作者 唐杰
话说上篇已经讲明了未来计算发展的趋势,就是异构计算。对于异构计算,给大家举一个例子,比如我们要算(2+3)的40次方,我们会先用脑子加一下,然后在计算器上直接计算5的40次方,对,这就是混合计算。目前的通用处理器都是冯诺依曼的架构,在计算上面相对于哈弗架构【1】的通用DSP还是有性能上的差距。
回到现在主流的应用,在大数据概念大行其道的时候,大家都在发愁这样的数据量放在数据中心中到底有啥用,使用传统的BI实在勉为其难。但是没多久,大家发现了,原来大数据的最好的归宿是Deep Learning,简称人工智能。其中的因果,如果想不花力气搞清楚的,请参考吴军老师的《数学之美》【2】,这本讲的很清楚,而且作为跨行业和学术的人士,把数学理论和实践相结合了。
因此,大家对数据中心的存储技术进行了短暂的关注之后,迅速地转向了计算。层次不穷的计算框架,神经网络,连计算机届的A类会议 “ISCA”在2016年被改成了” International Symposium on Convolutional neural network Architecture“。
面临各种不断出现的计算需求,大家很快意识到通用的CPU不合适,因此目光很快投向了各种加速器。目前主流的加速器主要是:
- GPGPU,老黄家的基本占领了离线的培训。和按摩店的东西比,N记的CUDA实在是实力太强。
- FPGA,Xilinx和Intel/Altera各有一家在在线的搞得很火。主打的就是performance/W的概念。
- ASIC, 就是专用芯片,比如Google的TPU,还有Intel最近收购的。当然还有计算所的DaDianNao. 在这块,ASIC的优势和劣势都明显。成本有优势,灵活性是劣势,毕竟现在算法还在不停的变化,每家上线的应用的算法都各有不同,而且都是核心价值,不能外泄,因此在数据中心里面,ASIC的商业模式还不清楚。
对于这几种加速器来看,他们的目标是一致的,就是从通用处理器获得数据,进行自己擅长的计算,然后返回。如何传递数据的问题和如何计算的问题变得一样重要了。传统的数据通道是PCIE,但是很快大家意识到PCIE根本扛不住。作为最简单的AlexNet的全连接层,最合理的数据带宽都是100GB/s左右的,因此在早期,很多人会把全连接层放在CPU上就是因为PCIE太low。这里PCIE也很委屈,因为DDR4同样也扛不住,这就是目前Xilinx和Intel在FPGA上放HBM2【3】的原因。HBM就是高带宽的memory,自己去看吧。
现在的需求很清楚了:
- 需要异构计算
- 需要大带宽的数据传输
- 需要尽可能减低交换的延时。
作为FPGA市场上的老大,Xilinx因此和数据中心的CPU的供应商站出来,推出了CCIX (Cache Coherence Interconnect),作为加速器的厂家,Xilinx希望能够通过一个标准的协议和各种架构的处理器,从ARM到Power,到X86。
对于Cache Coherence,如果大家不想关心太多,就可以这样理解,它是基于一种状态机,在多个CPU之间维护CPU cache的一致性,在OS上的进程在CPU之间进行切换的时候,不需要考虑cache数据的操作。这些都是硬件自动帮你搞定。
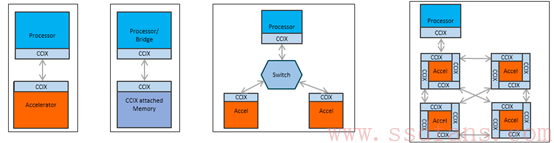
从上图的4个场景,CCIX的功能也很清楚。第一个是提供加速功能,通过CCIX和CPU进行数据的交互。第二个就和之前的讨论关系更大了,提供更多的存储器资源,通过CCIX连接,可以降低延时。对于3和4,给大家的概念就是这个不是P2P的协议,CCIX可以支持Switch功能,进行组网。图4的FPGA的加速器池是俺最看好的方向。
具体的技术规格,大家都可以在网站上看到了。主要的亮点是:
- 利用了PCIE的底层的PHY
- 抛弃了PCIE的协议层以及DMA和中断机制。这个DMA和中断机制是增加延时的万恶之源。Intel的DPDK就是受不了中断,直接上手polling了。
- 和现有的PCIE的兼容性,因此可以很快在现有的16nm的FPGA上实现对CCIX和PCIE4.0的支持。再次发挥FPGA快速的优势,希望可以在2017年看到部署。
我对CCIX给予厚望的另一个原因是,我天朝的骄子,Huawei Hisilicon也在创始公司的名单上。华为的ARM已经在手机上很成功了,走向数据中心肯定是必须的。
最后,做一句广告,如果有对CCIX有兴趣的厂家,欢迎和俺联系。

