Ceph是最近出现的一个分布式文件系统,最初是Sage Weil 在 University of California, Santa Cruz(UCSC)的PhD研究内容。目前Inktank公司掌控Ceph的开发,但Ceph是开源的,遵循LGPL协议。功能越来越完善。
我们知道一般企业使用3中存储:
- 对象存储
- 文件存储
- 块设备存储
Ceph同时支持这三种,还有高扩展性、高可靠性、高性能的优点,这三个特点也是企业级存储需要的。
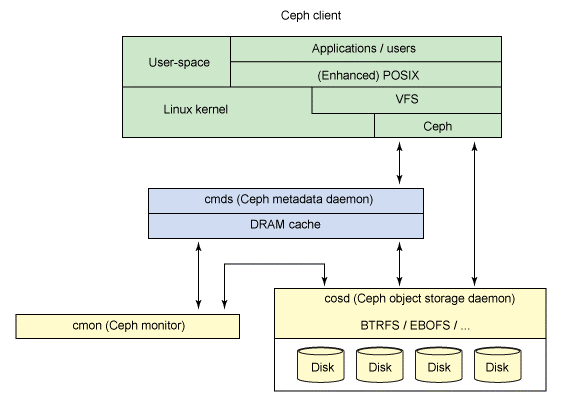
下图为Ceph的架构,Ceph Client 是 Ceph 文件系统的用户。Ceph Metadata Daemon 提供了元数据服务器,而 Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。最后,Ceph Monitor 提供了集群管理。
下图是Ceph的写流程。用户文件作为Object先映射到PG(Placement Group),再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD,第一个OSD是Primary,剩下的都是Replicas。从PG分配到OSD使用了一种伪随机算法CRUSH。
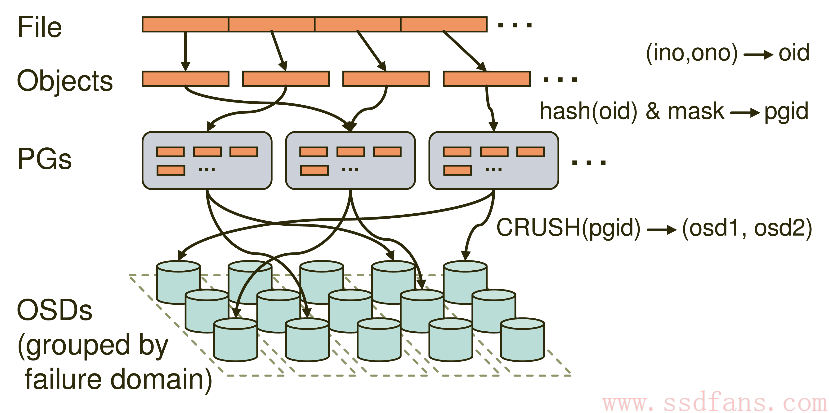
这种数据映射的优点是:
1. 把Object分成组,这降低了需要追踪和处理metadata的数量(在全局的层面上,我们不需要追踪和处理每个object的metadata和placement,只需要管理PG的metadata就可以了。PG的数量级远远低于object的数量级)。
2. 增加PG的数量可以均衡每个OSD的负载,提高并行度。
3. 分隔故障域,提高数据的可靠性。
当Primary收到Object的写请求时,它负责把数据发送给其他Replicas,只要这个数据被保存在所有的OSD上时,Primary才应答Object的写请求,这保证了副本的一致性。

OSD之间有心跳检测,当OSD A检测到OSD B没有回应时,会报告给Monitors说OSD B无法连接,则Monitors给OSD B标记为down状态,并更新OSD Map。当过了M秒之后还是无法连接到OSD B,则Monitors给OSD B标记为out状态(表明OSD B不能工作),并更新OSD Map。然后自动开始故障恢复。
由上可以得出Ceph的三个优点:
- 高扩展性。没有单个中心控制组件。所有负载都能动态的划分到各个服务器上。把更多的功能放到OSD上,让OSD更智能。当组件发生故障时,自动进行数据的重新复制。当组件发生变化时(添加/删除),自动进行数据的重分布。
- 高可靠性。有多个副本,能自动检测故障并恢复。
- 高性能。Client干的活少了,存储server更智能。多个OSD并发,这个应该是读的时候吧,写的时候那么多副本,应该很慢了。写那么多,性能估计高不到哪里去。只不过对服务器来说,写的操作还是少的。
所以还是前两个优点更突出。
我们来看看www.ustack.com网站测的性能,机器配置很强悍,Ceph副本数为2,块1M。可以看出,只有在24个磁盘时随机读性能比较好,因为有多个OSD并行。其他顺序读写和随机写都不高。当然后面评论也说了,分布式系统和单机系统比吞吐率有点欺负人。
| 磁盘数 | 随机写 | 随机读 | ||||
| Ceph | RAID10 | 性能比 | Ceph | RAID10 | 性能比 | |
| 24 | 1075 | 3772 | 28% | 6045 | 4679 | 129% |
| 12 | 665 | 1633 | 40% | 2939 | 4340 | 67% |
| 6 | 413 | 832 | 49% | 909 | 1445 | 62% |
| 4 | 328 | 559 | 58% | 666 | 815 | 81% |
| 2 | 120 | 273 | 43% | 319 | 503 | 63% |
| 磁盘数 | 顺序写(MB/s) | 顺序读(MB/s) | ||||
| Ceph | RAID10 | 性能比 | Ceph | RAID10 | 性能比 | |
| 24 | 299 | 879 | 33% | 617 | 1843 | 33% |
| 12 | 212 | 703 | 30% | 445 | 1126 | 39% |
| 6 | 81 | 308 | 26% | 233 | 709 | 32% |
| 4 | 67 | 284 | 23% | 170 | 469 | 36% |
| 2 | 34 | 153 | 22% | 90 | 240 | 37% |
本文综合以下文章完成:

