到software queue中
goto done;
}
if (!blk_mq_merge_queue_io(data.hctx, data.ctx, rq, bio)) { //底层driver支持延迟发送或者为async请求
//能合并则进行合并,否则加入到software queue中
/*
* For a SYNC request, send it to the hardware immediately. For
* an ASYNC request, just ensure that we run it later on. The
* latter allows for merging opportunities and more efficient
* dispatching.
*/
run_queue:
blk_mq_run_hw_queue(data.hctx, !is_sync || is_flush_fua); //执行hardware queue
}
blk_mq_put_ctx(data.ctx);
done:
return cookie;
}
***********************************************************
上述函数直接说明在多hardware queue的环境下不考虑plug queue,而是直接判断能否发送至driver或者直接加入到software queue中。
为方便大家理解,我将上述函数中的几个重点函数摘抄解释如下:
blk_mq_map_request 该函数的目的在于在mq中注册一个请求:
***********************************************************
static struct request *blk_mq_map_request(struct request_queue *q, struct bio *bio, struct blk_map_ctx *data)
{
struct blk_mq_hw_ctx *hctx;
struct blk_mq_ctx *ctx;
struct request *rq;
int rw = bio_data_dir(bio);
struct blk_mq_alloc_data alloc_data;
blk_queue_enter_live(q); //判断设备队列是否有效,对该队列增加一个CPU副本访问
ctx = blk_mq_get_ctx(q); //根据CPU获得定义的software queue环境
hctx = q->mq_ops->map_queue(q, ctx->cpu); //在映射关系中根据software queue的cpu号确定hardware queue的上下文环境
//每个CPU对应一个software queue和hardware queue
if (rw_is_sync(bio->bi_rw))
rw |= REQ_SYNC;
trace_block_getrq(q, bio, rw);
blk_mq_set_alloc_data(&alloc_data, q, BLK_MQ_REQ_NOWAIT, ctx, hctx); //得到关于当前software/hardware queue的相关信息数据
rq = __blk_mq_alloc_request(&alloc_data, rw); //分配一个request,该request与当前的software queue和hardware queue相关
if (unlikely(!rq)) { //注册该request失败
__blk_mq_run_hw_queue(hctx); //执行hardware queue,腾出空间
blk_mq_put_ctx(ctx);
trace_block_sleeprq(q, bio, rw);
ctx = blk_mq_get_ctx(q);
hctx = q->mq_ops->map_queue(q, ctx->cpu);
blk_mq_set_alloc_data(&alloc_data, q, 0, ctx, hctx);
rq = __blk_mq_alloc_request(&alloc_data, rw);
ctx = alloc_data.ctx;
hctx = alloc_data.hctx;
}
hctx->queued++; //hardware queue中排队等待的请求加1
data->hctx = hctx;
data->ctx = ctx;
return rq;
}
***********************************************************
blk_mq_direct_issue_request 将请求直接加入到底层driver中,判断当前scsi设备能否处理该请求:
***********************************************************
static int blk_mq_direct_issue_request(struct request *rq, blk_qc_t *cookie)
{
int ret;
struct request_queue *q = rq->q;
struct blk_mq_hw_ctx *hctx = q->mq_ops->map_queue(q,
rq->mq_ctx->cpu);
struct blk_mq_queue_data bd = {
.rq = rq,
.list = NULL,
.last = 1
};
blk_qc_t new_cookie = blk_tag_to_qc_t(rq->tag, hctx->queue_num);
/*
* For OK queue, we are done. For error, kill it. Any other
* error (busy), just add it to our list as we previously
* would have done
*/
ret = q->mq_ops->queue_rq(hctx, &bd); //直接放入scsi队列中,返回是否能够被处理
if (ret == BLK_MQ_RQ_QUEUE_OK) {
*cookie = new_cookie;
return 0;
}
__blk_mq_requeue_request(rq); //标记该request的nr_phys_segments减1
if (ret == BLK_MQ_RQ_QUEUE_ERROR) {
*cookie = BLK_QC_T_NONE;
rq->errors = -EIO;
blk_mq_end_request(rq, rq->errors);
return 0;
}
return -1;
}
***********************************************************
blk_mq_insert_request 将请求加入到software queue队列中:
***********************************************************
void blk_mq_insert_request(struct request *rq, bool at_head, bool run_queue, bool async)
{
struct request_queue *q = rq->q;
struct blk_mq_hw_ctx *hctx;
struct blk_mq_ctx *ctx = rq->mq_ctx, *current_ctx;
current_ctx = blk_mq_get_ctx(q); //获得software queue环境
if (!cpu_online(ctx->cpu))
rq->mq_ctx = ctx = current_ctx;
hctx = q->mq_ops->map_queue(q, ctx->cpu); //找到对应的hardware queue上下文环境
spin_lock(&ctx->lock);
__blk_mq_insert_request(hctx, rq, at_head); //通过rq找到ctx,加入到software queue中
spin_unlock(&ctx->lock);
if (run_queue)
blk_mq_run_hw_queue(hctx, async); //运行hardware queue,用异步方式执行
blk_mq_put_ctx(current_ctx);
}
***********************************************************
其中,__blk_mq_insert_request 函数解释如下:
***********************************************************
static void __blk_mq_insert_request(struct blk_mq_hw_ctx *hctx, struct request *rq, bool at_head)
