作者 唐杰
作为芯片行业的各位吃瓜群众,都知道在2016年中发生的一个新闻,ITRS (International Technology Roadmap for Semiconductors)说话了,2015年的路线图应该是最后一代的了,作为以硅为载体的半导体行业终于走到了尽头【1】。也就是5nm之后,就没有以后,这个是从1993年以来的遇到若干次”假”终点的真终点。
在吃了若干年的摩尔定律的红利之后,大家第一次发现底层的硬件已经无以为继了。在计算机体系结构方面的多年的争论目前也算有了明确的答案。在计算机演进的过程中,是制造的工艺起主要作用,还是指令集自身的进化。对,就是Intel著名的tick-tock进程。
在制造工艺无以为继的情况下,大家的押宝开始偏向tock了。于是连Intel也在2016年宣布,tick-tock从2年的周期变成3年。原因在下图很清晰:
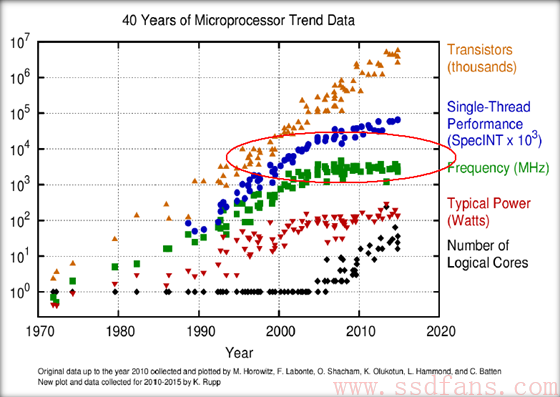
可以很清楚的看到,从2004年左右开始,虽然摩尔定律仍然在提高芯片的密度,但是性能已经上不去了,其中的原因就是主频遇到了瓶颈。大家走向了多核这条路。
在多核的架构下,大家自然在考虑如何提高每个core的利用率,这个条路,Intel在数据中心已经走了快10年了,大家发现自己的手机也在走这条路。如何走好这条路,已经有人做了理论准备。Jason Cong (丛京生)教授领导的异构计算在2009年拿了美帝$10,000,000的基金做customized computing【2】。这个一千万美金的结论也很简单明了。
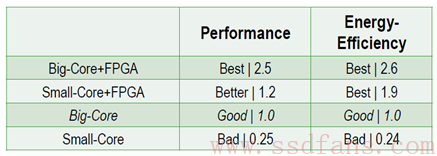
其中,Big-Core是Intel的X86,或者IBM的Power,以及数据中心ARM (Big Arm); Small-Core算是mobile ARM, 在指定的workload下面,单纯的ARM肯定不行,希望在手机上挖矿的童鞋可以歇歇了,这个理论上不靠谱。大core可以自己玩,就像Intel目前在数据中心的状态一样,自己玩,把AVX【3】这种SIMD加进来,使用自己各种优化的库。
丛教授真正推荐是混合计算,对于数据中心的业务,使用Big-Core+FPGA这种方式可能是未来的方向。于是,就有了Intel在2015年的收购Altera。
确定了方向之后,问题就来了,如何连接Big-Core和FPGA,这里面,Intel在收购完成之后给大家做了总结。
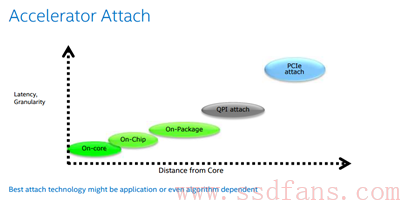
大家在上一篇很清楚,Intel选择了在QPI这层连接FPGA加速器,因为有了自己的小甜甜,就关起门了过日子了。这下,剩下的人就不愿意了,如果数据中心只有一个CPU供应商,群众是不答应的。
因此大家都纷纷搞起了加速器互联的方案,有基于PCIE的,如CCIX、OpenCAPI, 也有基于Ethernet的 (Gen-Z),当然,ARM阵营还有自己的CCI。大家的方案不同,但是出发点是一致的,就是开放,尽可能联合市场上能活下来的玩家。

