作者 唐杰
我们在开篇的第一部分中提及了目前的存储厂商全闪产品的架构,基本还是X86存储的机头+SAS SSD +JBOD 扩展。在2016年的时候,也有一些存储厂商,包含OCP的Facebook都推出过一些NVMe的存储盘阵,但是基本上都没有规模部署,其中除了成本较高以外,还存在一个重要的技术原因, PCIE的扩展性。
在大部分全闪的存储系统中,大家都采用X86 存储机头服务器,通过SAS cable进行级联JBOD,无论是使用SAS HDD,或者SAS SSD,大家通过传统的SAS switch进行存储资源的scale out,这个是目前性价比最高,也是最健壮的一种扩展方式。
当存储厂商开始部署NVMe SSD的时候,他们使用了PCIE switch来替代SAS Switch,使用PCIE的HBA来替换SAS HBA,不知道有多少读者见过PCIE 的HBA card。这个扩展卡和传统的HBA不同,直接连接在CPU里面的Root Port上。

这种使用方式,连国内PLX PCIE switch最大的用户都认为,PCIE switch的使用成本太高,而且系统的稳定性挑战比较大,因为PCIE switch环境下的error 的隔离非常重要,否则就有可能和TeraData的集群一样面临可能性的问题。
随着NVMeoF的出现,使用100G Ethernet来代替PCIE成为互联接口变成可能,在传统的使用磁盘阵列进行扩展的场景下,100G带来的可用性优势明显。因此,在2017年7月,pure storage推出了他的下一代设计,基于NVMeoF的存储扩展框FlashArray //X。【1】
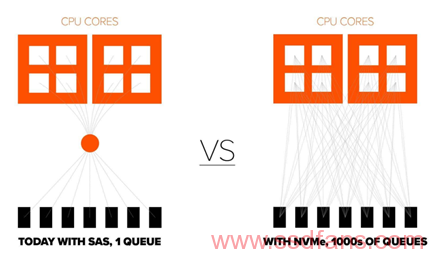
因此,可以预见,未来的企业存储的架构会使用100G Ethernet进行扩展并提供服务。
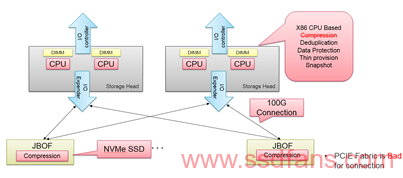
同时,因为全闪阵列带来的两个必须的功能,压缩和去重,从而是X86的CPU在对外提供服务的同时有了更大的workload,不止一个存储厂商在考虑使用硬件进行压缩的实现。
对于未来的存储系统, 相信大家会沿着NVMe 取代SCSI协议的路上越走越宽,还是用Alibaba盘古2.0的系统架构师的一个展望来结束这个系列吧。
“Microsecond-Scale Era”