{
struct blk_mq_ctx *ctx = rq->mq_ctx;
__blk_mq_insert_req_list(hctx, ctx, rq, at_head); //加入到software queue
blk_mq_hctx_mark_pending(hctx, ctx); //标记该software queue中有请求需要被该hardware queue处理
}
***********************************************************
blk_mq_merge_queue_io 判断能否与当前software queue中的请求进行合并,若不行则加入到software queue中:
***********************************************************
static inline bool blk_mq_merge_queue_io(struct blk_mq_hw_ctx *hctx, struct blk_mq_ctx *ctx, struct request *rq, struct bio *bio)
{
if (!hctx_allow_merges(hctx) || !bio_mergeable(bio)) { //不允许merge
blk_mq_bio_to_request(rq, bio);
spin_lock(&ctx->lock);
insert_rq:
__blk_mq_insert_request(hctx, rq, false); //加入到software queue
spin_unlock(&ctx->lock);
return false;
} else {
struct request_queue *q = hctx->queue;
spin_lock(&ctx->lock);
if (!blk_mq_attempt_merge(q, ctx, bio)) { //进行合并尝试
blk_mq_bio_to_request(rq, bio); //无法合并则转向加入software queue中
goto insert_rq;
}
spin_unlock(&ctx->lock);
__blk_mq_free_request(hctx, ctx, rq); //将刚刚在software queue和hardware queue中注册的request去除,因为请求已经加入到software queue
return true;
}
}
*****************************************************************
blk_mq_run_hw_queue函数,描述如下:
*****************************************************************
void blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async)
{
if (unlikely(test_bit(BLK_MQ_S_STOPPED, &hctx->state) ||
!blk_mq_hw_queue_mapped(hctx)))
return;
if (!async) { // false and run
//若async为flash则说明该处理是同步的,需要马上处理,若是异步则将该操作交由kblocked进行处理
int cpu = get_cpu();
if (cpumask_test_cpu(cpu, hctx->cpumask)) { // cpu is set in cpumask
__blk_mq_run_hw_queue(hctx); //运行hardware queue
put_cpu();
return;
}
put_cpu();
}
kblockd_schedule_delayed_work_on(blk_mq_hctx_next_cpu(hctx), &hctx->run_work, 0);
}
*****************************************************************
其中__blk_mq_run_hw_queue函数描述如下:
*****************************************************************
static void __blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx)
{
struct request_queue *q = hctx->queue;
struct request *rq;
LIST_HEAD(rq_list); //初始化请求list的双向链表
LIST_HEAD(driver_list);
struct list_head *dptr;
int queued;
WARN_ON(!cpumask_test_cpu(raw_smp_processor_id(), hctx->cpumask));
if (unlikely(test_bit(BLK_MQ_S_STOPPED, &hctx->state))) //hardware queue状态判断
return;
hctx->run++;
/*
* Touch any software queue that has pending entries.
*/
flush_busy_ctxs(hctx, &rq_list); //将所有标记了有请求将被该hardware queue处理的software queue的请求数据加入到rq_list中
/*
* If we have previous entries on our dispatch list, grab them
* and stuff them at the front for more fair dispatch.
*/
if (!list_empty_careful(&hctx->dispatch)) { //若当前的hardware queue不空,即还有先前的请求待处理
spin_lock(&hctx->lock);
if (!list_empty(&hctx->dispatch))
list_splice_init(&hctx->dispatch, &rq_list); //将hardware queue中先前未处理完地请求加入到rq_list前部(更公平)
spin_unlock(&hctx->lock);
}
/*
* Start off with dptr being NULL, so we start the first request
* immediately, even if we have more pending.
*/
dptr = NULL;
/*
* Now process all the entries, sending them to the driver.
*/
queued = 0;
while (!list_empty(&rq_list)) {
struct blk_mq_queue_data bd;
int ret;
rq = list_first_entry(&rq_list, struct request, queuelist); //获得请求
list_del_init(&rq->queuelist); //删除该请求
bd.rq = rq;
bd.list = dptr; //初始化一个链表
bd.last = list_empty(&rq_list);
//初始化mq data,并判断是否还有请求待处理
ret = q->mq_ops->queue_rq(hctx, &bd); //将当前请求请求数据加入到scsi queue中并返回相关结果
switch (ret) {
case BLK_MQ_RQ_QUEUE_OK:
queued++;
continue;
case BLK_MQ_RQ_QUEUE_BUSY:
list_add(&rq->queuelist, &rq_list); //当前无法加入到hardware queue中则重新放回rq_list
__blk_mq_requeue_request(rq); //重新设定该请求的某些参数等
break;
default:
pr_err(“blk-mq: bad return on queue: %d\n”, ret);
case BLK_MQ_RQ_QUEUE_ERROR:
rq->errors = -EIO;
blk_mq_end_request(rq, rq->errors);
break;
}
if (ret == BLK_MQ_RQ_QUEUE_BUSY) //说明当前hardware queue正忙,则不再加入请求
break;
/*
* We’ve done the first request. If we have more than 1
* left in the list, set dptr to defer issue.
*/
if (!dptr && rq_list.next != rq_list.prev)
dptr = &driver_list;
}
if (!queued) //没有请求加入hardware queue
hctx->dispatched[0]++;
else if (queued < (1 << (BLK_MQ_MAX_DISPATCH_ORDER – 1)))
hctx->dispatched[ilog2(queued) + 1]++;
/*
* Any items that need requeuing? Stuff them into hctx->dispatch,
* that is where we will continue on next queue run.
*/
if (!list_empty(&rq_list)) {
spin_lock(&hctx->lock);
list_splice(&rq_list, &hctx->dispatch); //若当前还有请求在rq_list中,则将这些请求重新放回dispatch queue中,等待下次处理并且避免丢失
spin_unlock(&hctx->lock);
/*
* the queue is expected stopped with BLK_MQ_RQ_QUEUE_BUSY, but
* it’s possible the queue is stopped and restarted again
* before this. Queue restart will dispatch requests. And since
* requests in rq_list aren’t added into hctx->dispatch yet,
* the requests in rq_list might get lost.
*
* blk_mq_run_hw_queue() already checks the STOPPED bit
**/
blk_mq_run_hw_queue(hctx, true); //说明当前hardware queue正忙,则调用该函数进行异步处理,交由kblocked处理
}
}
*****************************************************************
经过上述过程,请求已经接下来将进入到scsi层中,而该blk_mq_ops中的queue_rq函数在drivers/scsi中被注册为scsi_queue_rq:
*****************************************************************
static struct blk_mq_ops scsi_mq_ops = {
.map_queue = blk_mq_map_queue,
.queue_rq = scsi_queue_rq, //注册queue_rq为scsi_queue_rq
.complete = scsi_softirq_done,
.timeout = scsi_timeout,
.init_request = scsi_init_request,
.exit_request = scsi_exit_request,
};
*****************************************************************
在scsi_queue_rq函数中,请求将会被转化为scsi command,然后进一步发送到底层driver中。
scsi_queue_rq函数描述如下:
*****************************************************************
static int scsi_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd) //在scsi这层中进行处理来自于hardware queue中的请求
{
struct request *req = bd->rq;
struct request_queue *q = req->q;
struct scsi_device *sdev = q->queuedata;
struct Scsi_Host *shost = sdev->host;
struct scsi_cmnd *cmd = blk_mq_rq_to_pdu(req);
int ret;
int reason;
ret = prep_to_mq(scsi_prep_state_check(sdev, req)); //判断当前scsi支持的设备是否有效能够处理请求
if (ret)
goto out;
ret = BLK_MQ_RQ_QUEUE_BUSY;
if (!get_device(&sdev->sdev_gendev))
goto out;
if (!scsi_dev_queue_ready(q, sdev))
goto out_put_device;
if (!scsi_target_queue_ready(shost, sdev))
goto out_dec_device_busy;
if (!scsi_host_queue_ready(q, shost, sdev))
goto out_dec_target_busy;
if (!(req->cmd_flags & REQ_DONTPREP)) {
ret = prep_to_mq(scsi_mq_prep_fn(req));
if (ret)
goto out_dec_host_busy;
req->cmd_flags |= REQ_DONTPREP;
} else {
blk_mq_start_request(req);
}
if (sdev->simple_tags)
cmd->flags |= SCMD_TAGGED;
else
cmd->flags &= ~SCMD_TAGGED;
scsi_init_cmd_errh(cmd); //错误处理
cmd->scsi_done = scsi_mq_done;
reason = scsi_dispatch_cmd(cmd); //发送cmd到底层driver
if (reason) {
scsi_set_blocked(cmd, reason);
ret = BLK_MQ_RQ_QUEUE_BUSY;
goto out_dec_host_busy;
}
return BLK_MQ_RQ_QUEUE_OK;
out_dec_host_busy:
atomic_dec(&shost->host_busy);
out_dec_target_busy:
if (scsi_target(sdev)->can_queue > 0)
atomic_dec(&scsi_target(sdev)->target_busy);
out_dec_device_busy:
atomic_dec(&sdev->device_busy);
out_put_device:
put_device(&sdev->sdev_gendev);
out:
switch (ret) {
case BLK_MQ_RQ_QUEUE_BUSY:
blk_mq_stop_hw_queue(hctx); //若当前设备正忙,则停止hardware queue的下发工作
if (atomic_read(&sdev->device_busy) == 0 &&
!scsi_device_blocked(sdev))
blk_mq_delay_queue(hctx, SCSI_QUEUE_DELAY);
break;
case BLK_MQ_RQ_QUEUE_ERROR:
/*
* Make sure to release all allocated ressources when
* we hit an error, as we will never see this command
* again.
*/
if (req->cmd_flags & REQ_DONTPREP)
scsi_mq_uninit_cmd(cmd);
break;
default:
break;
}
return ret;
}
**********************************************************

