作者 唐杰
说到内存,这个是大家都绕不过去的话题,和做企业存储的厂家聊天的时候,说起了现在的NVMe SSD的RAID性能太差,不管是博通的三模式,还是Intel的VMD, 在做稍微复杂的RAID5/6的时候,性能都很锉; 人家立马说我的RAID5性能刚刚的,当时心里一紧,难道自己这么快被拍在沙滩上了(本人在LSI做了至少两年的SSD RAID的性能优化,实在是对不起大部分RAID的用户,那东西的RAID5写放大忒大了)? 人家接着说,我机头上有512G的内存!!! 博通和Intel的内存都是1-2G。
这就是存储系统一路追随Intel的现状,大家等着Intel扩内存控制器,内存厂家上大容量DRAM,什么东西都放DRAM。直到现在,内存厂家开始集体收割。
我在CNCC2017 的数据中心存储论坛上看到了阿里云盘古2.0的系统架构师吴结生的一些方向性思考,深以为然。
数据通路和控制通路的分离, 这个应该是存储系统”戒”内存的出路。在过去从GSM,到3G,4G,以及未来5G的通讯业中,他们就大致遵循了这个原则,数据通路尽可能使用硬件,控制通路在各种CPU上。

作为存储系统,主要目的是以低成本的方式给自己的客户尽可能提供存储资源。在NVMeoF的时代,前面是RDMA的网络,后面是NVMe的PCIE的网络,这个是很大topic。数据中心的大王Intel之前做过一个产品,FlexPipe,希望在一个片子上集成Ethernet和PCIE。这个是Intel的RSA架构的核心思想,通过集成机架内两种主要的Fabric来实现对Rack架构的解构以及优化。

大家可以看到,这个芯片的计划很宏伟,最后也是无奈放弃,这个也可能是Intel在25G Ethernet市场上没有作为的原因。
在NVMeoF的时代,当大家再次面临这个需求的时候,也再次想到了使用硬件加速的方案,和上次相比,这次的需求更清晰。
Xilinx在一开始做NVMeoF加速的时候,首先想到也是offload数据搬移,尽可能使数据通路不用通过CPU。将NVMe SSD连接在FPGA上,通过PCIE Switch和RDMA的网卡利用PCIE的P2P功能进行通讯。
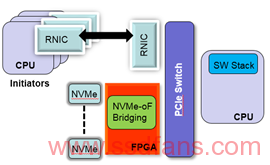
在这个架构中,数据直接从NVMe出发被push到RDMA的QPs中, NVMe的CQ/SQ以及数据传输的Buffer都在FPGA上的Block RAM中,数据不用和传统的X86架构一样,需要把数据从NVMe上搬移到主机的DRAM中,然后再通过RDMA的QPs 发送。
这个架构里面,我们遇到几个问题:
- P2P的性能问题,100G的RNIC的PCIE接口是Gen3 X 16, PCIE SW的P2P的性能是有上限的。
- 客户不买单,这个系统的东西太多,虽然数据链路在FPGA上,主机不需要太多内存(可是,内存在2016年上半年还没有上涨)。因此成本和收益不明显。
-
大部分客户的想法还是Samsung一样,我大不了加CPU和内存, 反正用全闪的人都不差钱。Samsung为了达到2.25M的IOPS,使用了quad-socket Xeon E7-8890 v4 server , populated with 512GB DDR4 memory。【1】 反正内存都是自家,可劲造。
Xilinx下一步怎么走,的确是一个问题?

