作者 Hunger就是杭哥
SSDFans前段时间提及一篇论文:《Flash Reliability in Production:The Expected and the Unexpected》,文中提出了大量颠覆性、令人匪夷所思的观点,对我们很多以前的常识具有非常强的冲击力(正如《原来你是这样的Flash》中所说:眼镜碎了一地)。论文中有不少崭新的观点对我们SSD从业者具有很好的指导意义,也不乏有部分疑点具有进一步讨论研究的价值,以下将对其中四个问题,分享下Hunger对其的理解和解释。
一、Bit翻转总是超出ECC纠错能力?
如下图标黄部分,原文中作者提及:read过程中发生的错误很少是用户不可见的(直译拗口,意思就是大部分是用户可见的),因为这些bit错误量超出了ECC纠错能力,read retry也不行。还补充到:read errors(read retry OK的)的数量是非常少的,只有少于2%的盘和少于2~8/十万盘天受到影响。

这就很奇怪了,如果ECC对于日常大多数的bit错误都无法纠正的话,不禁让人怀疑设置ECC本身的目的何在?为什么作者能得出这样一个结论呢,我们看下面作者给出的errors统计表。
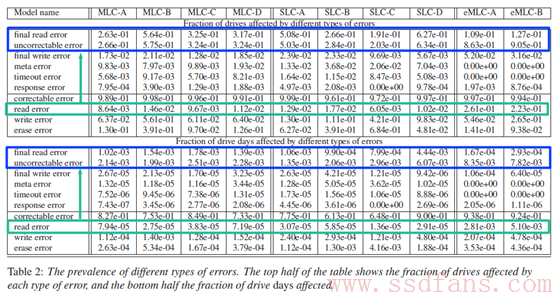
表中蓝色框内为read过程中用户可见错误的统计,青色框内为可通过read retry纠正的错误。纵向对比,我们可以看出,read errors(青色框)比其他用户可见错误基本要小2个数量级,看起来作者似乎就是通过这样的比较,得出了”Read过程中大部分时候的bit翻转都超出了ECC纠错能力”的结论的。
但是Hunger注意到,根据作者在前文中对所有错误的定义分类,read过程中用户不可见的错误除了”read errors”,还有另外一种”correctable errors”(即read ECC errors)。为了便于直观理解,下面给出作者对各种错误的定义分类图示:
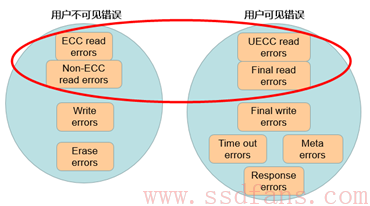
上图中红色框中的4种错误类型均发生在read过程中,我们再到最开始的errors统计表中查找ECC errors(即correctable errors),不难发现:ECC errors的数量比read过程中其他两种用户可见错误要高出2个数量级!
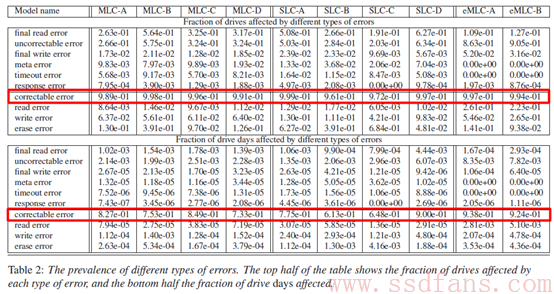
因此Hunger认为,原文此处应该是作者在分析read相关错误时疏忽,忘记了还有自己前文定义的correctable errors了。另外,观察这几组数据可以发现另一个有趣的现象,就是当errors跟ECC无关时,”read errors(retry后OK)”的数量基本只有”final read errors(retry多次后依然错误)”的不到十分之一,甚至不到百分之一。所以Hunger认为,此处结论可以这么讲:
1、实际应用中,read过程中发生的问题,绝大多数是部分bit翻转导致,并且可通过ECC纠正回来;
2、实际应用中,在遇到跟ECC无关的read errors中,绝大部分时候无法通过read retry拯救;
二、RBER:你究竟是直的还是弯的?
原文中最具认知冲击力的观点,莫过于”RBER并不像学者们研究的那样呈指数增长,而更接近于非常缓慢的线性增长(见下图)”。难道学者们这么多年的研究都错了吗?但是这篇论文的数据基础看起来也都非常权威可靠呀,这又是怎么回事呢?
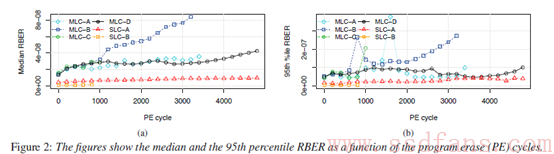
对于RBER的增长曲线,究竟是直是弯,其实上诉两种观点可以说都没有错。在讨论这个问题前,有必要先区分两个概念:Flash的自然生命期和用户生命期。
这里借用故障率常用的”浴盆曲线”图来进行说明,很多产品的自然生命期,包含早期失效期、偶然失效期和损耗失效期三个阶段。如果产品在用户使用过程中,出现了不论是早期的失效期还是最终的损耗失效期,都是非常不好的体验。因此无论是Flash厂商还是SSD厂商,都会在早期通过测试筛选等手段,尽量让产品脱离这个”夭折期”。
那么损耗失效期如何规避呢?最简单的方法就是将承诺给用户的使用寿命,定义在进入损耗失效期之前。于是最终用户看到的产品生命期,则变成了下图绿色括号的范围:
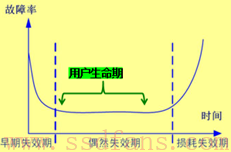
正如在《原来你是这样的Flash(3)》中提及:厂商们会将P/E cycle定义在进入损耗失效期前的三分之一处。尽管做法非常保守,但也正因如此,才能让用户更加放心地使用其产品!
所以,如果你要问RBER它是直是弯?它会这样告诉你:我命本弯,但我只会将我最直的一面呈现给我的用户们。
三、Read disturb该不该对RBER负责?
在《原来你是这样的Flash》一文中,曾提到一点:”Read的次数会影响RBER,Program和Write不会”。但是对应的图表却显示出:无论是read、write还是erase的统计情况,其跟RBER的Spearman相关系数规律都几乎一模一样(见下图)。于是Hunger到原文中一探究竟,发现事情却大不简单。
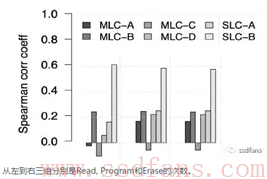
先交代下背景,我们通常认为bit发生错误是由以下4种机制之一导致的:
1、retention errors:数据保持过程中电荷丢失;
2、read disturbs:读操作对附近单元的电荷造成干扰;
3、write disturb:写操作对附近单元的电荷造成干扰;
4、incomplete erase:擦除动作不够彻底。
后面3种机制直接关系到workload,于是论文作者希望搞清楚workload跟RBER是否存在某些关联机制。与此同时,论文中还提到有一份其他学者的研究表明:实际应用中bit errors主要是retention errors,相比之下read disturb的影响是几乎可以忽略不计的。但是论文作者最开始的数据显示出,某些model的SSD,read、write和erase三者都是与RBER明显相关的:
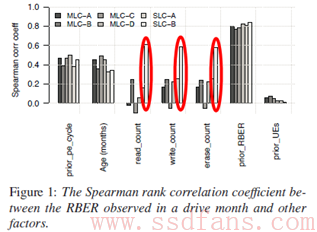
但排除一些干扰因素后,发现其实write和erase跟RBER也没什么关系了(修正后的相关系数图作者就没有贴出来了);再排除一些干扰因素后,发现还是有些model的SSD的read跟RBER相关;再再排除一些干扰因素外,又只剩一款SSD(SLC-B)的read跟RBER相关了。
所以严格来讲,read count会明显影响到RBER的只是为数不多的个例情况。并且论文作者在前面也说了,已经有其他学者研究过,认为read disturb本身对RBER没多大影响了,而作者自己在一步步的排除干扰过程中,workload跟RBER相关的现象也一点点地被证明是假象,直到最后仅存的论据SLC-B和它的read,作者也并不能解释其中缘由。那么会不会连最后剩下的SLC-B,其实还是由其他作者没有考虑到的干扰因素导致的,而非read count本身导致的呢?期待更多的资料和解释。
四、UBER六亲不认?
暂不说很多跟RBER关联的因素都跟UBER不关联,仅仅只是”UBER跟RBER没什么关系”这一句结论,估计能呛死不少学者。因为理论上来讲,UBER就是RBER经过ECC后剩下的不可纠正误比特率,相当于RBER是一堆沙石,ECC是筛子,而UBER就是筛掉沙子后剩下的石头。那么现在突然说能筛出多少石头,跟原来那堆沙石的情况无关,确实让人难以理解。
下面两张图是作者认为UBER跟RBER无关的理由,分别是不同model SSD的UBE(左图)和单model SSD的UBE(右图)情况。其中左图随着RBER的增长,UBE基本看不出有增长的趋势,而右图作者表示数据过于杂乱无章,没办法找到一条曲线来进行拟合描述。
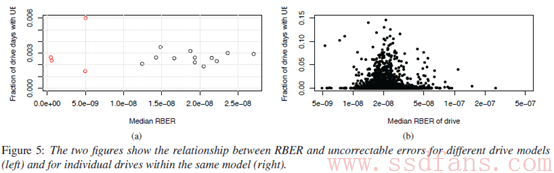
那么,究竟是大家一直以来的”信仰”错了,还是作者的数据图错了呢?其实Hunger认为,二者均没错,错的是对数据图的解读方式。
首先看如下左图,Hunger不是很精确地划了一条水平拟合直线,可以看出不同model和RBER的SSD,UBE都普遍为0.0025盘天左右。本文样本盘大多为480GB,假设每个出现UE的盘天其UE数为1(多于1的概率我们认为太低可忽略),按照平均每天读写一遍全盘,则UBER=0.0025/(480*10^9*8)=6.51e-16,结果正好与JESD218B对于企业级SSD的UBER统一标准1e-16数量级相当,所以看起来这些UBE的数据还是挺合理的。
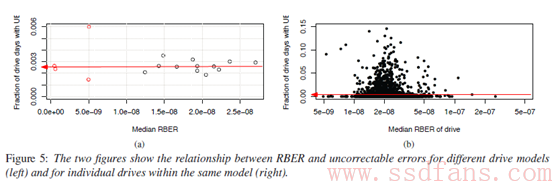
至于为什么UBE不随横坐标RBER变化呢?我们回想论文作者早前抛出的一个结论:在作者的统计样本中,RBER接近于非常缓慢的线性增长。也就是说,作者其实是把前面RBER-P/E cycle图里变化量很小的纵坐标因变量,放到上图中将比例尺拉大作为横坐标自变量来使用了。看起来好像UBE不随RBER一起变大,实则RBER自身就变化不大。就像对于一个只能筛出比黄豆大的石头的筛子,你往沙堆里再掺一些比绿豆还小的小碎石,是基本增加不了最后筛出的石头总数的。
至于右图,仔细看会发现,其纵坐标值虽然和左图一样,但选取的比例尺却相差甚远。从左图可以看到,UBE的中位数大概都处于0.0025盘天上下,而0.0025在右图中的什么位置呢——Hunger画了一条大致的示意线,如上右图红色线所示。也就是说,表面看所有的数据点都呈现一种”炸开”的状态,但实际上因为做图比例尺的关系,有一半的数据点重叠在了红线下方看不到。当然,最主要的导致UBE没有一种跟随横坐标一起变化的原因,Hunger认为是因为SSD的RBER本身变化范围还不够大,大部分时候的bit错误都能被ECC纠正,只有偶然比较集中的bit错误造成了一些UBE,这个阶段UBE本身就还是偏向于偶然发生,没有规律的。
关于RBER和UBER的概念和关系,”阿呆哥哥的马甲”曾在其新浪博客里科普过(传送门http://blog.sina.com.cn/s/blog_679f93560101e5tv.html),在理解这两者的理论关系后,再联系论文的所有统计数据都基于”所有的实验数据本身就处于Flash非常平缓的偶然失效期内”这个前提,其实论文后面不少关于其他因素跟UBER的讨论就没那么难理解了。
可以想象一个画面,论文作者问到UBER:你怎么跟什么都没关系?
还在打着酱油的UBER一脸吃惊:已,已经该有关系吗?

